




前言
大家好,最近在研究debezium替换ogg的事情,主要实现目标是代替ogg在割接中的作用。以下是我做的一些测试,我没有选择Docker来安装,选择使用了kafka最新的2.8kraft版。我的环境如下:
| 主机IP | 应用 |
|---|---|
| 192.168.56.130 | Oracle 12c数据库 |
| 192.168.56.170 | PostgreSQL 13.2数据库 |
| 192.168.56.170 | Kafka 2.8 |
| 192.168.56.170 | Kafka Oracle Connector |
我的kafka2.8和debezium-connector-oracle插件部署在192.168.56.170主机上。
Kafka安装
因为是测试,这里选择了最新的kafka2.8来安装。kafka2.8最大的特点就是它移除了zookeeper,采用了Quorum Controller机制。也就采用了Raft协议,节点数为奇数且大于等于3,最多可以容忍(n/2-1)个节点失败。
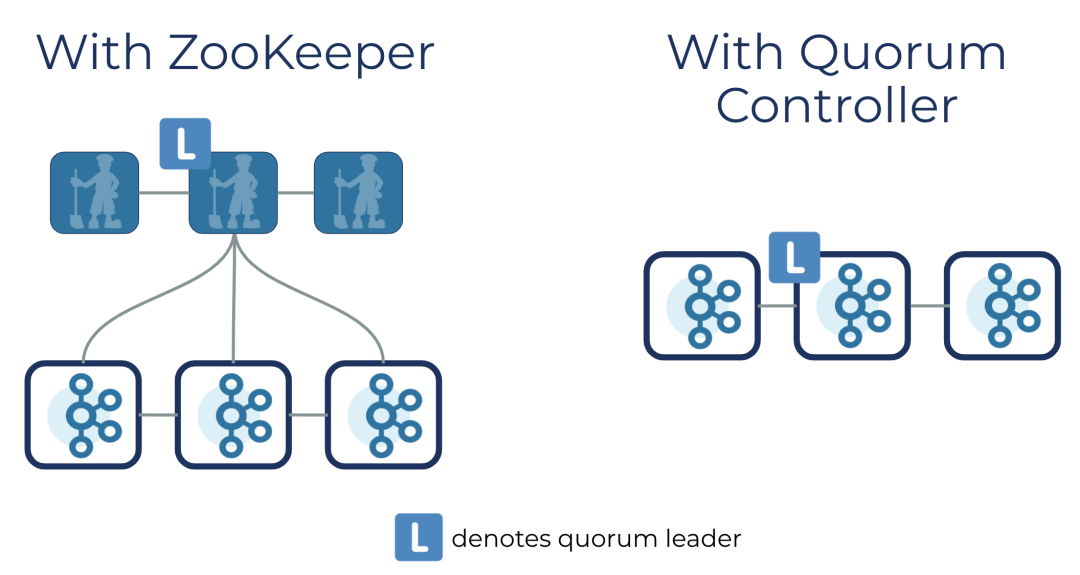
不过今天我们测试选择安装单节点的kafka就行了。安装单节点的很简单,先下载安装介质并解压。
1.生成集群ID
./bin/kafka-storage.sh random-uuid4rcJzm9bSJmDP7q6fX0ujA
2.格式化存储目录
./bin/kafka-storage.sh format -t 4rcJzm9bSJmDP7q6fX0ujA -c ./config/kraft/server.propertiesFormatting /tmp/kraft-combined-logs
3.启动Kafka服务
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
4.创建topic并测试
./bin/kafka-topics.sh --create --topic oracletest --partitions 1 --replication-factor 1 --bootstrap-server 192.168.56.170:9092 Created topic oracletest../bin/kafka-topics.sh --list --bootstrap-server 192.168.56.170:9092oracletest
至此kafka2.8单机安装完毕。这里要说明一点,在kraft文件夹下的readme说了一点:
KRaft mode in Kafka 2.8 is provided for testing only, NOT for production. We do not yet support upgrading existing ZooKeeper-based Kafka clusters into this mode. In fact, when Kafka 3.0 is released,it will not be possible to upgrade your KRaft clusters from 2.8 to 3.0. There may be bugs, including serious ones. You should assume that your data could be lost at any time if you try the early access release of KRaft mode.
2.8版本仅仅只能作为测试,不要使用到生产环境。
Oracle侧配置
我的oracle12c,cdb和pdb都有,所以配置略为麻烦。首先前提的条件是归档必须是打开的。
1.创建表空间和用户
sqlplus / as sysdbaCREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/logminer_tbs.dbf' SIZE 50M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;alter session set container=ORCLPDB1;Session altered.CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/logminer_tbs.dbf' SIZE 50M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
这里需要在你的cdb和pdb都创建表空间。如果你有多个pdb,每一个都需要建。
2.创建用户和赋权
CREATE USER c##dbzuser IDENTIFIED BY dbzDEFAULT TABLESPACE logminer_tbsQUOTA UNLIMITED ON logminer_tbsCONTAINER=ALL;GRANT CREATE SESSION TO c##dbzuser CONTAINER=ALL;GRANT SET CONTAINER TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$DATABASE to c##dbzuser CONTAINER=ALL;GRANT FLASHBACK ANY TABLE TO c##dbzuser CONTAINER=ALL;GRANT SELECT ANY TABLE TO c##dbzuser CONTAINER=ALL;GRANT SELECT_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;GRANT EXECUTE_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL;GRANT SELECT ANY TRANSACTION TO c##dbzuser CONTAINER=ALL;GRANT LOGMINING TO c##dbzuser CONTAINER=ALL;GRANT CREATE TABLE TO c##dbzuser CONTAINER=ALL;GRANT LOCK ANY TABLE TO c##dbzuser CONTAINER=ALL;GRANT ALTER ANY TABLE TO c##dbzuser CONTAINER=ALL;GRANT CREATE SEQUENCE TO c##dbzuser CONTAINER=ALL;GRANT EXECUTE ON DBMS_LOGMNR TO c##dbzuser CONTAINER=ALL;GRANT EXECUTE ON DBMS_LOGMNR_D TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOG TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOG_HISTORY TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOGMNR_LOGS TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOGMNR_CONTENTS TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOGMNR_PARAMETERS TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$LOGFILE TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$ARCHIVED_LOG TO c##dbzuser CONTAINER=ALL;GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO c##dbzuser CONTAINER=ALL;
3.打开附加日志
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;ALTER TABLE HR.EMPLOYEES ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
这里可以打开全库的附加日志,也可以只打开指定表的附加日志。
Kafka Connector 配置
接下来我们要配置kafka Connector。
1.下载Oracle客户端
wget "https://download.oracle.com/otn_software/linux/instantclient/19600/instantclient-basiclite-linux.x64-19.6.0.0.0dbru.zip" -O /tmp/oracle_client.zipmv oracle_client.zip /appunzip oracle_client.zip
解压完毕后,还需设置LD_LIBRARY_PATH环境变量。
export LD_LIBRARY_PATH=/app/kafka/instantclient_19_6
2.下载Oracle Connector Plug-in插件
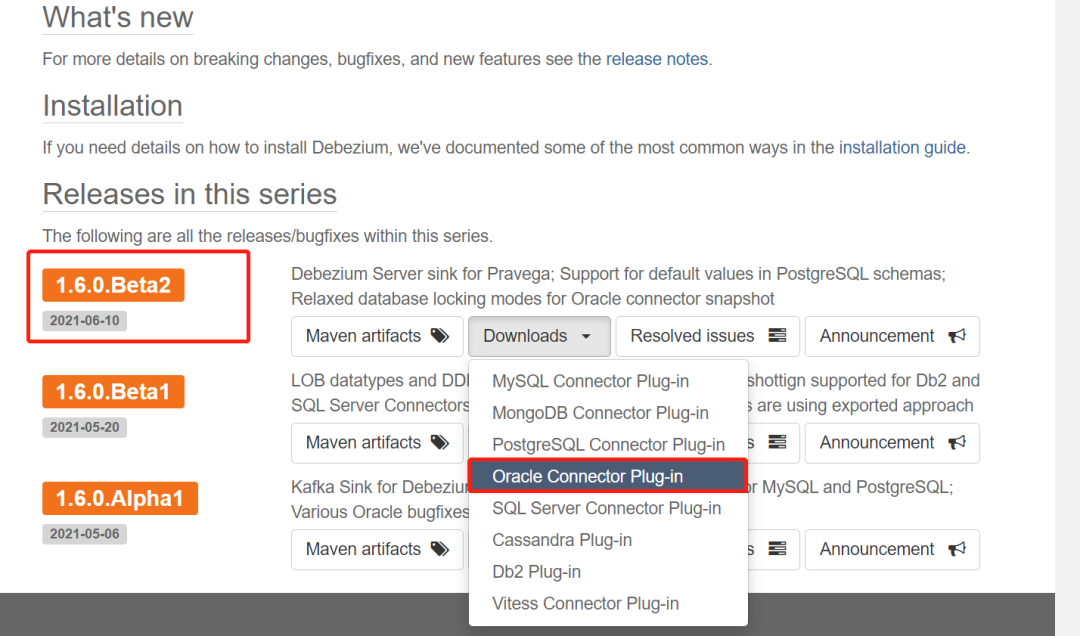
这里我也选择最新的1.60.Beta2下面的Oracle插件。
mkdir -p pluginsmv debezium-connector-oracle-1.6.0.Beta2-plugin.tar.gz /app/kafka/kafka_2.13-2.8.0/pluginsgunzip debezium-connector-oracle-1.6.0.Beta2-plugin.tar.gz tar -xvf debezium-connector-oracle-1.6.0.Beta2-plugin.tar
在kafka目录下创建一个plugins的目录,把下载的软件丢到该目录下并解压。
解压完毕后,修改connect-standalone.properties配置文件
cd /app/kafka/kafka_2.13-2.8.0/configvi connect-standalone.properties
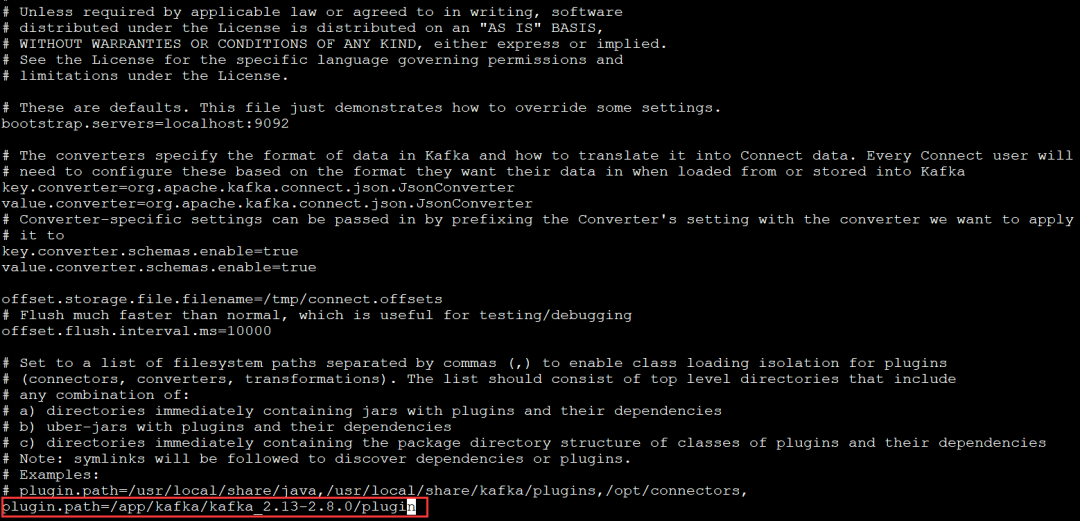
3.复制ojdbc8.jar到kafaka的libs
将Oracle客户端的ojdbc8.jar放在kafka的libs文件夹下。
cp -rp ojdbc8.jar ../kafka/kafka_2.13-2.8.0/libs/
4.对连接器进行配置
对于独立模式,只需在文件中定义,然后通过命令行启动就行了,我的配置文件如下。
name=testoracledbconnector.class=io.debezium.connector.oracle.OracleConnectordb_type=oracletasks.max=1database.server.name=oracle-12201-vagrantdatabase.tablename.case.insensitive=truedatabase.oracle.version=12+database.hostname=192.168.56.130database.port=1521database.user=c##dbzuserdatabase.password=dbzdatabase.dbname=ORCLCDBdatabase.pdb.name=ORCLPDB1database.history.kafka.bootstrap.servers=localhost:9092database.history.kafka.topic=debezium.oracledatabase.history.skip.unparseable.ddl=trueinclude.schema.changes=truetable.whitelist=hr.a1errors.log.enable=true
这里的配置选项很多,这里不做一一描述,基本上就是Oracle数据库的一些连接信息。
针对CDB和PDB的情况,需要同时配置database.dbname和database.pdb.name
具体选项可以参考:https://debezium.io/documentation/reference/1.6/connectors/oracle.html#oracle-property-name
5.重启kafka测试是连接器是否可以正常工作
./kafka-server-stop.sh ./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
在Oracle侧插入一条数据.
insert into hr.a1 select * from EMPLOYEES where rownum<=1;SQL> select * from a1;EMPLOYEE_ID FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID SALARY COMMISSION_PCT MANAGER_ID DEPARTMENT_ID----------- --------------- --------------- --------------- -------------------- --------- ---------- ---------- -- 198 Donald OConnell DOCONNEL 650.507.9833 21-JUN-07 SH_CLERK 2600 124 50
使用kafka-console-consumer.sh脚本来读取topic信息
./kafka-console-consumer.sh --bootstrap-server 192.168.56.170:9092 --topic oracle-12201-vagrant.HR.A1 --from-beginning --property print.key = true | jq
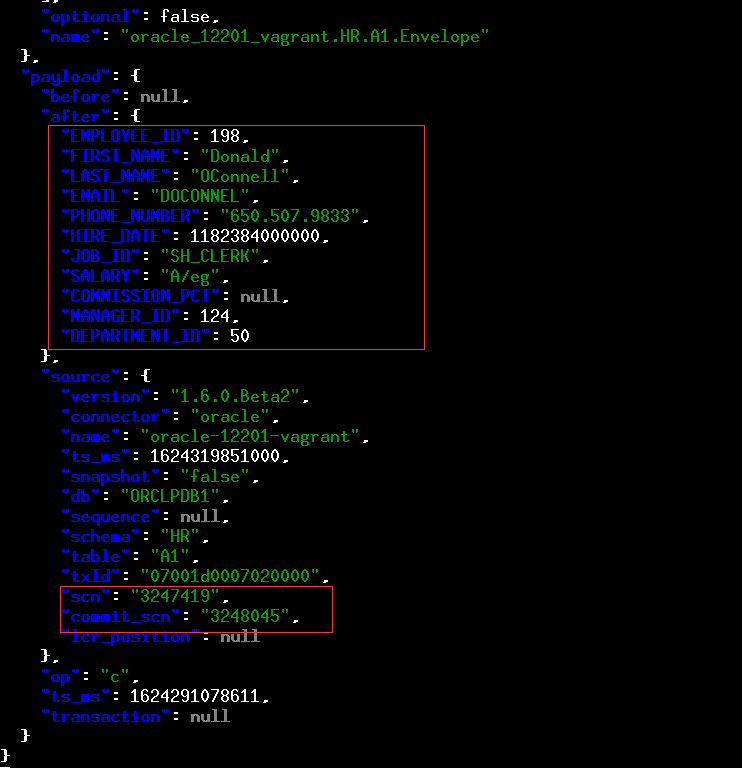
这里的输出结果很长,我们可以看到刚刚插入的信息,还有Oracle的SCN的信息。
后记
Oracle到Kafka这一侧的配置已经完成,后续是PostgreSQL来消费这些消息。未完待续...
参考文档
1.https://debezium.io/documentation/reference/1.6/connectors/oracle.html
