




GaussDB如果采用分布式部署模式,则可以根据数据量以及用途定义两种不同分布方式的表,分别为复制表(Replication)和哈希(Hash)表。
复制表(Replication)是将表中的全量数据在集群的每一个DN实例上保留一份,主要适用于数据量较小的表。这种存储方式的优点是每个DN上都有此表的全量数据,在join操作中可以避免数据重分布操作,从而减小网络开销。缺点是每个DN都保留了表的完整数据,造成数据的冗余。一般情况下只有较小的维度表才会定义为Replication表。
哈希(Hash)表是将表中某一个或几个字段进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置。对于Hash分布表,在读/写数据时可以利用各个节点的IO资源,大大提升表的读/写速度。一般情况下大表定义为Hash表。

Hash分布表的分布列选取至关重要,需要满足以下原则:
(1)、列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为分布列,如在人员信息表中选择身份证号码为分布列。
(2)、在满足第一条原则的情况下尽量不要选取存在常量filter的列。例如,表dwcjk相关的部分查询中出现dwcjk的列zqdh存在常量的约束(例如zqdh=’000001’),那么就应当尽量不用zqdh做分布列。
(3)、在满足前两条原则的情况下,考虑选择查询中的连接条件为分布列,以便Join任务能够下推到DN中执行,且减少DN之间的通信数据量。
(4)、一般不建议新增一列专门用作分布列,尤其不建议新增一列,然后用SEQUENCE的值来填充做为分布列,因为SEQUENCE可能会带来性能瓶颈和不必要的维护成本。
对于Hash分布表策略,如果分布列选择不当,可能导致数据倾斜,查询时出现部分DN的I/O短板,从而影响整体查询性能。因此在采用Hash分布表策略之后需对表的数据进行数据倾斜性检查,以确保数据在各个DN上是均匀分布的。
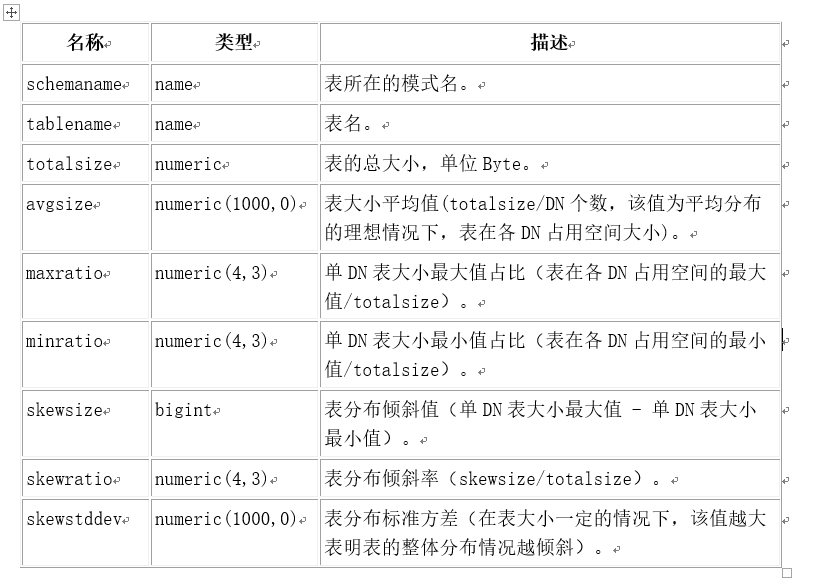
GaussDB中提供了1个视图pgxc_get_table_skewness,可以查询数据库中所有schema下的表在各个DN的分布情况以及倾斜率,虽然可以通过schemaname和tablename查询指定表的倾斜情况,但该视图查询时耗时较长,仅适用于数据量较小的表(10W以下),尤其不建议不增加条件查询所有表的数据倾斜情况。该视图各个字段说明如下:
除此之外,可以使用函数table_skewness()和table_distribution()查询指定表的数据倾斜情况。在使用table_skewness()时,如果不指定具体字段,默认查询当前分布列的数据倾斜程度,因此该函数可以用来评估表的其他字段分布倾斜情况。同样,当表的数据量巨大时,这两个函数查询耗时都比较长。因此对于一张数据量较大的表,一般使用如下语句查询其数据倾斜情况:
select xc_node_id, count(1) from tablename group by xc_node_id order by xc_node_id desc;
如果需要查询数据库中倾斜的表,除了使用上面提到的视图pgxc_get_table_skewness,还可以通过排查各个DN实例数据存储目录的大小以及数据文件来找出倾斜的表,这也是实际应用中比较常用的方法。具体方法及步骤如下:
(1)、在所有节点上执行df –h查看各个DN数据目录使用率是否有接近,找到使用率明显较大的磁盘目录。
(2)、通过 cm_ctl query –Cvd 确认该磁盘节点对应的DN实例(如上一步检查为slave磁盘占用率过大,则需要查看与该备实例对应的主实例磁盘使用情况),确认DN实例端口号。可通过以下方式查询DN实例端口号:
select * from pgxc_node;
或者
cat DN实例数据目录/postgresql.conf |grep Port
(3)、进入实例base目录,执行du -ak | sort -nr | more查找文件大小为1GB,且文件前缀数字ID相同的文件,查找相同文件数量最多的文件,记录其ID值及其所在文件目录ID值。
(4)、通过gsql连接DN实例,并通过文件目录ID确认表所属数据库。
select oid,* from pg_database where oid='1642599';
(5)、切换至该数据库,通过文件的ID确认表名称,执行如下SQL:
select relname from pg_class where relfilenode = 3308672;
(6)、根据表名称进一步确认该表所属schema,执行如下SQL:
SELECT n.nspname as "Schema",
c.relname as "Name"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n
ON n.oid = c.relnamespace
WHERE relname = 'insured';
(7)、通过gsql连接CN实例,最后再通过table_skewness()函数进行核实确认。
