





本文首发于Ressmix个人站点:https://www.tpvlog.com
前两章,我实现了epay-cache
服务的基本功能,包括本地JVM缓存、Redis缓存以及Kafka通知。但是,遗留的一个问题始终没有解决——如何进行缓存的重建?本章,我就对缓存重建存在的问题和解决方案进行讲解,代码保存在Gitee: 6.缓存重建(https://gitee.com/ressmix/epay/tree/master/6.%E7%BC%93%E5%AD%98%E9%87%8D%E5%BB%BA),需要的读者可以下载阅读。
首先,我们来回顾下哪些场景涉及到缓存的重建:
缓存服务对外暴露的http接口:当客户端请求查询商品基本信息或店铺信息时,如果Redis缓存和JVM缓存中都不存在,就会调用源服务的接口获取,然后重建缓存;
Kafka消费者客户端:当收到源服务的数据变动通知后,调用源服务的接口获取,然后重建缓存。
一、缓存重建
1.1 场景
缓存服务对外暴露的http接口:
当客户端请求查询商品基本信息或店铺信息时,如果Redis缓存和JVM缓存中都不存在,就会调用源服务的接口获取,然后重建缓存:
1@Controller
2public class CacheController {
3
4 @Autowired
5 private CacheService cacheService;
6
7 private static final Logger LOG = LoggerFactory.getLogger(CacheController.class);
8
9 /**
10 * 获取商品基本信息
11 *
12 * @param productId
13 * @return
14 */
15 @RequestMapping("/getProductInfo")
16 @ResponseBody
17 public ProductInfo getProductInfo(@RequestParam("productId") Long productId) {
18 ProductInfo productInfo = null;
19
20 // 1.从Redis查找商品基本信息
21 productInfo = cacheService.getProductInfoFromReidsCache(productId);
22 LOG.info("=================从redis中获取缓存,商品信息=" + productInfo);
23
24 if (productInfo == null) {
25 // 2.从本地JVM缓存查找
26 productInfo = cacheService.getProductInfoFromLocalCache(productId);
27 LOG.info("=================从ehcache中获取缓存,商品信息=" + productInfo);
28 }
29
30 if (productInfo == null) {
31 // TODO: 从源服务请求数据,重建缓存
32 }
33
34 return productInfo;
35 }
36
37 /**
38 * 获取店铺信息
39 *
40 * @param shopId
41 * @return
42 */
43 @RequestMapping("/getShopInfo")
44 @ResponseBody
45 public ShopInfo getShopInfo(@RequestParam("shopId") Long shopId) {
46 ShopInfo shopInfo = null;
47
48 // 1.从Redis查找店铺信息
49 shopInfo = cacheService.getShopInfoFromReidsCache(shopId);
50 LOG.info("=================从redis中获取缓存,店铺信息=" + shopInfo);
51
52 if (shopInfo == null) {
53 // 2.从本地JVM缓存查找
54 shopInfo = cacheService.getShopInfoFromLocalCache(shopId);
55 LOG.info("=================从ehcache中获取缓存,店铺信息=" + shopInfo);
56 }
57
58 if (shopInfo == null) {
59 // TODO: 从源服务请求数据,重建缓存
60 }
61
62 return shopInfo;
63 }
64}
Kafka消费者客户端:
当收到源服务的数据变动通知后,调用源服务的接口获取最新数据,然后重建缓存。
1@Component
2public class CacheIntegrationConsumer {
3
4 @Autowired
5 private CacheService cacheService;
6
7 private static final Logger LOG = LoggerFactory.getLogger(CacheIntegrationConsumer.class);
8
9 @KafkaListener(topics = {"product-topic"}, groupId = "product-group")
10 public void consumeProduct(ConsumerRecord<Integer, String> record) {
11 LOG.info("接收到商品服务通知: {}", record);
12 String data = record.value();
13
14 // 提取出商品id
15 Long productId = Long.valueOf(data);
16
17 // 调用商品基本信息服务的接口,获取最新数据
18 // 生产环境一般RPC调用,这里直接注释模拟
19 String productInfoJSON = "{\"id\": 1,\"productId\": 1000, \"name\": \"iphone7手机\", \"price\": 5599, \"pictureList\":\"a.jpg,b.jpg\", \"specification\": \"iphone7的规格\", \"service\": \"iphone7的售后服务\", \"color\": \"红色,白色,黑色\", \"size\": \"5.5\", \"shopId\": 15, \"modifiedTime\": \"2020-01-01 12:00:00\"}";
20 ProductInfo productInfo = JSONObject.parseObject(productInfoJSON, ProductInfo.class);
21
22 // TODO:重建本地缓存和Redis缓存
23 cacheService.rebulidCache(productInfo);
24 }
25
26 @KafkaListener(topics = {"shop-topic"}, groupId = "shop-group")
27 public void consumeShop(ConsumerRecord<Integer, String> record) {
28 LOG.info("接收到店铺服务通知: {}", record);
29 JSONObject jsonObject = JSONObject.parseObject(record.value());
30
31 // 提取出店铺id
32 Long shopId = jsonObject.getLong("shopId");
33
34 // 调用店铺服务的接口
35 // 生产环境一般RPC调用,这里直接注释模拟
36 String shopInfoJSON = "{\"id\": 1,\"shopId\": 15, \"name\": \"小王的手机店\", \"level\": 5, \"goodCommentRate\":0.99, \"modifiedTime\": \"2020-01-01 13:00:00\"}";
37 ShopInfo shopInfo = JSONObject.parseObject(shopInfoJSON, ShopInfo.class);
38
39 // TODO:重建本地缓存和Redis缓存
40 cacheService.rebulidCache(shopInfo);
41 }
42}
1.2 问题
我们来思考下,上述两种场景下如果我们直接更新JVM缓存和Redis缓存会出现什么问题?
生产环境下,如果JVM和Redis中都找不到缓存数据,一般是在缓存失效的那一瞬间,比如缓存过期了或者被LRU算法清除了。由于生产环境通常会部署多个对等节点,那么缓存失效后可能有很多请求会同时进行缓存重建,这会造成两个问题:
大量请求同时调用源服务接口(涉及数据库)获取数据,然后重建缓存。比如某一个商品可能一瞬间并发过来数千个查询请求,如果不做控制,每个请求都要去重建缓存,非常低效,而且对源服务形成很大的压力,容易引发“缓存风暴”(关于缓存风暴,我后面会进行专门章节讲解);
缓存的脏写问题:比如A请求发现缓存中没数据,就调用源服务请求最新数据(假设数据快照为X),然后准备更新到缓存(但还没有更新);此时源服务进行了另外一些数据变更(假设数据快照为Y),Kafka消费者收到通知后,进行了缓存重建,将缓存中的数据更新成了快照Y;由于A请求执行得慢了点,最后才完成缓存的更新,将缓存更新成了快照X。事实上,此时数据库中的最新数据为快照Y,而缓存中却变成了快照X,出现了数据不一致。
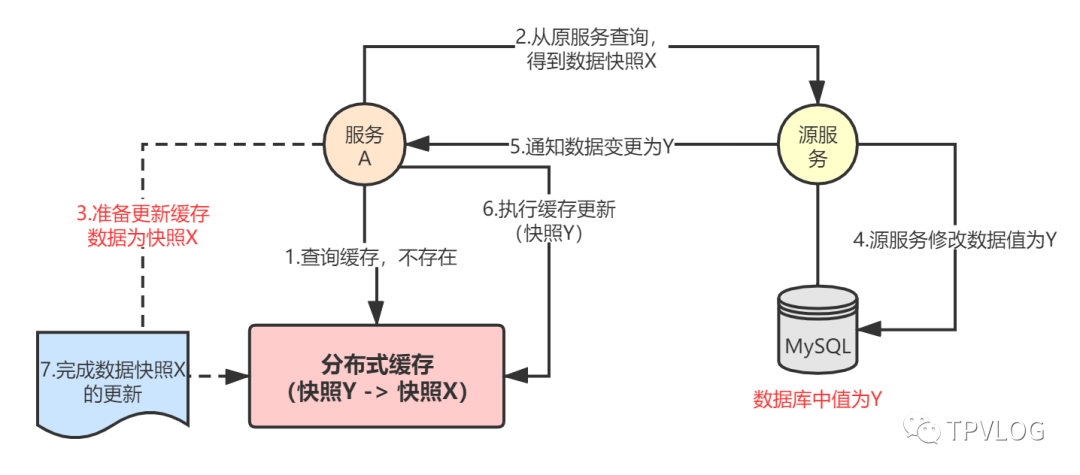
上述第二个问题,与我们之前讲解的数据库与缓存的双写一致性问题非常类似,本质都是高并发场景下,同时读写缓存和数据库引发的数据一致性问题,但还是有些区别:
双写一致性的Cache Aside模式中,写请求和读请求都是由一个入口处理,而本章的缓存重建场景是数据库中的值已经被其它服务先进行了修改。
二、Zookeeper分布式锁
针对缓存重建可能引发的问题,我们生产环境一般会采用分布式锁+版本号的方式来解决,以重建商品基本信息的缓存为例,基本思路如下:
Kafka消费者进行缓存重建时,先尝试获取商品id对应的分布式锁;
拿到锁之后,将缓存中数据的时间版本与待更新数据的时间版本比较,如果待更新的版本新于缓存中的版本就更新,否则不更新;
如果拿不到分布式锁,就轮询等待一段时间,超时后还未获取到锁则返回;
缓存服务对外暴露的http查询接口,先去源服务获取数据,然后推送一条缓存重建消息到Kafka,接着立马返回从源服务得到的数据。
Kafka消费者会异步消费消息,进行缓存重建。
2.1 基本配置
由于前面章节我们已经搭建好了Zookeeper集群,本节我们就来看看如何实现基于ZK的分布式锁。
关于Zookeeper实现分布式锁的原理,读者可以参考我的这篇文章:Zookeeper分布式锁。另外,本章实现的Zookeeper分布式锁非常简单,但能满足基本需求,因为我的目的主要是讲解整体架构设计思路,基于Zookeeper的复杂分布式锁实现,读者可以自行参考Github上的开源代码。
首先,我们引入Curator这个开源Zookeeper客户端的maven依赖:
1<dependency>
2 <groupId>org.apache.curator</groupId>
3 <artifactId>curator-framework</artifactId>
4 <version>4.3.0</version>
5</dependency>
6<dependency>
7 <groupId>org.apache.curator</groupId>
8 <artifactId>curator-recipes</artifactId>
9 <version>4.3.0</version>
10</dependency>
然后在application.properties
加上一些ZK的基本配置:
1#zookeeper地址
2zookeeper.curator.connectString=192.168.0.107:2181,192.168.0.109:2181,192.168.0.110:2181
3#客户端尝试连接ZK的重试次数
4zookeeper.curator.retryCount=3
5#客户端尝试连接ZK的重试间隔时间
6zookeeper.curator.elapsedTimeMs=5000
7#客户端session超时时间,超时后临时节点会被自动删除
8zookeeper.curator.sessionTimeoutMs=60000
9#客户端尝试连接ZK的连接超时时间
10zookeeper.curator.connectionTimeoutMs=5000
Java配置类:
1@Configuration
2@ConfigurationProperties(prefix = "zookeeper.curator")
3public class ZookeeperConfig {
4 private Integer retryCount;
5 private Integer elapsedTimeMs;
6 private String connectString;
7 private Integer sessionTimeoutMs;
8 private Integer connectionTimeoutMs;
9
10 public Integer getRetryCount() {
11 return retryCount;
12 }
13
14 public void setRetryCount(Integer retryCount) {
15 this.retryCount = retryCount;
16 }
17
18 public Integer getElapsedTimeMs() {
19 return elapsedTimeMs;
20 }
21
22 public void setElapsedTimeMs(Integer elapsedTimeMs) {
23 this.elapsedTimeMs = elapsedTimeMs;
24 }
25
26 public String getConnectString() {
27 return connectString;
28 }
29
30 public void setConnectString(String connectString) {
31 this.connectString = connectString;
32 }
33
34 public Integer getSessionTimeoutMs() {
35 return sessionTimeoutMs;
36 }
37
38 public void setSessionTimeoutMs(Integer sessionTimeoutMs) {
39 this.sessionTimeoutMs = sessionTimeoutMs;
40 }
41
42 public Integer getConnectionTimeoutMs() {
43 return connectionTimeoutMs;
44 }
45
46 public void setConnectionTimeoutMs(Integer connectionTimeoutMs) {
47 this.connectionTimeoutMs = connectionTimeoutMs;
48 }
49
50 @Bean(initMethod = "start")
51 public CuratorFramework curatorFramework() {
52 return CuratorFrameworkFactory.newClient(
53 connectString,
54 sessionTimeoutMs,
55 connectionTimeoutMs,
56 new RetryNTimes(retryCount, elapsedTimeMs));
57 }
58}
Zookeeper分布式锁工具类:
1/**
2 * ZooKeeperLock
3 * 通过在 /lock 根路径下竞争创建临时节点来模拟排它锁。以下情况锁会被释放:
4 * 1.当前获取锁的客户端发生宕机,那么ZooKeeper服务器上保存的临时性节点就会被删除;<br>
5 * 2.当前获取锁的客户端正常执行完业务逻辑,客户端主动来将自己创建的临时节点删除。
6 *
7 * @author ressmix
8 */
9@Service
10public class ZooKeeperLock implements InitializingBean {
11
12 private final static String ROOT_PATH_LOCK = "distributed_lock";
13
14 private static final Logger LOG = LoggerFactory.getLogger(ZooKeeperLock.class);
15
16 @Autowired
17 private CuratorFramework curatorFramework;
18
19 /**
20 * 获取InterProcessMutex对象(可重入的公平排它锁)
21 *
22 * @param type
23 * @param key
24 * @return
25 */
26 public InterProcessMutex getMutex(LockType type, String key) {
27 String keyPath = "/" + ROOT_PATH_LOCK + "/" + type.getKey() + "/" + key;
28 return new InterProcessMutex(curatorFramework, keyPath);
29 }
30
31 /**
32 * 创建父节点,作为永久节点
33 */
34 @Override
35 public void afterPropertiesSet() {
36 String path = null;
37 try {
38 for (LockType type : LockType.values()) {
39 String key = type.getKey();
40 path = "/" + ROOT_PATH_LOCK + "/" + key;
41 if (curatorFramework.checkExists().forPath(path) == null) {
42 LOG.info("创建分布式锁根节点:{}", path);
43 curatorFramework.create()
44 .creatingParentsIfNeeded()
45 .withMode(CreateMode.PERSISTENT)
46 .withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
47 .forPath(path);
48 }
49 }
50 } catch (Exception e) {
51 LOG.error("创建分布式锁根节点失败:{}", path, e);
52 }
53 }
54}
2.2 被动重建
我们先来看下Kafka消费者端接受到通知后利用ZK分布式锁重建缓存,以商品信息为例。
1@Override
2public void rebulidCache(ProductInfo productInfo) {
3 // 获取分布式锁
4 InterProcessMutex lock = zooKeeperLock.getMutex(LockType.PRODUCT, String.valueOf(productInfo.getProductId()));
5 boolean isLocked = false;
6 try {
7 // 超时10s
8 isLocked = lock.acquire(10000, TimeUnit.MILLISECONDS);
9 if (isLocked) {
10 //获取成功
11 doRebulidCache(productInfo);
12 } else {
13 LOG.error("尝试获取分布式锁失败,productId={}", productInfo.getProductId());
14 }
15 } catch (Exception e) {
16 LOG.error("获取分布式锁异常,productId={}", productInfo.getProductId(), e);
17 } finally {
18 if (isLocked) {
19 try {
20 lock.release();
21 } catch (Exception e) {
22 LOG.error("释放分布式锁异常,productId={}", productInfo.getProductId(), e);
23 }
24 }
25 }
26}
27
28private void doRebulidCache(ProductInfo productInfo) {
29 // 先从缓存查找是否存在数据
30 ProductInfo redisCache = getProductInfoFromReidsCache(productInfo.getProductId());
31 ProductInfo jvmCache = getProductInfoFromLocalCache(productInfo.getProductId());
32
33 // 重建Redis缓存
34 if (validateDate(productInfo, redisCache)) {
35 saveProductInfo2ReidsCache(productInfo);
36 }
37
38 // 重建JVM缓存
39 if (validateDate(productInfo, jvmCache)) {
40 saveProductInfo2LocalCache(productInfo);
41 }
42}
43
44private boolean validateDate(ProductInfo newData, ProductInfo cacheData) {
45 if (cacheData == null) {
46 return true;
47 }
48
49 // 比较当前数据的时间版本比已有数据的时间版本是新还是旧
50 try {
51 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
52 Date date = sdf.parse(newData.getModifiedTime());
53 Date existedDate = sdf.parse(cacheData.getModifiedTime());
54
55 if (date.before(existedDate)) {
56 LOG.info("待更新的数据日期[{}]早于缓存中的数据日期[{}],不进行更新",
57 newData.getModifiedTime(), cacheData.getModifiedTime());
58 return false;
59 }
60 } catch (Exception e) {
61 LOG.info("解析数据日期异常", e);
62 return false;
63 }
64
65 return true;
66}
上述比较关键的一点是:需要比较缓存中的数据版本与待更新的数据版本哪一个最新,如果缓存中的最新,则忽略本次缓存重建。
2.3 主动重建
我们再来看下缓存服务对外暴露的http接口,当接受到请求后,如果缓存中没有数据,则主动重建缓存。还是以商品基本信息为例:
1/**
2 * 获取商品基本信息
3 *
4 * @param productId
5 * @return
6 */
7@RequestMapping("/getProductInfo")
8@ResponseBody
9public ProductInfo getProductInfo(@RequestParam("productId") Long productId) {
10 ProductInfo productInfo = null;
11
12 // 1.从Redis查找商品基本信息
13 productInfo = cacheService.getProductInfoFromReidsCache(productId);
14 LOG.info("=================从redis中获取缓存,商品信息=" + productInfo);
15
16 if (productInfo == null) {
17 // 2.从本地JVM缓存查找
18 productInfo = cacheService.getProductInfoFromLocalCache(productId);
19 LOG.info("=================从ehcache中获取缓存,商品信息=" + productInfo);
20 }
21
22 if (productInfo == null) {
23 // 从源服务请求数据,这里直接模拟
24 String productInfoJSON = "{\"id\": 2,\"productId\": 1666, \"name\": \"iphone7手机\", \"price\": 5599, \"pictureList\":\"a.jpg,b.jpg\", \"specification\": \"iphone7的规格\", \"service\": \"iphone7的售后服务\", \"color\": \"红色,白色,黑色\", \"size\": \"5.5\", \"shopId\": 16, \"modifiedTime\": \"2020-01-01 18:00:00\"}";
25 productInfo = JSONObject.parseObject(productInfoJSON, ProductInfo.class);
26
27 // 异步重建缓存
28 try {
29 kafkaTemplate.send("product-topic", String.valueOf(productId));
30 } catch (Exception ex) {
31 LOG.error("发送重建缓存消息失败", ex);
32 }
33 }
34
35 return productInfo;
36}
我这里直接通过Kafka来实现缓存的异步重建,往product-topic
这个主题里扔了一个异步通知消息,那Kafka消费者端收到消息后,就会重建缓存。
我这里为了简便起见直接复用了Kafka通知消费者来进行缓存重建,读者可以自己实现JVM内存队列来处理,或者另外搞一个topic专门来处理“主动重建”这种情况。
三、总结
本章,我对分布式环境下缓存失效导致的缓存风暴和缓存重建问题进行了讲解,并给出了使用Zookeeper分布式锁来解决这个问题的方案。下一章,我将讲解三级缓存架构中的最后一层——Nginx缓存。
