

master和slave都会不断累加offset
slave会每秒上传自己的offset,master也会保存每一个slave的offset
slave和master都知道各自的offset,才知道各自数据不一致的情况
master node有一个backlog默认是1MB,
master node给slave复制数据时也会给把backlog同步一份,
backlog主要用来做全量复制中断的时增量复制的
1.从节点使用psync到maser node,进行复制,psync run id
2.master node根据自身情况进行响应,可能是FULLRESTYNC run id offset,也可能是CONTINUE触发增量复制
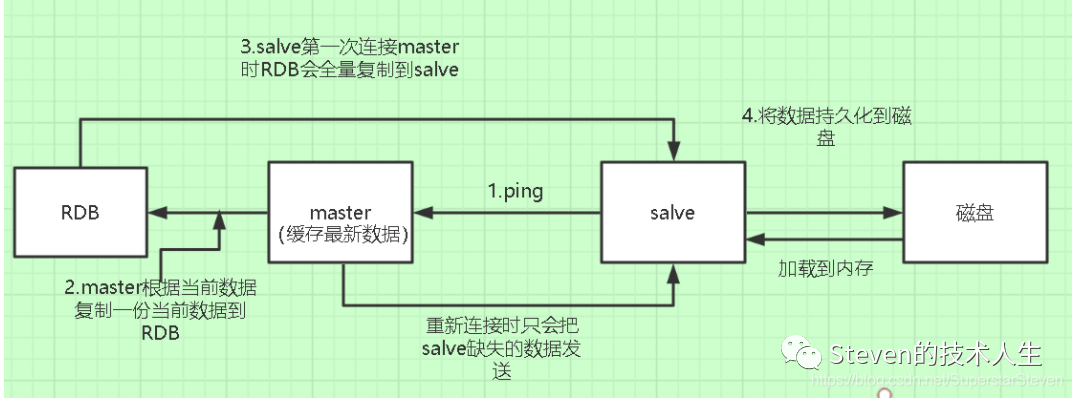
1.master 执行BGSAVE,在本地生成RDB快照master node会将RDB快照文件发送给slave node,如果RDB在复制过程中时间超过60s(repl-timeout),slave-node会认为复制失败,可以适当调大复制时间参数(repl-timeout)
2.对于千兆网卡的机器来说1s传输100MB,6G时间可能超过60s
1.master node生成RDB时,会将所有的命令缓存到内存中,在slave node保存rdb后,再将新的命令复制到slave node中
2.client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间内存缓冲区消耗超过64MB,或一次性超过256MB则复制失败
3.slave node在接收到rdb后会清空自己的旧数据,然后重新加载rdb到自己内存中,同时基于旧的数据提供服务
4.如果slave node开启了AOF会立即执行BGRERITEAOF,重写AOF
如果复制数据在4-6G之间,很可能全量复制的时间在1.5-2分钟
1.如果在全量复制的过程中master-slave网络断掉,salve node在重新连接master node时会触发增量复制
2.master 直接从backlog获取部分丢失数据,发送给slave node,默认backlog是1MB
3.master会根据slave发送的psync中的offset获取数据
1.主从节点相互发送heartbeat信息
2.master每隔10s发送一次heartbeat信息,slave每隔1s发送一次heartbeat信息
(8)异步复制
master接收到命令后在内部写入,异步发送给slave node
1.master直接在内存中创建RDB,然后发送给slave不会落到本地磁盘
repl-diskless-sync no
2.等待一段时间在开始复制因为要等待更多的slave连进来
repl-diskless-sync-delay 5
4.Redis过期策略
(1)定期删除+惰性删除
1.每个100ms检查key是否过期如果过期则删除
2.惰性删除可能会导致很多过期的key没有被删除,如果查询时到某个key过期则删除
(2)redis内存淘汰策略
1.noeviction:当内存不足以容纳新的数据时,写入操作就会报错
2.allkeys-lru:当内存不足以容纳新的数据时,就会淘汰最近最少使用的key
3.allkeys-random:当内存不足以容纳新的数据时,就会随机删除key
4.volatile-lru:当内存不足以容纳新的数据时,在过期key删除中删除最近最少使用的
5.volatile-ttl:当内存数据不足以容纳新的数据时,删除那些即将过期的key
5.redis哨兵的多个核心底层原理的深入解析(包含slave选举算法)
1.sdown和odown转换机制
1.1sdown是主观宕机,一个slave觉得自己的master宕机了就是主观宕机
1.2odown是客观宕机,如果quorum的数量的哨兵觉得maser宕机了就是1.3客观宕机,sdown达成条件很简单,如果一个哨兵ping master超过了is-master-down-after-milliseconds指定毫秒数就认为master宕机了
sdown到odown的转换条件比较简单,如果一个哨兵在指定时间内也收到quorum的数量的哨兵觉得是sdown宕机,那么就认为是odown,客观认为master宕机
2.哨兵和slave的自动发现机制
哨兵之间相互发现通过pub/sub系统实现,每个两秒钟哨兵都会监控自己的master+slaves对应的_sentinel_:hello channel发送消息,内容主要是hos、IP、run id还有master对应的监控配置,感知同样监听master+slaves哨兵的存在,哨兵间还会交换master监控配置,实现监控配置的同步
slave配置的自动纠正
哨兵模式会负责纠正slave的一些配置,比如slave要成为master的潜在候选人,哨兵会确保slave会复制master现有的数据,如果slave连接到一个错误的master上故障转移后哨兵会保证它连接到正确的master

目前100000+人已关注加入我们