




一、数仓表类型
业务数据最终会被采集到数仓里面,那么数仓里面的表类型有哪几种呢?
首先理解一下全量表:
全量表没有分区,假设表中的数据是前一天的所有数据,比如说今天是2号,那么全量表里面拥有的数据是1号的所有数据,每次往全量表里面写数据都会覆盖之前的数据,所以全量表不能记录历史的数据情况,只有截止到当前最新的、全量的数据。
2、快照表
如果想查到历史数据这种情况又该怎么办呢?
这个时候快照表就派上用途了,快照表是有时间分区的,每个分区里面的数据都是分区时间对应的前一天的所有全量数据,比如说当前数据表有3个分区,10号,11号,12号。其中,10号分区里面的数据就是从历史到9号的所有数据,以此类推。
就是记录每天新增数据的表,比如说,从10号到11号新增了哪些数据?改变了哪些数据?这些都会存储在增量表的11号分区里面。
上面说的快照表的11号分区和10号分区(都是t+1,实际时间分别对应12号和11号)。
4、拉链表
有关拉链表的介绍,这里只是简单介绍一下预热,到了数仓环节会再次详细介绍。
拉链表,它是一种维护历史状态,以及最新状态数据的一种表。拉链表也是分区表,有些不变的数据或者是已经达到状态终点的数据就会把它放在分区里面,分区字段一般为开始时间:start_date和结束时间:end_date。一般在该天有效的数据,它的end_date是大于等于该天的日期的。获取某一天全量的数据,可以通过表中的start_date和end_date来做筛选,选出固定某一天的数据。
例如:想取截止到20210510的全量数据。
where过滤条件就是:
where start_date<='20210510'
and end_date>=‘20210510’;
二、数据同步策略
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况等策略。
这个时候我们再来看全量同步策略:
这个策略最简单了,每天存储一份完整数据,作为一个分区(以后数仓使用按天)每日上传一个全量到HDFS。
但是这样也有一个问题,就是数据量大的时候,其实每个分区都存储了许多重复的数据,非常的浪费存储空间。
适用于:表数据量不大,且每天既有新数据插入,也会有旧数据修改的场景。一般小型公司可以每日一个全量同步。
就是同步增加的数据,每天只来存储一份增量数据,作为一个分区。
适用于:表数据量很大,且每天只有新数据插入的场景。即每天新增数据。
这个时候就考虑这种表做增量同步策略处理。
又称“拉链表”,每日新增及变化,就是存储创建时间和操作时间都是今天的数据。适用场景为表的数据量大,既会有新增,又会有变化。
例如:用户表
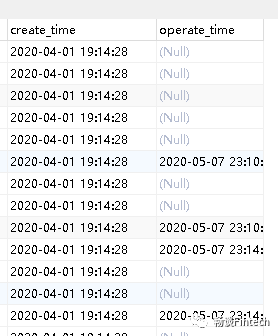
某些特殊的维度表,可不必遵循上述同步策略。
客观世界维度值 没变化的客观世界的维度(比如性别,地区,民族)可以只存一份固定值。 日期维度 可以一次性导入一年或若干年的数据。
