




业务数据采集系列:
三、简析数据同步策略
四、Sqoop安装配置以及采集数据到HDFS
五、业务数据采集总结
一、Sqoop的安装和配置

[qiusheng@node01 conf]$ mv sqoop-env-template.sh sqoop-env.sh

HADOOP_HOME; HIVE_HOME; HBASE_HOME:这里我们还暂时没有使用hbase ZOOKEEPER_HOME;
#hadoop1.x需要配置这两个环境变量,#但是2.x以上配置HADOOP_HOME的环境变量就OK了export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.4export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.4#sqoop可以把数据直接导入到hive里面export HIVE_HOME=/opt/module/hive#sqoop配置zk_home和direxport ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf#set the path to where bin/hbase is available#export HBASE_HOME=
cp mysql-connector-java-5.1.48.jar opt/module/sqoop1.4.7/lib/

3、验证是否安装成功
[qiusheng@node01 sqoop-1.4.7]$ bin/sqoop help

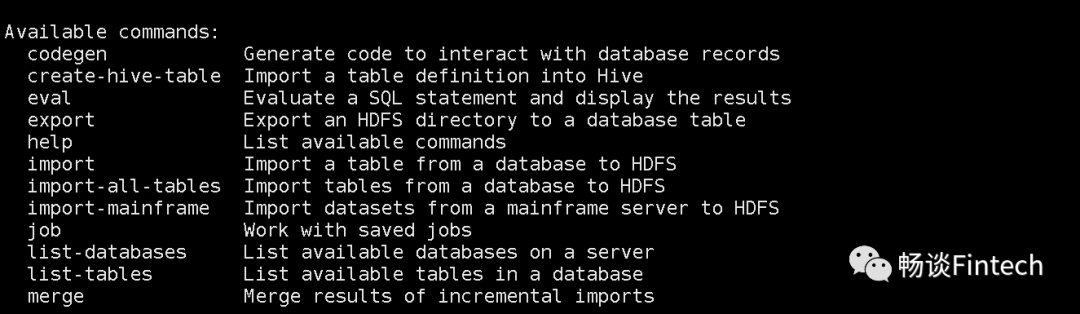
二、Sqoop导入单表到HDFS
[qiusheng@node01 sqoop-1.4.7]$bin/sqoop list-databases --connect jdbc:mysql://node01:3306/ --username root -P

输入mysql的登录密码;
显示如下:可以看到mysql的库了,说明链接mysql正常。

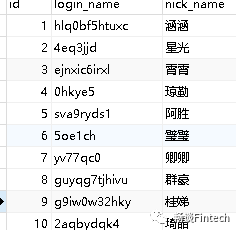
我们来分析一下sqoop命令行:
#import是mysql等导入到HDFS#export则是HDFS导出到mysql等./bin/sqoop import \#使用jdbc链接数据库,需要URL、用户名、密码--connect jdbc:mysql://node01:3306/gmall \--username root \--password XXXXX \#哪张表?哪些字段--table user_info \--columns id,login_name,nick_name \#哪些数据?条件是什么?--where "id >= 10 and id <= 100" \#导入到HDFS集群路径--target-dir gmall_data/db/test01 \--delete-target-dir \#分隔符\t--fields-terminated-by '\t' \#分配mapper--num-mappers 2 \#根据id分割--split-by id \
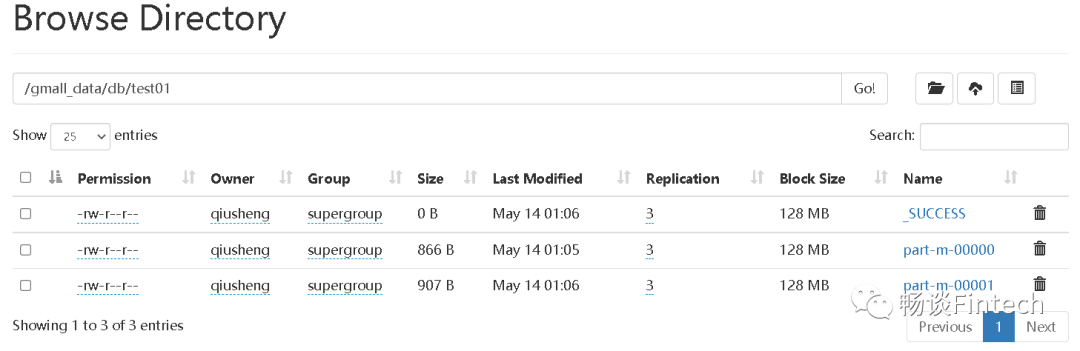
执行后HDFS集群上显示:
路径是:/gmall_data/db/test01;
副本数量是:3份;
三、Sqoop脚本导入HDFS
导入单表数据成功后,我们尝试导入所有业务表到HDFS。这里使用脚本来完成,由于脚本文件比较长,现在分段简析一下脚本文件。
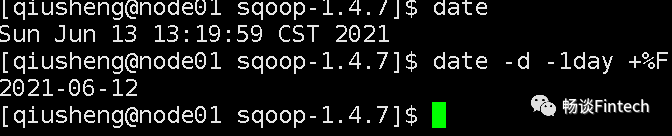
1、处理时间
我们希望的是每天晚上0点自动把mysql数据导入到HDFS。如:6月13号,统计是6月12日的数据,格式是2021-06-12,我们需要把系统时间减掉1天。
脚本文件传入的格式是指定时间:
xxxx.sh 2021-05-01
不指定时间,默认使用系统时间减掉1天
xxxx.sh
#用户可以传入的格式是:mysql_to_hdfs.sh 2021-05-01if [ -n "$1" ] ;thendo_date=$1#传入时间为空,即没有传入时间mysql_to_hdfs.sh,给他系统时间 -1dayelsedo_date=`date -d '-1 day' +%F`fi
查询条件需要做成动态的,根据数据表的同步策略;
全量表:select * from 表;
增量表:select * from 表 where 创建表时间 = 今天;
新增和变化:select * from 表 where 创建表时间 = 今天 and 操作时间 = 今天
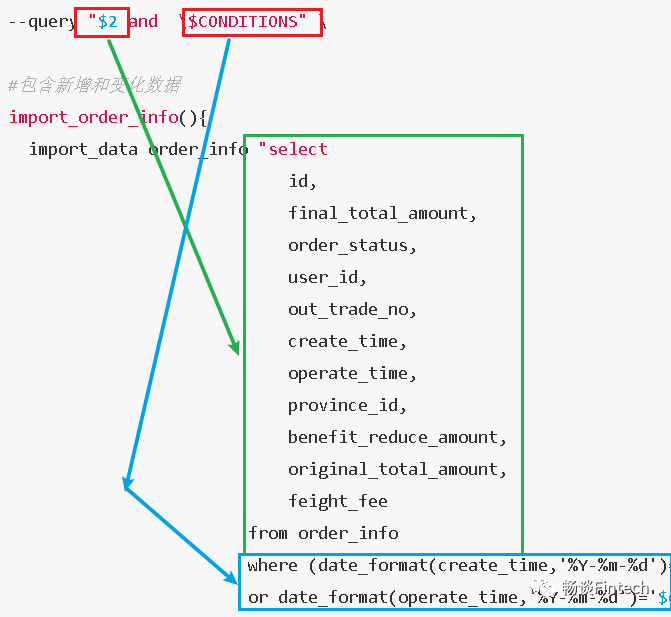
$2:根据数据同步策略编写sql语句
$CONDITIONS:转义拼接语法,比如(id >10,id < 100)
3、lzo压缩处理
首先要处理mysql上传到HDFS支持lzo压缩分片 需要使用lzo压缩的索引 处理mysql null值到HDFS(如:Hive)空值的区别;
#支持lzo压缩--compress \--compression-codec lzop \#mysql to hdfs空值处理--null-string '\\N' \--null-non-string '\\N'#添加lzo索引hadoop jar opt/module/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer origin_data/$APP/db/$1/$do_date}
定义import_data(parms1,parms2)
parms1:表名,如下面的“order_info”
parms2:数据同步策略后的where语句,如下面的“select,,,”
import_order_info(){import_data order_info "selectid,final_total_amount,order_status,user_id,out_trade_no,create_time,operate_time,province_id,benefit_reduce_amount,original_total_amount,feight_feefrom order_infowhere (date_format(create_time,'%Y-%m-%d')='$do_date'or date_format(operate_time,'%Y-%m-%d')='$do_date')"}
传入表名
$1是表示表名
case $1 in"order_info")import_order_info;;"base_category1")import_base_category1;;
特殊表导入
特殊表就是同步策略讲到的那些特殊表。比如:省份等;
在第一次导入HDFS时间,这些特殊表就一次性的导入HDFS。
$1是first
case $1 in"first")import_base_category1import_order_info
全量表
$1是all
case $1 in"all")import_base_category1import_base_category2
初次导入脚本
mysql_to_hdfs.sh first 2021-05-01
每日导入脚本
mysql_to_hdfs.sh all 2021-05-02

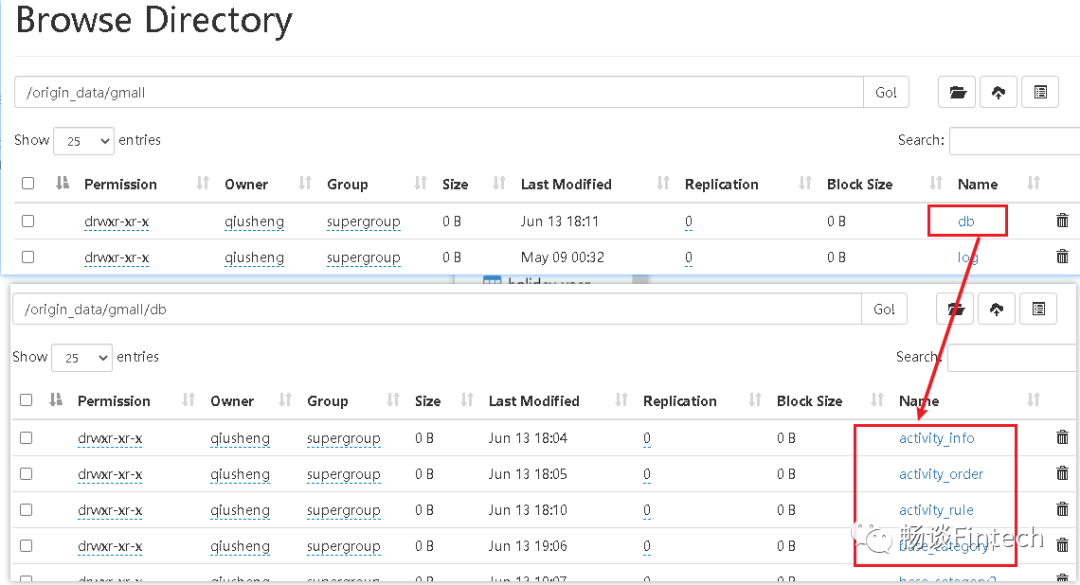
按照1天一个目录。

Sqoop的安装和配置
Sqoop操作mysql导入到HDFS
Sqoop脚本编写
上传数据格式为lzo数据,并且支持lzo切片索引
HDFS路径查看是否已经有了业务数据
