




1 什么是hash join
嵌套循环只适用在连接数据量小的情况,如果有上百万数据需要连接,那么就可能需要对内表做上百万次的索引范围扫描,导致内表的很多数据块被重复扫描,而且,索引范围扫描如果需要扫描超过5%的数据很可能就比全表扫描的性能还差了。
实际应用中,这种大数据量的连接是普遍存在的,尤其在后台job和数据分析中,这时候就该考虑应用hash连接了。下面是一个hash连接的实例。下面通过这个例子来说明hash连接的过程。
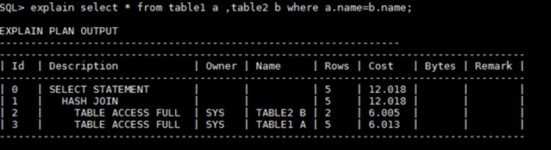
(1)选择一个表在内存中使用连接列生成hash表
这个表就是选择的驱动表(上例中为b表,执行计划中显示在上面),由于需要在内存(PGA)中生成hash表,所以选择数据集较小的表为驱动表较好。如果内存中放不下这个hash表,那么就需要放到临时表空间中,如果临时表空间也满了,那么就会报错了。
这个步骤一般需要全表扫描驱动表,或者说需要连接的数据集。那么,不管另一个表有没有数据,这个全表扫描都是必须做的。
(2)全表扫描探测表,查询hash表
当驱动表生成了hash表后,遍历另一个表(也叫探测表),对探测表的每一条数据使用连接列的值到hash表中匹配,如果匹配上将对应数据保存到结果集中,直到查询结束。
如果hash表没有全部放在内存中,那么探测表就需要遍历多次,分别对hash表的多个分区做连接。
(3)输出hash结果
hash连接结束就得到了连接结果,跟索引扫描不同,hash连接一般是不需要再访问表的,所以hash连接对表的扫描一般是全表扫描或快速全索引扫描。
2 hash连接使用场景总结
hash连接是非常常用的连接方式,它有以下特点:
(1)适用于较大数据集的连接,并且连接条件必须是等值连接。
(2)尽量选择小的数据集作为驱动表在内存中生成hash表。
(3)设置一个较大的PGA可以加快hash连接的速度,避免使用临时表空间。
(4)多表连接时同样要注意连接顺序,中间结果集尽量小,少做无用功。
hash连接相对与嵌套循环,它实际上是通过空间来换取时间,因为它需要保存hash表,占用较大的内存,在临时表空间不足的情况下是可能报错的,而嵌套循环一般不会报错,但可能非常慢。
