





如果有序集合包含较多的元素,或者元素是较长的字符串时(具体阈值会在下文分析),redis 就会使用跳跃表作为有序集合(sorted set)键的底层实现。但是 sorted set 底层不仅使用了 skip list,还使用了 zip list 和 dict。
1 sorted set 样例
sortet set 其实就是 redis 的 zset 数据结构。
127.0.0.1:6379> zadd grade 98 Chinese(integer) 1127.0.0.1:6379> zadd grade 97 Math(integer) 1127.0.0.1:6379> zadd grade 97 English(integer) 1127.0.0.1:6379> OBJECT encoding grade"ziplist"127.0.0.1:6379> zadd grade 95 VeryLongSubjectName1111111111111111111111111111111111111111111111111111111111111111111111111(integer) 1127.0.0.1:6379> OBJECT encoding grade"skiplist"127.0.0.1:6379> zrange grade 0 -1 withscores1) "VeryLongSubjectName1111111111111111111111111111111111111111111111111111111111111111111111111"2) "95"3) "English"4) "97"5) "Math"6) "97"7) "Chinese"8) "98"127.0.0.1:6379> zrevrange grade 0 -1 withscores1) "Chinese"2) "98"3) "Math"4) "97"5) "English"6) "97"7) "VeryLongSubjectName1111111111111111111111111111111111111111111111111111111111111111111111111"8) "95"127.0.0.1:6379> zscore grade English"97"127.0.0.1:6379> ZREVRANK grade Chinese(integer) 0127.0.0.1:6379> ZREVRANGEBYSCORE grade 100 97 withscores1) "Chinese"2) "98"3) "Math"4) "97"5) "English"6) "97"
grade 有序集合的所有数据保存在一个跳跃表里,其中每个跳跃表节点都保存了一门课程的分数, 从低到高在跳跃表里排序:
zadd 命令用于往 sorted set 插入成员和分值
如果分值相同,将成员的值按照字符串比较大小,虽然 Math 和 English 的分值相同,但是 M 大于 E,所以 Math 比 English 高
zrange 由低到高排序
zrank/zrevrank (升序/降序)查询指定成员的排名
zscore 查询指定成员对应的分数
zrevrange 根据排名范围,由高到低排序
zrevrangebyscore 查询指定分数期间内的数据集合
2 跳跃表的基本原理
skiplist 可以翻译为跳跃表,简称跳表,是一种可实现高效查找的特殊数据结构,解决查找问题的数据结构还有平衡树或者哈希表。在大部分情况下,跳跃表的效率与平衡树差不多,并且跳跃表的实现比平衡树简单。
跳跃表的详细介绍如下链接所示:
https://github.com/wxdyhj/data-struct-go/blob/master/skip_list/skip_list.md
3 redis skiplist 的实现
但是,根据上述跳跃表的实现,跳跃表不能支持以下命令:zrank/zzrevrank, zscore, zrange/zrevrange, zrangebyscore/zrevrangebyscore。所以在 redis 中,sorted set 有两种实现方式:
当数据较少时,sorted set 使用一个 ziplist 实现
当数据较多,或者元素是较长的字符串时,sorted set 一个由 dict 和 一个 skiplist 实现,dict 存储数据到分数的对应关系,skiplist 可用于根据分数条件的查询。
redis 的跳跃表由 server.h 文件中的 zskiplistNode 和 zskiplist 结构体定义,zskiplistNode 表示 跳跃表节点,zskiplist 用于保存跳跃表节点的相关信息,比如节点的数量,最大层数,头尾指针。
3.1 跳跃表节点(zskiplistNode)
// redis-6.0.5/src/server.h#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 *//* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode { // 跳跃表节点sds ele; // 成员对象,ele 应该是 element 的缩写double score; // 各个节点对应的分值,在跳跃表中,节点按分值从小到大排序struct zskiplistNode *backward; // 后退指针struct zskiplistLevel { // 层struct zskiplistNode *forward; // 前进指针unsigned long span; // 跨度} level[];} zskiplistNode;
ZSKIPLIST_MAXLEVEL 定义最大层数为 32
ZSKIPLIST_P 定义创建上一层的概率为 0.25
3.1.1 成员(ele)
节点 element 成员,是一个 sds 对象,用于存储成员的值。在同一跳跃表中,各个节点保存的成员对象是唯一的,即 ele 存储的值不能重复。
3.1.2 分值(score)
节点的分值是一个 double 类型的浮点数,跳跃表中的所有节点都按照分值从小到大排序。在同一跳跃表中,各个节点保存的分值可以相同,分值相同的节点按照成员对象在字典序中的大小来进行排序, 成员对象较小的节点会排在前面(靠近表头的方向)。
3.1.3 后退指针(backward)
用于从表尾向表头方向访问节点,只能顺序往前遍历。
3.1.4 层(level)
跳跃表节点的 level 数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过 level 数组实现跨越访问其他节点的元素,一般来说,层数越多,访问其他节点的速度越快。
创建跳跃表的时候,程序以 0.25 的概率向上创建一层,最终随机生成一个[0,32] 之间的值作为 level 数组的大小,该数组的长度就是层数,即层的高度。因为 c 语言的数组索引以 0 开始,所以第一层是 level[0],第二层是 level[1],以此类推,第 32 层是 level[31]。
3.1.5 前进指针(forward)
每一层都有一个指向表尾方向的前进指针,即level[i].forward,用于从表头向表尾方向访问。
3.1.6 跨度(span)
level[i].span 表示层的跨度,用于记录两个节点之间的距离。在 redis 中应用于计算 rank,即排位。在查找某个节点的过程中,将访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。
两个节点之间的跨度越大,之间跳过的节点就越多
指向 null 的所有前进指针的跨度都为 0,因为他们没有指向任何节点
3.2 跳跃表(zskiplist)
// redis-6.0.5/src/server.htypedef struct zskiplist {struct zskiplistNode *header, *tail; // 表头节点和表尾节点unsigned long length; // 跳跃表包含的节点数量int level; // 表中层数最大的节点的层数} zskiplist;
zskiplist 结构体分析:
header:指向跳跃表的表头节点的指针
tail:指向跳跃表的表尾节点的指针
length:跳跃表的长度,即跳跃表包含的节点数量(不包含表头节点)
level:当前跳跃表中层数最多的节点的层数(不算表头节点的层数)
3.3 图解 redis 跳跃表
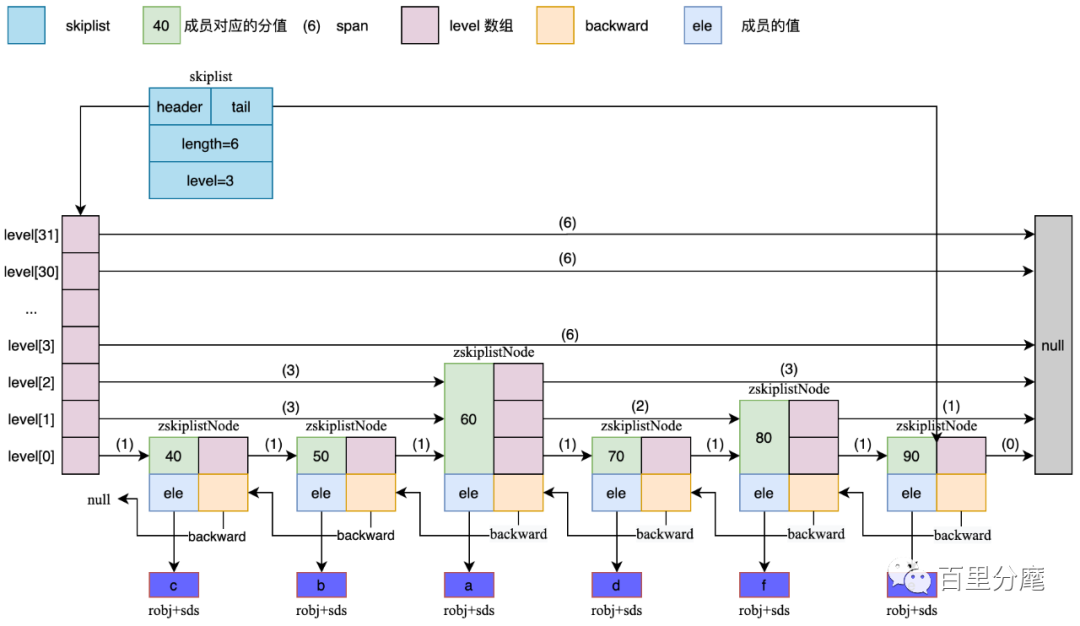
假设在上述跳跃表中查找分值为 80 (其对应的成员为 f)的 rank(即 zrank 命令的结果),查找过程如下:
在从 level[2] 的第一个元素开始比较,由于 80 > 60,所以应该在 60 的右边
由于 60 的右边为 null,于是回到 level[1] 继续查找
60 在 level[1] 层链表的右边元素为 80,经比较,即为待查找的元素
上述查找过程中,经历过的 span 值为 3 和 2,于是 80 在该跳跃表中的 rank 为 (3+2-1) = 4,注意:减一是因为 rank 是从 0 开始的。如果要计算从大到小的 rank,只需要将跳跃表总长度,减去经历过的 span 值,即 (6-3-2) = 1。所以计算 rank 的时间复杂度为 O(log2(N))
3.4 常见命令分析
zscore
用法:zscore key member
功能:查询指定成员的分数
实现:由 dict 提供,并不是 skiplist 本身支持的
复杂度:由于只需查询 dict,所以时间复杂度为 O(1)
zrank/zrevrank
用法:zrank key member
功能:升序/降序查询指定成员的排名,注意:排名是从 0 到 size -1,与数组下标类似
实现:在 dict 中根据成员找出对应的分数,再根据分数找出对应的排名
复杂度:dict 查找只需 O(1),在 skiplist 找出对应排名需要O(log2(N))
zrange/zrevrange
用法:zrange key start stop [withscores]
功能:升序/降序查询指定排名范围内的成员
为了方便降序方式查找指定范围内的数据,redis 中的第 1 层是个双向链表。
4 重要参数
zset 的定义如下:
// redis-6.0.5/src/server.htypedef struct zset {dict *dict;zskiplist *zsl;} zset;
重要配置参数:
// redis-6.0.5/src/config.ccreateSizeTConfig("zset-max-ziplist-entries", NULL, MODIFIABLE_CONFIG, 0, LONG_MAX, server.zset_max_ziplist_entries, 128, INTEGER_CONFIG, NULL, NULL),createSizeTConfig("zset-max-ziplist-value", NULL, MODIFIABLE_CONFIG, 0, LONG_MAX, server.zset_max_ziplist_value, 64, MEMORY_CONFIG, NULL, NULL),
即:zset-max-ziplist-entries 的值为 128,zset-max-ziplist-value 的值为 64,其含义是:当满足以下任意条件时,sorted set 的底层数据结构会从 ziplist 转成 zset:
当有序集合(sorted set)中的元素个数超过 128 时
当有序集合(sorted set)插入的任意一个元素的长度超过 64
5 参考资料
redis-6.0.5 源码(http://download.redis.io/releases/redis-6.0.5.tar.gz)
skip list (https://github.com/wxdyhj/data-struct-go/blob/master/skip_list/skip_list.md)
Redis 设计与实现(http://redisbook.com/preview/dict/content.html)
Redis内部数据结构详解(6)——skiplist(http://zhangtielei.com/posts/blog-redis-skiplist.html)
