点击▲关注 “数据和云” 给微信标星置顶
更多精彩 第一时间直达

刘伟
刘伟,云和恩墨软件开发部研究院研究员;前微博DBA,主要研究方向为开源数据库,分布式数据库,擅长自动化运维以及数据库内核研究。
不得不承认的一点是,当前数据库的使用趋势,至少在国内,是逐渐从Oracle转向MySQL(扩大化概念的话,就是包括PG等在内的开源数据库,以及rds类的云数据库服务,后文统一以MySQL代指),但在实际的操作层面,如果涉及到现有业务改造,躲避不开的一点是,如何让现有业务平滑地从Oracle切换到MySQL.
如果把这个问题局限在DBA的范畴,不考虑应用开发的难处,处理这个问题的普遍思路是,首先把Oracle做一个一致性备份,全量导入到MySQL,然后从这个一致性的备份作为起点,对Oracle与MySQL同时进行业务操作(一般称为双写),直到某个时间点(一般是两边数据库数据同步时间差距比较小的时候),进行一次业务stop the world,然后切换过去.
在”双写”这个的处理上,就是八仙过海各显神通了.有的是在程序入口分流,通过发布订阅队列直接分开两边程序去跑,有的是在程序写入的时候,DAO层隔离上层应用后,自己直接写两边数据库.等等方式,实际上手段太多了.
而本文讨论的,则是在假设不对应用进行改造(队列化,DAO双写等)的情况下,从Oracle直接同步数据到MySQL的手段.
并且是不花钱的.
当然Oracle本体的授权必须得买,省掉的,是Oracle GoldenGate这个”下船税”.
对于并不关心全文细节的读者,建议直接翻到文章最后面,下载我写的测试脚本验证.
Logminer介绍
如果是一个MySQL DBA,那他最常用的命令行程序之一,必然有mysqlbinlog这个,查故障,数据恢复等等用处简直不要太多了.
而Oracle自带的logminer,就是Oracle世界的mysqlbinlog.主要用途,就是去分析redo日志(当然也包括归档日志),从中提取出来数据的变更,解决故障,恢复数据.
比如oracle的确是支持闪回,但具体恢复到哪个scn编号,就得需要logminer来确定了.
而本文要用的的功能,则是用这种日志分析,来处理”近”实时的数据同步问题.
Oracle作为闭源的数据库,其redo格式虽然文档中有所提及,但实际上真的去做二进制文件分析代价实在太大,这一领域最早的成功者GoldenGate转手就被Oracle收了,并且考虑到法律问题,logminer就成了上帝给开的最后一扇窗户了.
限制条件
曾经业内一位前辈说过,看技术先看限制条件,否则匆匆忙忙研究到最后,却发现自己需求没有满足,就不好了.下文是我目前整理的一些logminer的注意点,以及限制以供参考.
如果是分析非本实例产生的日志,则分析用的实例必须与日志的源实例为同一个硬件平台(注意不是操作系统),并且得是独立的实例,版本号必须等于或者大于源实例,并且数据库的字符集必须与源实例一致或者是超集(处理mysqlbinlog的字符集问题被坑一脸血的人应该对着限制深有感触).
Logminer的运行目录,仅能包含一个源数据库的redo日志,不能一个目录下混合来自多个数据库的redo日志.
所有的redo日志必须有相同的RESETLOGSSCN.并且得是8.0以上版本(部分功能得9.0.1以上版本)的Oracle产生的.
当然,最重要的,就是源数据库必须打开归档模式以及supplemental log.
在具体的数据类型以及表存储类型支持上:
不支持BFILE.
不支持ADT(抽象数据类型)
不支持集合类型的列(嵌套表或者varry类型)
不支持引用对象.
不支持使用了表压缩的表
不支持安全文件.
除了这些之外,同通常的数据类型,以及表存储类型都是支持的.
运行结构
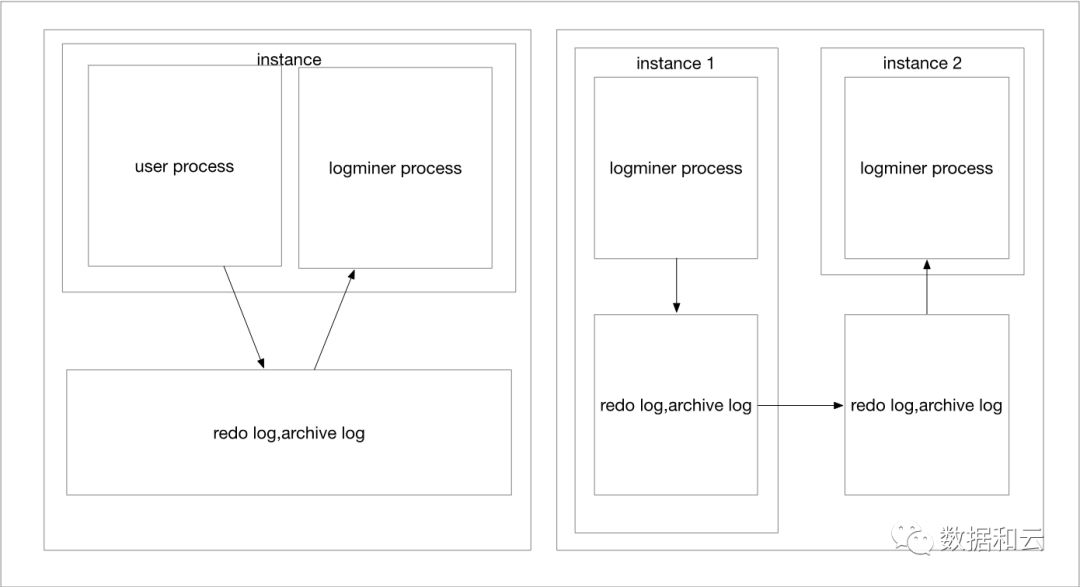
Logminer在用法上,是Oracle内置的一套PL/SQL包,因此所有的运行,都是在Oracle实例内部的,其支持两种模式,简单概括来说,一个是直接分析当前自己数据库的归档以及redo日志,另外一个,是分析其他Oracle数据库的归档以及redo日志.
操作步骤
前面说过,本文讨论的是近实时同步,当然躲不开得写程序(程序全文参考后文),而在写程序之前,先得明白的是,人工执行每个命令的话,需要怎么做.
在执行所有动作之前,需要设置归档模式以及supplemental log,但和本文主题关系不大,就不展开步骤了,网上这方面资料太多了.
就执行logminer,简单来说,有五步.
指定logminer的运行目录
添加所需要分析的日志文件进入分析队列.
启动logminer.
分析redo日志.
关闭分析会话.
以下就来详细解释每一步.
注意:下文假设操作都是在sqlplus操作.如果从程序调度,需要用begin end而非execute调用程序包.
1.指定logminer的运行目录
在决定哪个目录作为分析目录之前,首先需要决定分析期间使用的数据字典用哪个.
Logminer提供了两个选项(文档中的第三个选项flat file已经废弃,不进行多余讨论),一个是直接使用当前数据库作为数据字典来源,而另外一个,是使用独立的logminer字典.
官方有个图很好地说明了这两个选项的选择路线:
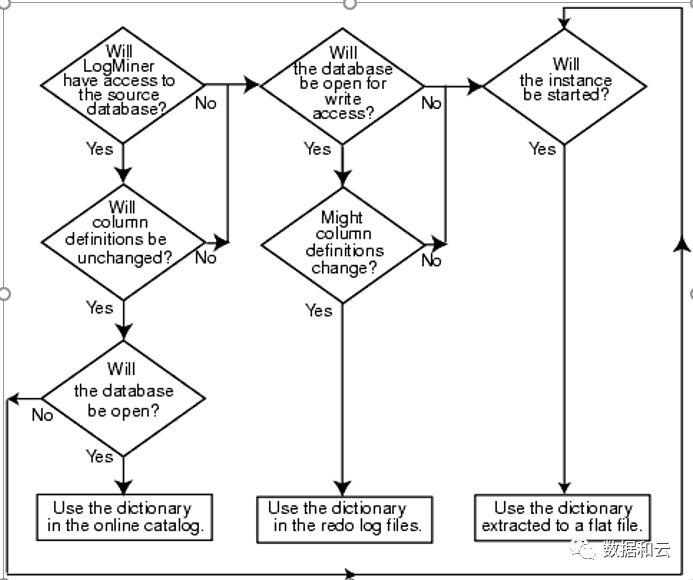
如果需要第一种:
EXECUTE DBMS_LOGMNR.START_LOGMNR(
OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG);
如果需要第二种:
EXECUTE DBMS_LOGMNR_D.BUILD(
OPTIONS=>DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);
需要注意的是,如果使用第二种方式,需要通过语句确定哪些redo日志中保存了数据字典,语句如下:
SELECT NAME FROM V$ARCHIVED_LOG WHEREDICTIONARY_BEGIN='YES';
SELECT NAME FROM V$ARCHIVED_LOG WHEREDICTIONARY_END='YES';
分析的时候,需要添加这些日志进入分析流.
第二种方式需要定时执行以同步数据字典(比方DDL变更表结构之后),需要注意,否则会导致解析识别错误.
2.添加需要分析的日志文件进入分析队列
这部分执行的,是DBMS_LOGMNR.ADD_LOGFILE这个存储过程,这个存储过程有两个参数,一个是LogFileName,一个是options.
LogFileName是将要被分析的日志的绝对路径(分析过程中实际使用的目录是启动logminer时候指定的,在此处尚未指定)
Options则是可以指定两个选项,一个是NEW,就是结束分析并开始新的分析流.
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( -
LOGFILENAME => '/oracle/logs/log1.f', -
OPTIONS => DBMS_LOGMNR.NEW);
而ADDFILE就是添加指定的redo日志到当前的分析流中.
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( -
LOGFILENAME => '/oracle/logs/log2.f', -
OPTIONS => DBMS_LOGMNR.ADDFILE);
除了这种手动人工的添加方式之外,如果logminer是分析自己数据库的日志,就可以做到自动寻找日志并进行分析,而不需要人工指定.
具体办法是,在启动logminer调用DBMS_LOGMNR.START_LOGMNR的时候,增加CONTINUOUS_MINE选项,这个选项会让logminer从所有归档日志以及redo日志中,从指定的scn或者时间开始分析日志,直到到达指定的结束scn编号,如果没有指定结束时间/scn,那么分析程序会一直维持分析状态,任何数据库实时写入的数据,都会被”近”实时地分析到(在这里,作者遇到的问题是,事务commit之后,并不会马上被分析到,而是等几分钟之后才会被分析到,目前尚未确认原因,如果有人知道,望不吝赐教).
V$LOGMNR_LOGS视图包含了当前已经添加的日志文件,包括自动发现的日志文件
3.启动logminer
终于到启动logminer,这个存储过程的参数描述如下:
DBMS_LOGMNR.START_LOGMNR (
startScn IN NUMBERdefault 0,
endScn IN NUMBERdefault 0,
startTime IN DATE default'01-jan-1988',
endTime IN DATE default'31-dec-2110',
DictFileName IN VARCHAR2 default'',
Options INBINARY_INTEGER default 0 );
抛开显而易见的start,end的四个参数,首先简单说一下dictfilename.前文提到过,为了同步元数据,需要做几个选择,如果当时选择的是第三种,也就是废弃掉的使用文件作为表元数据字典的话,就需要在这个参数指定那个文件.
Options就非常多了,我们逐个梳理下,根据实际需求选择.下面列出表格提供参考.
COMMITTED_DATA_ONLY | 如果选择了这个选项,那么就不会看到回滚或者执行中的事务生成的redo记录对应的导出内容,仅能看到提交成功的数据修改的操作记录. |
SKIP_CORRUPTION | 如果扫描期间,遇到redo内数据块(非redo头)损坏的,就直接跳过 |
DDL_DICT_TRACKING | 前文中有提到当分析的数据库是另外的数据库的话,需要使用redo或者文件存储数据字典,这个选项会在此基础上,根据redo的记录更新内部的数据字典,避免ddl执行导致的数据字典不一致的情况. |
DICT_FROM_ONLINE_CATALOG | 使用内部数据字典作为表元数据字典,仅适用于本实例分析,与DDL_DICT_TRACKING选项冲突. |
DICT_FROM_REDO_LOGS | 结合前文提到BUILD阶段的REDO存储数据字典的选项使用 |
NO_SQL_DELIMITER | 输出的SQL不包含分号,方便导出的语句可以直接执行 |
NO_ROWID_IN_STMT | 默认情况下,生成的SQL语句会包含ROW ID,对于仅关心实际数据的话,可以打开这个选项,但对于没有主键或者唯一键的表,可能会导致错误的更新 |
PRINT_PRETTY_SQL | 格式化输出的SQL,方便阅读,但不能直接用于执行 |
CONTINUOUS_MINE | 让logminer自动发现并扫描日志文件,启动程序仅需要提供scn或者日期.从Oracle 10.1开始,支持Oracle RAC环境下的日志解析,还有一个注意点,Oracle 12.2开始,这个参数转为废弃,后续可能得想别的变通办法处理这个问题. |
调用的时候,options字段,不同的选项以+连接,如下:
EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS=> -
DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG + -
DBMS_LOGMNR.COMMITTED_DATA_ONLY);
4.分析redo日志
当启动logminer之后,就可以提取分析出来的日志了,方式很简单,就是去查V$LOGMNR_CONTENTS表(需要select any dictionary权限),就可以按照顺序获取到所需要的日志解析内容了.由于原表列数量非常多,我仅提取出来几个一般会需要关注的字段,详细的描述的话,还是参考官方文档吧.
SCN | 数据库当前记录的SCN |
START_SCN | 当前事务开始的SCN,仅在COMMITTED_DATA_ONLY选项启用后有意义. |
COMMIT_SCN | 事务提交时候对应的SCN,仅在COMMITTED_DATA_ONLY选项启用后有意义. |
TIMESTAMP | 数据变更对应的操作系统时间 |
START_TIMESTAMP | 事务的开始时间,仅在COMMITTED_DATA_ONLY选项启用后有意义. |
COMMIT_TIMESTAMP | 事务的提交时间,仅在COMMITTED_DATA_ONLY选项启用后有意义. |
XID | 事务ID |
OPERATION | SQL操作,这部分内容非常多,一般需要关心的,是INSERT,UPDATE,DELETE,DDL,COMMIT,ROLLBACK, 与事务以及数据操作直接相关的 |
SEG_OWNER | 操作的数据段的拥有者,一般对应实际的表拥有者 |
SEG_NAME | 数据段名称,对应实际的表名称或者表分区等 |
TABLE_NAME | 操作的表名称 |
SEG_TYPE_NAME | 操作的段的类型,一般有表,索引以及分区等类型 |
TABLE_SPACE | 操作的数据块对应的表空间 |
ROW_ID | 操作对应的ROW ID |
USERNAME | 事务的执行者,也就是运行SQL语句的用户名称 |
SQL_REDO | 对于非临时表,此处会生成数据操作对应的SQL语句 |
SQL_UNDO | 对于非临时表,此处会生成反转操作的SQL语句,比如insert对应delete.delete对应insert,update更新新数据为老数据 |
CSF | 如果超过4000字节的SQL,则这个标记为1,表示下一行依然对应这一行的数据变更 |
SRC_CON_NAME | 使用PDB的话,此处为PDB名称 |
Oracle对这个视图的查询执行,看似是查视图,实际上对应的是对日志的顺序扫描.
因此对这个视图的select,切忌不要直接select * from之后,等拿到所有结果集再行处理,而应该以批次分段的形式处理,否则会导致连接oracle的客户端程序占用过多内存,(比如select的时候,python用fetchmany或者fetchone接口,而非fetchall).
另外就是,如果未指定stop scn/时间的话,当查到最新行的时候,sql会话会一直阻塞住,直到有下一行数据产生.
在进一步的使用上, 通过DBMS_LOGMNR.MINE_VALUE处理REDO_VALUE/ UNDO_VALUE列可以用来处理并比较修改的数据,另外一个函数COLUMN_PRESENT则可用来保证MINE_VALUE函数的计算必定非null.示例如下:
SELECT
(XIDUSN || '.' || XIDSLT || '.' || XIDSQN) AS XID,
(DBMS_LOGMNR.MINE_VALUE(REDO_VALUE, 'HR.EMPLOYEES.SALARY') -
DBMS_LOGMNR.MINE_VALUE(UNDO_VALUE, 'HR.EMPLOYEES.SALARY')) AS INCR_SAL
FROM V$LOGMNR_CONTENTS
WHERE
OPERATION = 'UPDATE' AND
DBMS_LOGMNR.COLUMN_PRESENT(REDO_VALUE, 'HR.EMPLOYEES.SALARY') = 1 AND
DBMS_LOGMNR.COLUMN_PRESENT(UNDO_VALUE, 'HR.EMPLOYEES.SALARY') = 1;
5.关闭分析会话
简单来说,就是调用DBMS_LOGMNR.END_LOGMNR函数,没有别的花巧.
Demo代码
https://pan.baidu.com/s/1BiFrrV1EyBOMTIcZT23Rkw
附件文件oracle_dumper.py,是一个基于logminer写的一个每分钟表变更行数量计算的脚本程序,作为后续编程处理的参考.文中忽略的oracle用户授权,supplementlog打开等命令均在代码注释中,提供给感兴趣的人参考.