




使用Oracle 10g的Database Control可以进行方便的空间管理,登录DB Control首页就可以看到“空间概要”及预警信息,如图5-12所示。
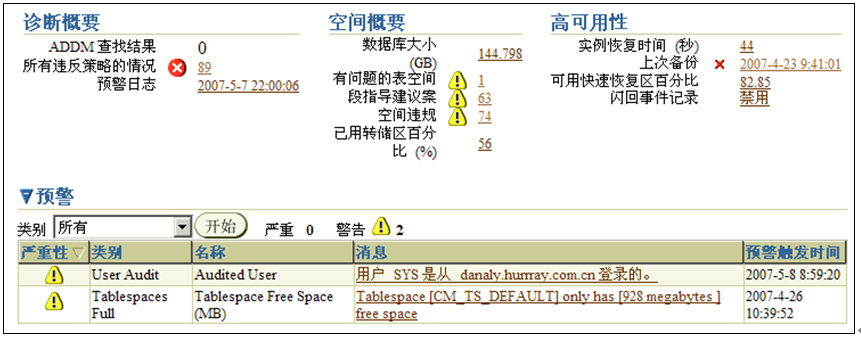
图5-12 诊断概要、空间概要和预警
DB Control已经将违反了数据库度量规则的信息列举了出来,如图5-13所示,这里存在一个有问题的表空间。

图5-13 列出有问题的表空间
这个有问题的表空间也正是预警信息中记录的,由于空间低于DBA_THRESHOLDS的设置,所以数据库发出警告,可以通过扩展表空间数据文件的方法来解决这个问题,也可以通过修改阈值来消除警告。单击该表空间可以进入详细的编辑表空间页面,如图5-14所示,将空闲空间的警告阈值设置为500MB,严重警告阈值设置为200MB。
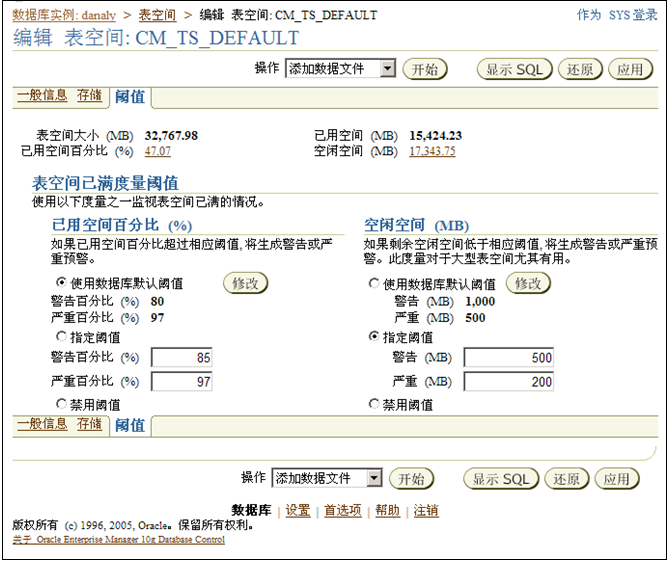
图5-14 编辑表空间
通过显示SQL功能,可以看到Oracle调用的内部过程及操作,此处实际上是通过DBMS_SERVER_ALERT.SET_THRESHOLD来修改阈值限制,如图5-15所示。

图5-15 显示SQL
确认无误以后可以应用这个修改。如果经过调整消除了告警,那么数据库也会在DB Control中去除这个告警提示,此时查询DBA_OUTSTANDING_ALERTS视图,会发现之前的告警信息已经消失了,但不幸的是,新的告警信息出现了:
SQL> select OBJECT_NAME,OBJECT_TYPE,REASON,SUGGESTED_ACTION 2 from DBA_OUTSTANDING_ALERTS; OBJECT_NAME OBJECT_TYPE REASON ----------------------------------- --------------- ---------------------------------- SUGGESTED_ACTION ------------------------------------------------------------ SID: 154 Serial#: 45847 SESSION Session 154 is blocking 2 other sessions Run ADDM to get more performance analysis about your system.
此外通过首页的预警信息选项,也可以进入建议案页面,了解数据库的建议案,如图5-16所示。

图5-16 建议案页面
这里可以选择编辑表空间、重组或段指导建议案来调整表空间,解决空间警告。单击“段指导建议案”按钮,打开如图5-17所示的建议案详细资料页面,在这里数据库列出了可以通过收缩(Shrink)进行空间回收的数据表。
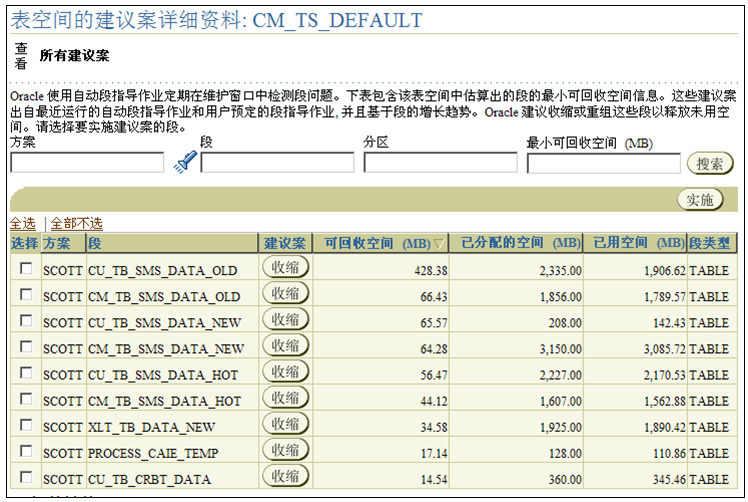
图5-17 表空间的建议案详细资料
可以通过DB Control很简便地完成前面曾经讨论过的Shrink过程,这里选择第一个选项“压缩段并释放空间”,如图5-18所示,可以回收428.38MB的空间:

图5-18 选择收缩操作
当然SQL实际上和在命令行的操作没什么不同,如图5-19所示。

图5-19 显示SQL
确认之后数据库会提交一个任务,可以选择立即执行这个Shrink操作,或者将这个操作推迟到一个空闲时段再执行,如图5-20所示。
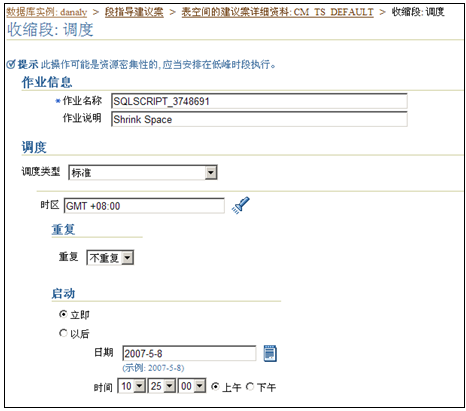
图5-20 设置操作执行时间
提交之后,可以在“调度程序作业”页面中看到这个任务,同时可以在后台看到这个Job任务的会话ID为134,如图5-21所示。

图5-21 调度程序作业
根据这个SID,可以在数据库中找到这个会话的相关等待信息:
SQL> select sid,event,p1,p2,p3 from v$session where sid=134; SID EVENT P1 P2 P3 ---------- ------------------------- ---------- ---------- ---------- 134 db file sequential read 9 2563281 1 SQL> / SID EVENT P1 P2 P3 ---------- ------------------------- ---------- ---------- ---------- 134 db file sequential read 9 70186 1 SQL> / SID EVENT P1 P2 P3 ---------- ------------------------- ---------- ---------- ---------- 134 db file sequential read 9 70386 1 SQL> / SID EVENT P1 P2 P3 ---------- ------------------------- ---------- ---------- ---------- 134 db file sequential read 9 70521 1
可以看到Oracle通过db file sequential read不断进行单块读取,来调整记录的存储,这和之前介绍的Shrink原理是一致的。通过SID可以进一步获得会话的SPID号,也就是Job操作在操作系统上的进程号:
SQL> select spid from v$process where addr = ( 2 select paddr from v$session where sid = 134) 3 / SPID ------------ 28655
通过操作系统的TOP工具可以观察一下进程28655的CPU消耗,大部分时间这个进程都排在CPU消耗的第一位,占用了40%~50%左右的CPU资源:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28655 oracle 15 0 995m 284m 280m S 53.9 14.0 0:56.83 oracle
所以在Shrink时应当考虑系统是否繁忙,操作是否会影响业务,作为一个DBA,你需要考虑的因素有很多,任何一个看似微小的疏忽都可能导致严重的故障。
在调度任务中,可以单击会话号来获得会话的详细信息,这些信息非常详尽,如图5-22所示。
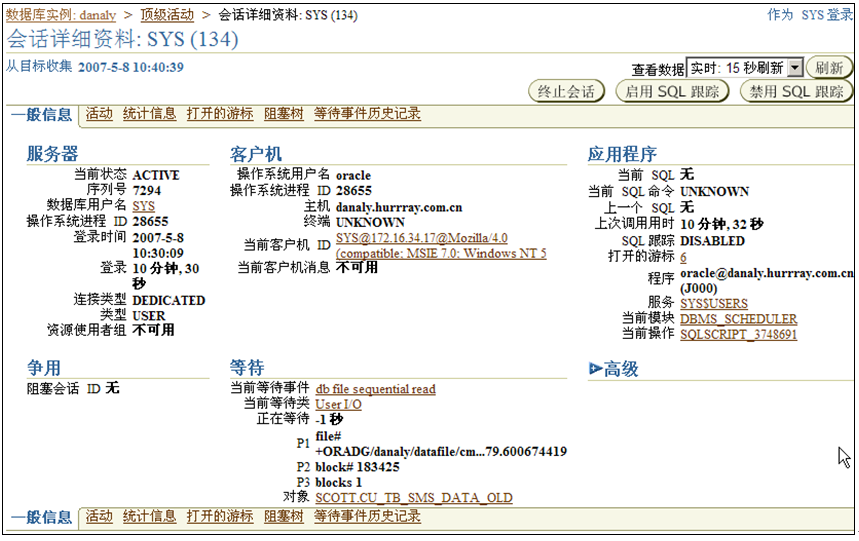
图5-22 会话详细资料
在“等待”部分,可以看到会话正在等待的资源,通过“等待事件历史记录”链接可以得到会话最近的等待信息,如图5-23所示,这些信息和通过命令行查询得到的信息完全一致。
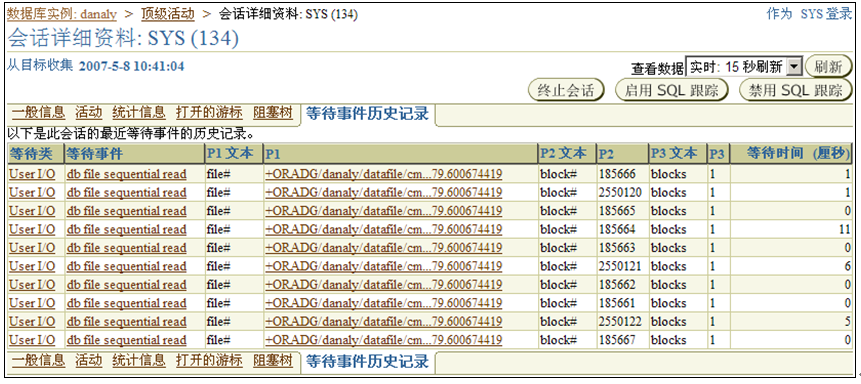
图5-23 等待事件历史记录
更进一步地,可以在顶级会话中找到这个活动事务,这个事务占用了大量的CPU时间在执行,而且系统在此时间段内负载较高,I/O操作频繁,如图5-24所示。
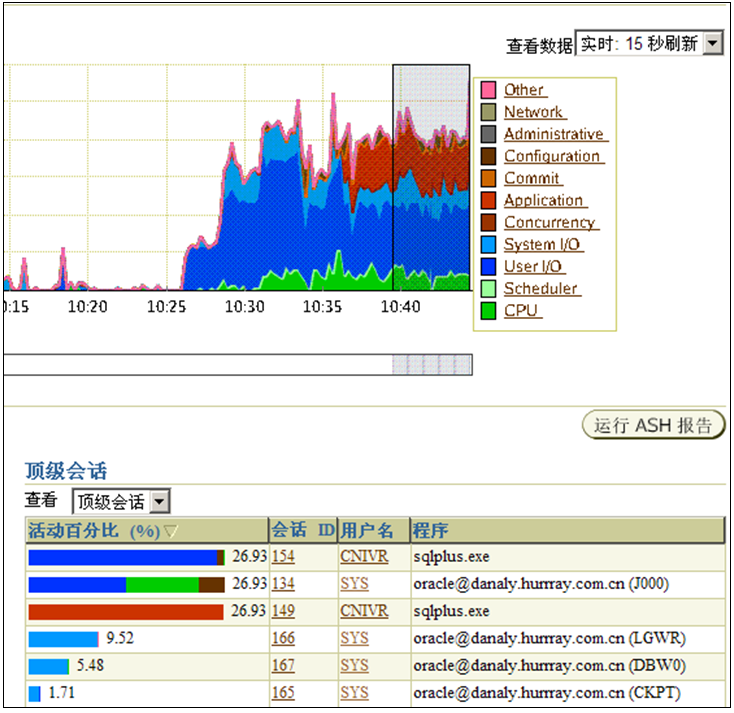
图5-24 查看顶级会话
等Job任务完成之后,可以在作业中找到这个任务的执行信息,如图5-25所示。

图5-25 任务详细资料
这个任务共执行了45.38分钟,占用了965.15秒的CPU时间。这个Shrink过程是相当漫长的,所以在生产环境中,应该选择业务空闲阶段来执行这类操作。
