




写在前面

之前我用很多的篇章来介绍了Zookeeper,因为我觉得Zookeeper作为一个一致性协调的服务中间件,可以帮助我们解决在分布式系统当中遇到的许许多多的问题。既可以作为注册中心进行服务治理,又可以作为配置中心为服务提供动态的可配置的中心化静态配置资源存储。其实在分布式系统架构中,还有一种情况也是非常常见并且迫切需要解决的问题,就是分布式微服务进行共享资源访问时的原子性保证。在 JVM 中,在多线程并发的情况下,我们可以使用同步锁或 Lock 锁,保证在同一时间内,只能有一个线程修改共享变量或执行代码块。但现在我们的服务基本都是基于分布式集群来实现部署的,对于一些共享资源,例如库存,定时任务执行等,在分布式环境下使用 Java 锁的方式就失去作用了。这时,我们就需要实现分布式锁来保证共享资源的原子性。
什么是分布式锁
首先我们来看下面的业务场景,系统A是一个电商系统,目前是一台机器部署,系统中有一个用户下订单的接口,但是用户下订单之前一定要去检查一下库存,确保库存足够了才会给用户下单。由于系统有一定的并发,所以会预先将商品的库存保存在Redis中,用户下单的时候会更新Redis的库存。如下图:
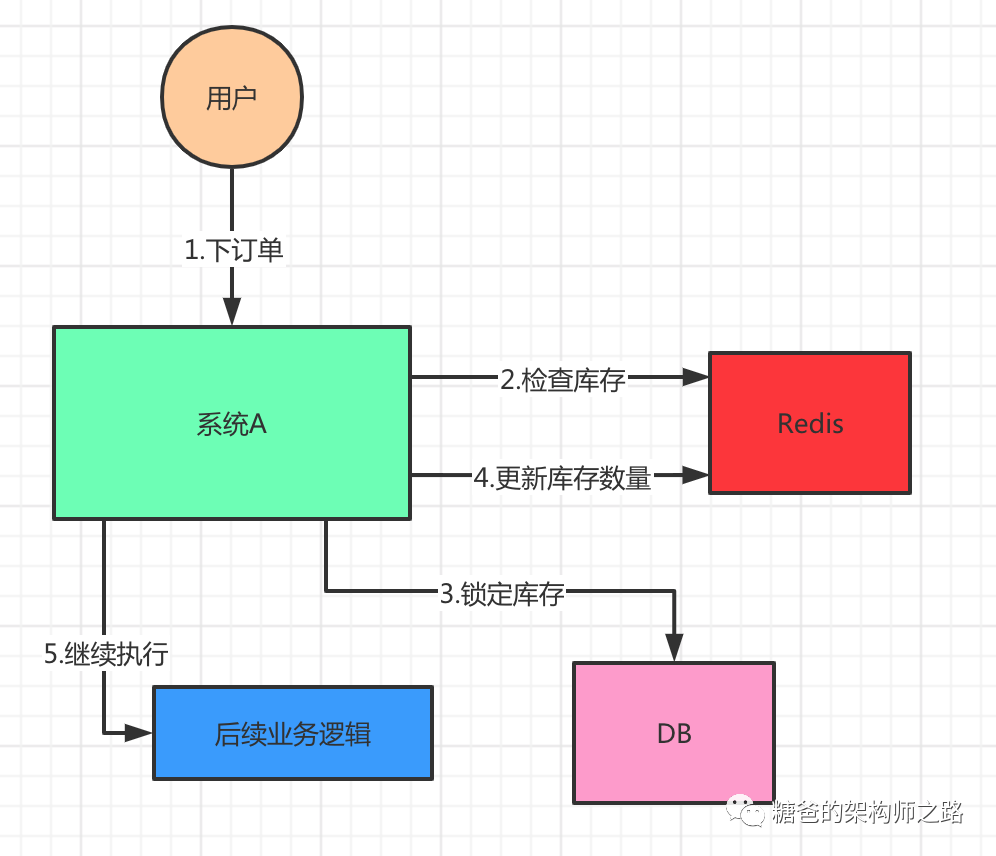
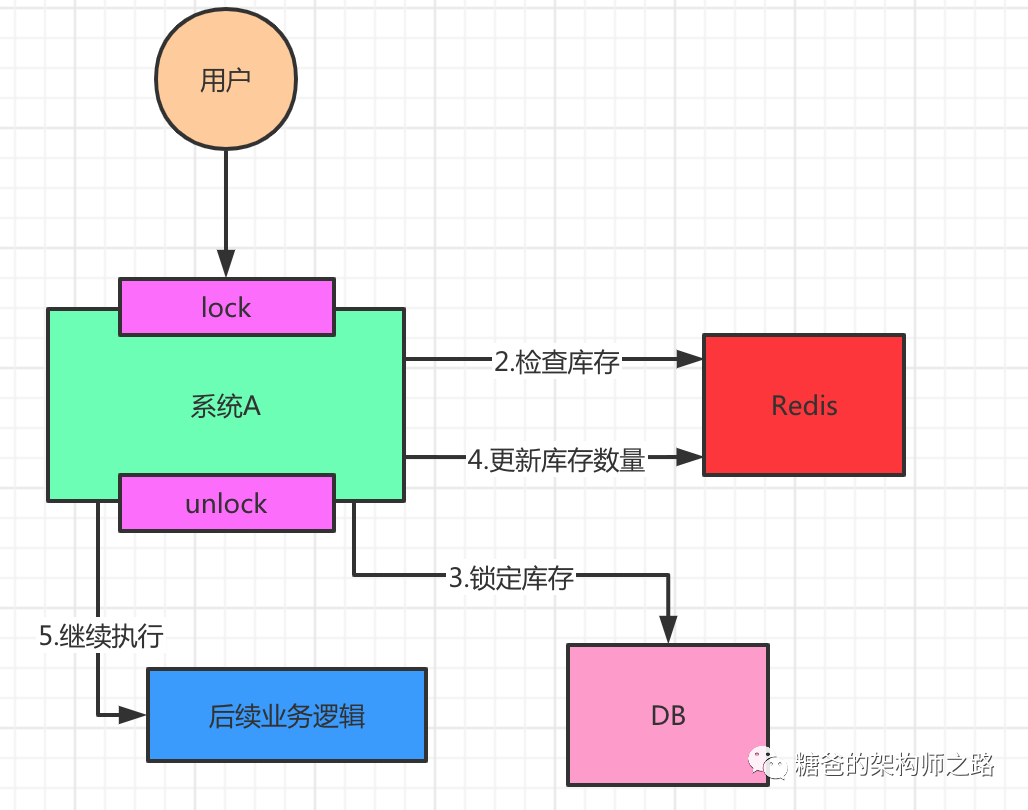
按照上面的图,在执行第2步时,使用同步锁或者可重入锁来锁住,然后在第4步执行完之后才释放锁。这样一来,2、3、4 这3个步骤就被“锁”住了,多个线程之间只能串行化执行。但是如果整个系统的并发飙升,一台机器扛不住了。现在要增加一台机器,如下图:
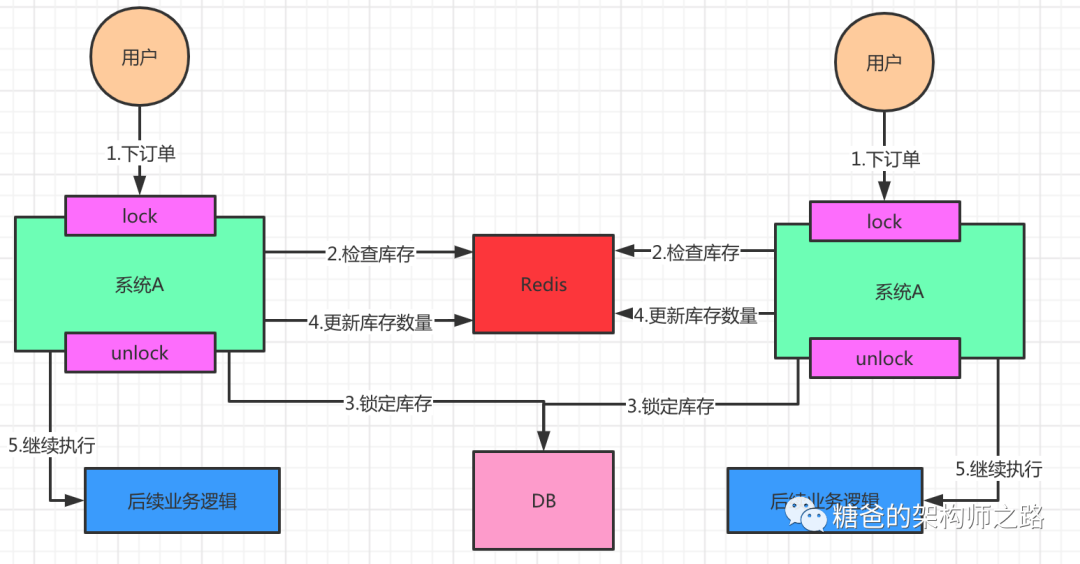
假设此时两个用户的请求同时到来,但是落在了不同的机器上,那么这两个请求是可以同时执行了,还是会出现库存超卖的问题。因为上图中的两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。因此,这里的问题是:Java提供的原生锁机制在多机部署场景下失效了,这是因为两台机器加的锁不是同一个锁(两个锁在不同的JVM里面)。那么,我们只要保证两台机器加的锁是同一个锁,问题不就解决了吗?此时,就该分布式锁隆重登场了,如下图:
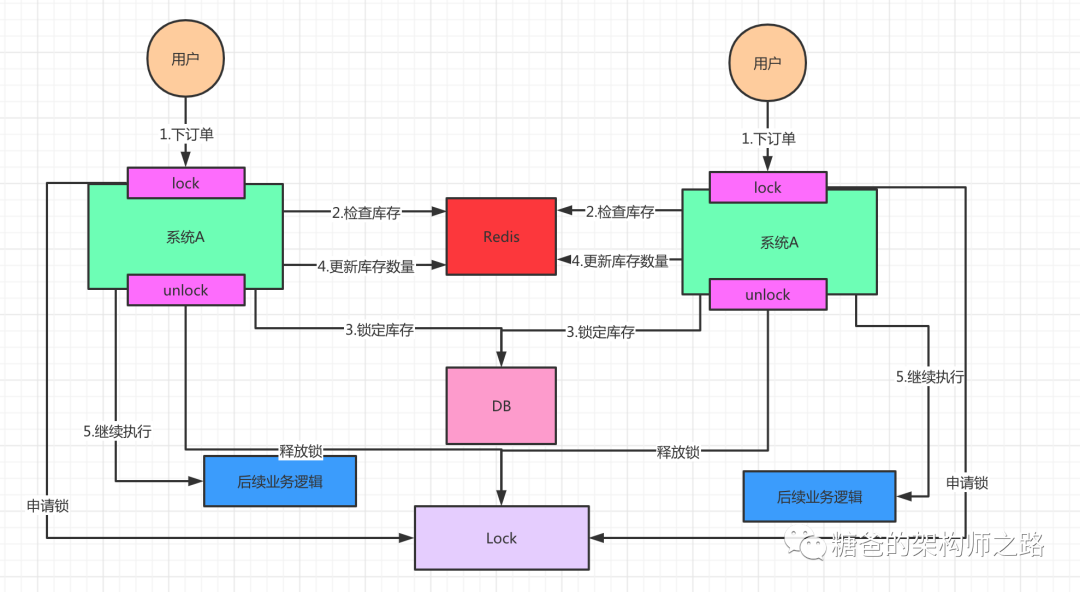
在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。所以,根据上面场景的需求,我们可以了解到分布式锁应该具备哪些条件:
在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行 高可用的获取锁与释放锁 高性能的获取锁与释放锁 具备可重入特性 具备锁失效机制,防止死锁 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
目前市面上应用比较广泛的分布式锁落地方案一般有三种:
数据库 Redis Zookeeper
CREATE TABLE `order` (`id` int(11) NOT NULL AUTO_INCREMENT,`order_no` int(11) DEFAULT NULL,`pay_money` decimal(10, 2) DEFAULT NULL,`status` int(4) DEFAULT NULL,`create_date` datetime(0) DEFAULT NULL,`delete_flag` int(4) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_status`(`status`) USING BTREE,INDEX `idx_order`(`order_no`) USING BTREE) ENGINE = InnoDB
其次,如果要操作库存,就要先查询该记录是否存在数据库中,查询的时候要防止幻读,如果不存在,就插入到数据库,否则,放弃操作。
select id from `order` where `order_no`= 'xxxx' for update
// 获取锁// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间SET anyLock unique_value NX PX 30000// 释放锁:通过执行一段lua脚本// 释放锁涉及到两条指令,这两条指令不是原子性的// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0
一定要用SET key value NX PX milliseconds 命令 如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(key永久存在) value要具有唯一性 这个是为了在解锁的时候,需要验证value是和加锁的一致才删除key。这是避免了一种情况:假设A获取了锁,过期时间30s,此时35s之后,锁已经自动释放了,A去释放锁,但是此时可能B获取了锁。A客户端就不能删除B的锁了。
也可以使用Jedis来实现
private static final String LOCK_SUCCESS = "OK";private static final String SET_IF_NOT_EXIST = "NX";private static final String SET_WITH_EXPIRE_TIME = "PX";/*** 尝试获取分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @param expireTime 超期时间* @return 是否获取成功*/public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);if (LOCK_SUCCESS.equals(result)) {return true;}return false;}
虽然 SETNX 方法保证了设置锁和过期时间的原子性,但如果我们设置的过期时间比较短,而执行业务时间比较长,就会存在锁代码块失效的问题。我们需要将过期时间设置得足够长,来保证以上问题不会出现。但是即便设置的时间再长,理论上也无法规避因业务时间超过锁的过期时间导致的同时获取锁的问题。
如果是在 Redis 集群环境和哨兵模式下,由于 Redis 集群数据同步到各个节点时是异步的,如果在 Master 节点获取到锁后,在没有同步到其它节点时,Master 节点崩溃了,此时新的 Master 节点依然可以获取锁,所以多个应用服务可以同时获取到锁。
以上两个问题,我们都可以通过引入Redisson来得到解决。
定义
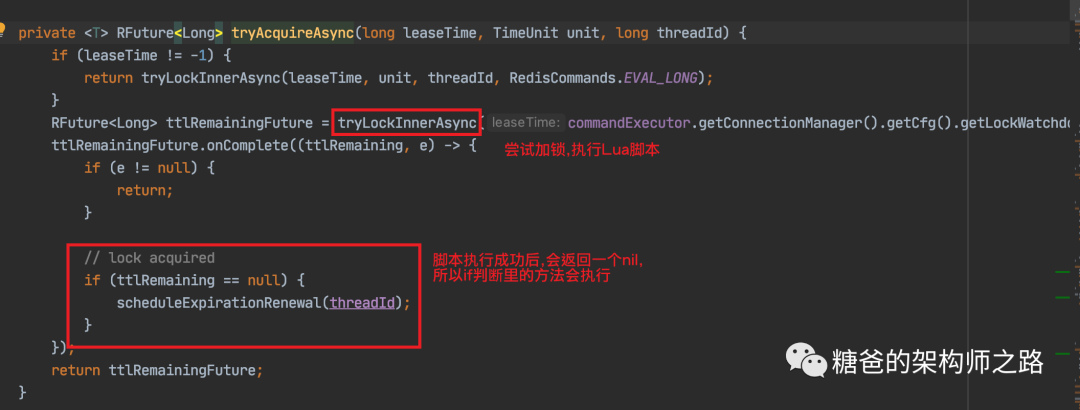
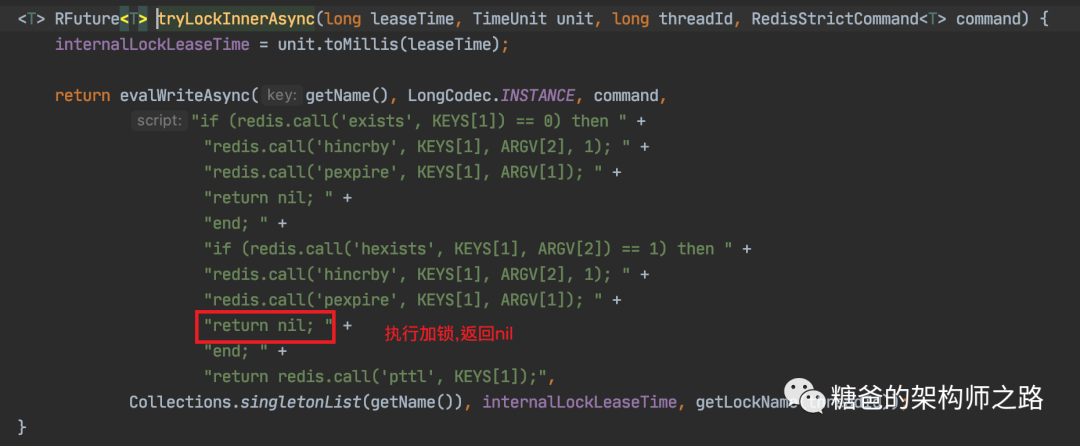
看门狗最终会调用
RedissonLock.renewExpiration()方法
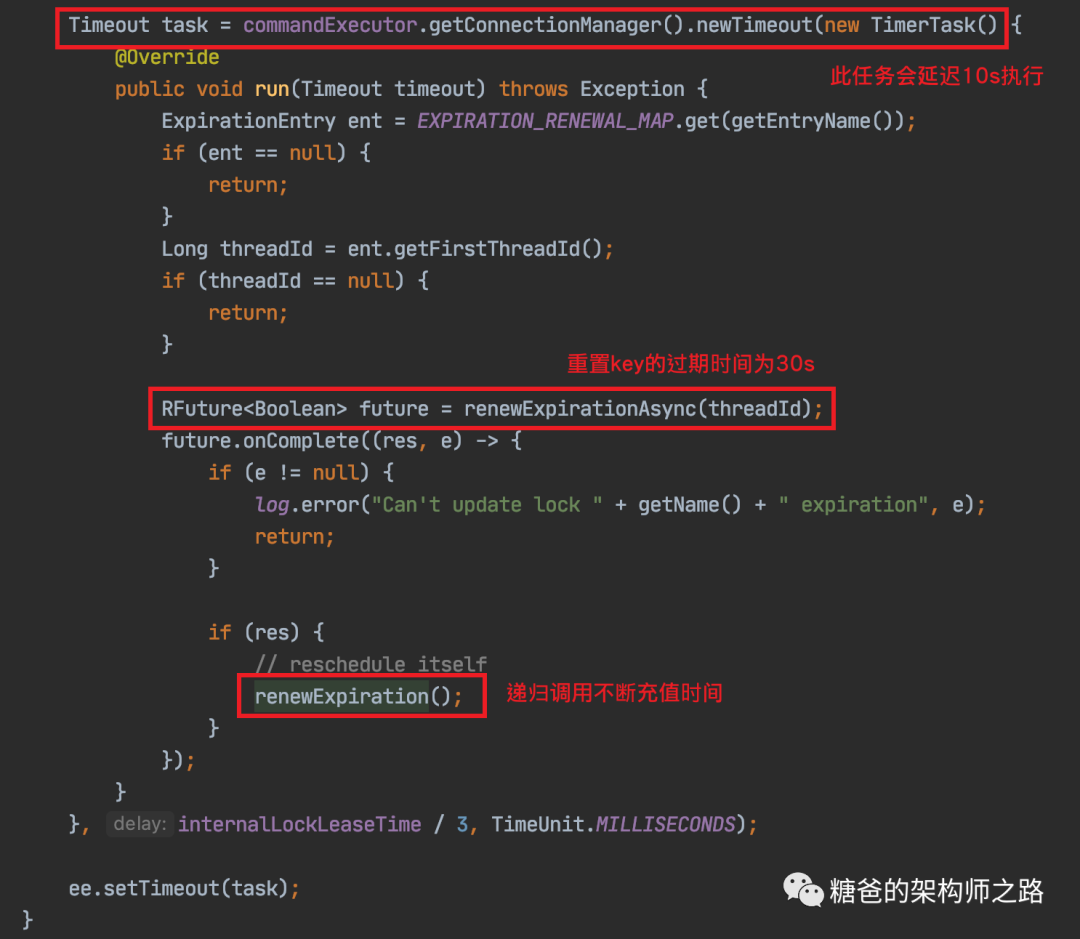
RedissonLock.renewExpiration()方法如果调用失败会打一个错误日志并返回,更新锁过期时间失败,然后获取异步执行的结果,如果为true,就会调用本身,如此说来又会延迟10秒钟去执行这段逻辑,所以,这段逻辑在你成功获取到锁之后,会每隔十秒钟去执行一次,并且,在锁key还没有失效的情况下,会把锁的过期时间继续延长到30000毫秒,也就是说只要这台服务实例没有挂掉,并且没有主动释放锁,看门狗都会每隔十秒给你续约一下,保证锁一直在你手中。


互斥访问:即永远只有一个 client 能拿到锁 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使锁定资源的服务崩溃或者分区,仍然能释放锁。 容错性:只要大部分 Redis 节点存活(一半以上),就可以正常提供服务

获取当前时间戳,单位是毫秒 client尝试按照顺序使用相同的key,value获取所有Redis服务的锁,在获取锁的过程中的获取时间比锁过期时间短很多,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个Redis实例。比如:TTL为5s,设置获取锁最多用1s,所以如果1s内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁
client通过获取所有能获取的锁后的时间减去第一步的时间,这个时间差要小于TTL时间并且至少有3个redis(n/2 + 1)实例成功获取锁,才算真正的获取锁成功
如果成功获取锁,则锁的真正有效时间是 TTL减去第三步的时间差 的时间。比如:TTL是5s,获取所有锁用了2s,则真正锁有效时间为3s 如果客户端由于某些原因获取锁失败,便会开始解锁所有Redis实例。因为可能已经获取了小于3个锁(n/2 + 1),必须释放,否则影响其他client获取锁

那如何通过Redisson来使用Redis的分布式锁呢?下面我们来看一下代码实现
引入依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.8.2</version></dependency>
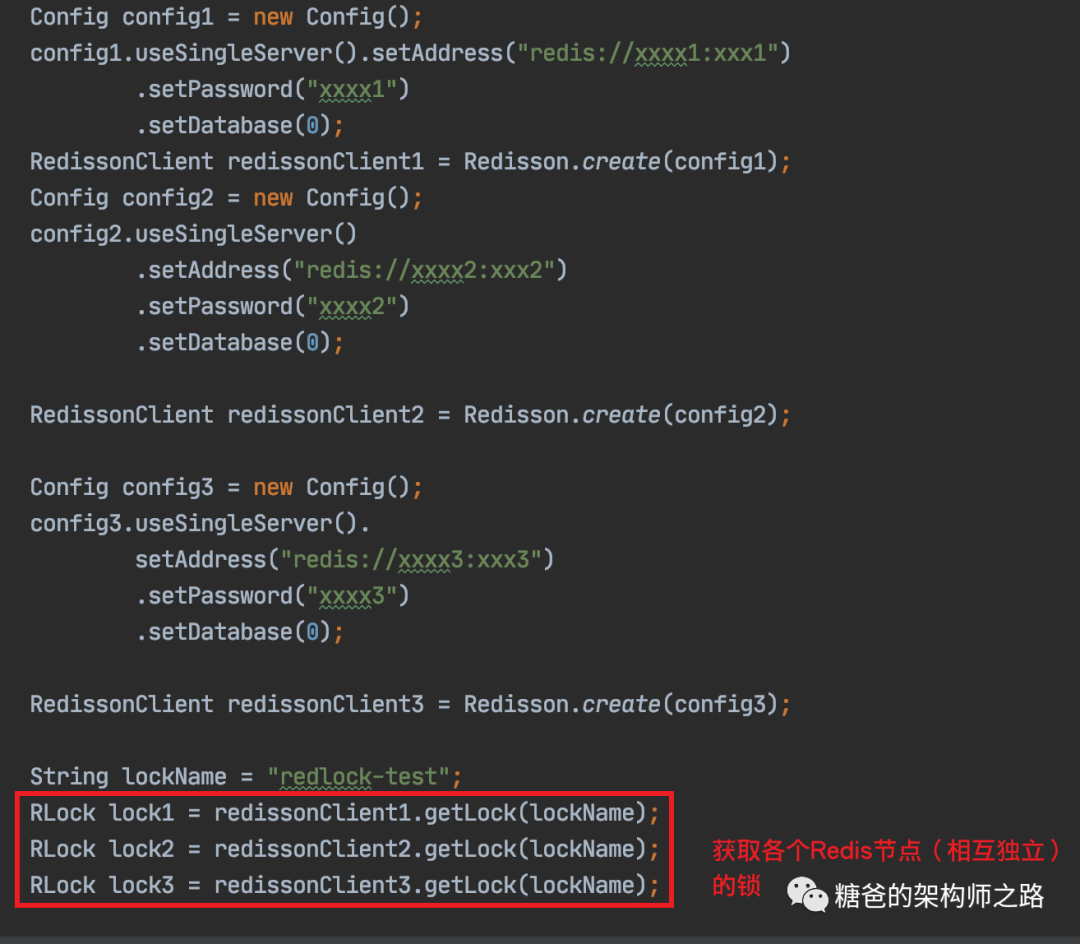
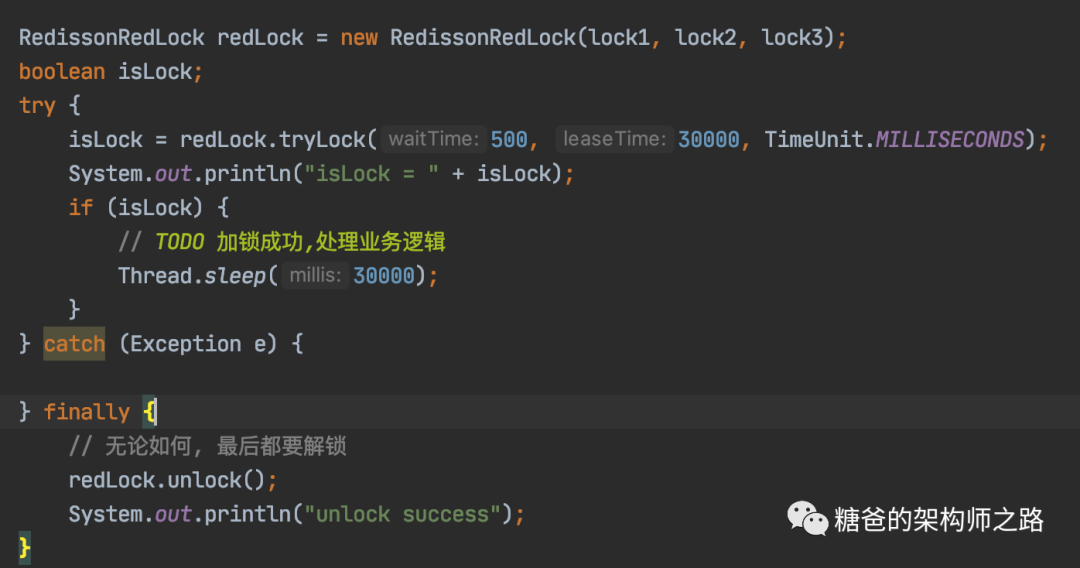
除了RedLoack外,Redisson为了方便分布式锁的使用,还实现了其他类型的锁
可重入锁
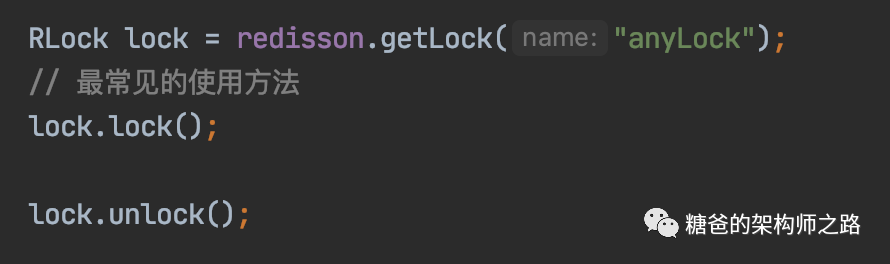
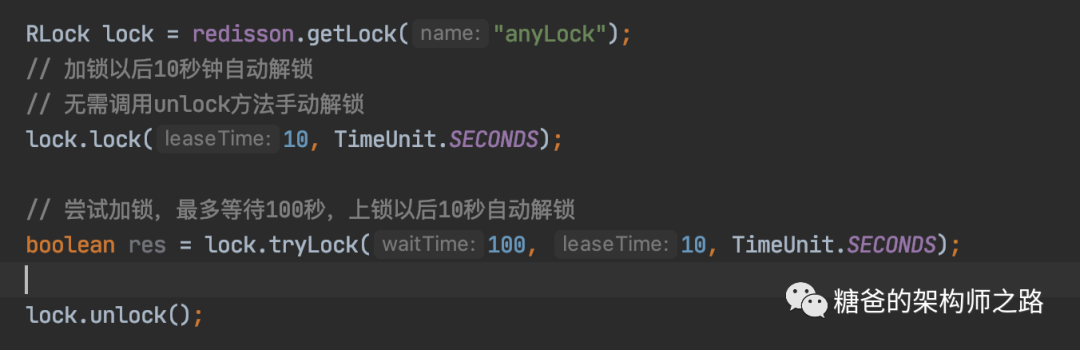
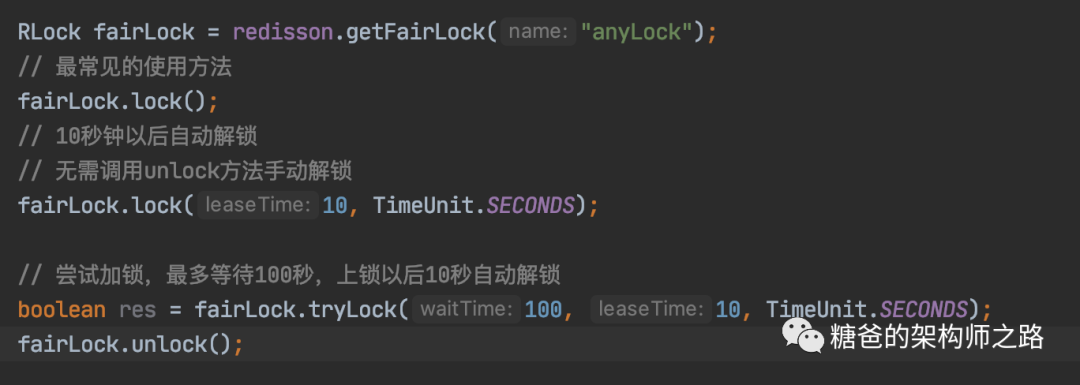
联锁
RLock lock1 = redissonInstance1.getLock("lock1");RLock lock2 = redissonInstance2.getLock("lock2");RLock lock3 = redissonInstance3.getLock("lock3");RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);// 同时加锁:lock1 lock2 lock3// 所有的锁都上锁成功才算成功。lock.lock();...lock.unlock();
下面是我摘要的一些内容:

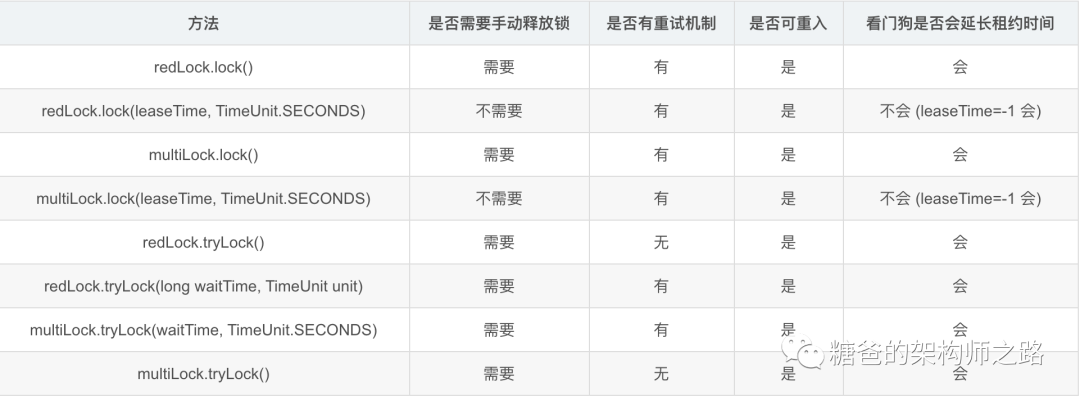
Redisson的整体流程图
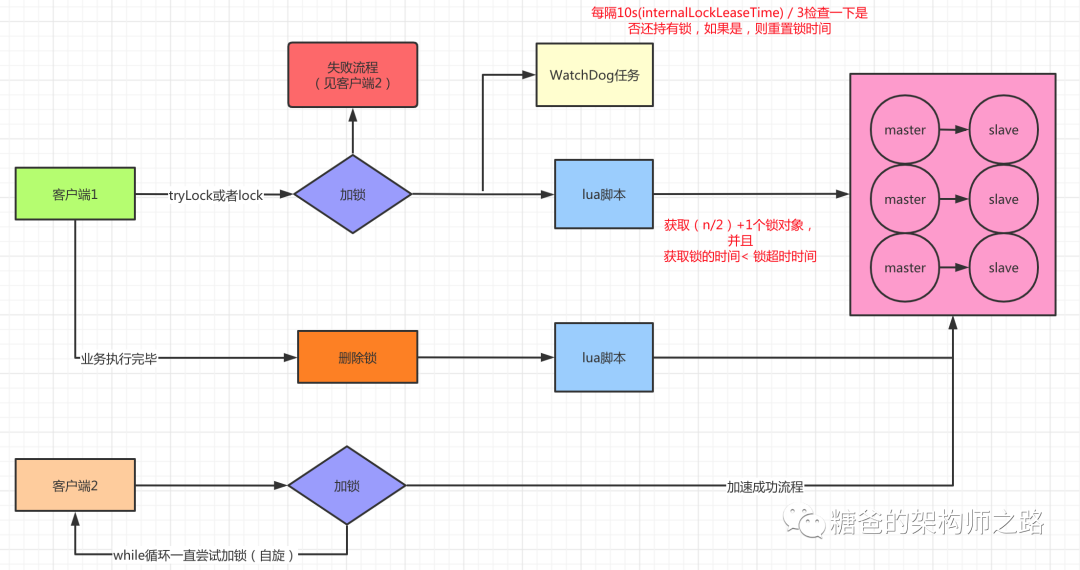
遗留的问题
其实讲到这里,Redis针对分布式锁的实现方案已经非常完美了,不论是从性能上,还是从锁的机制上。可以说都可以满足我们的大部分情况。那是不是就可以说Redis实现分布式锁没有任何问题呢?答案自然是否定的,对于Redis的分布式锁而言,还是有以下缺点:
它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。 Redis的设计定位(AP模型+BASE)决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮,尤其是在主备切换,异步备份数据时,可能会出现多个客户端同时获取到锁的情况。 即便使用Redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题。具体可以自行GoogleRedis之父和另一位分布式领域的大牛之间的讨论《How to do distributed locking》
以上就是今天的全部内容,下一篇内容会详细的说一下另一种,即Zookeeper针对分布式锁的实现方案。小胖友们敬请期待吧~谢谢阅读~~

