




写在前面
 。年三十拿出时间来学习,也是一件挺酷的事情
。年三十拿出时间来学习,也是一件挺酷的事情
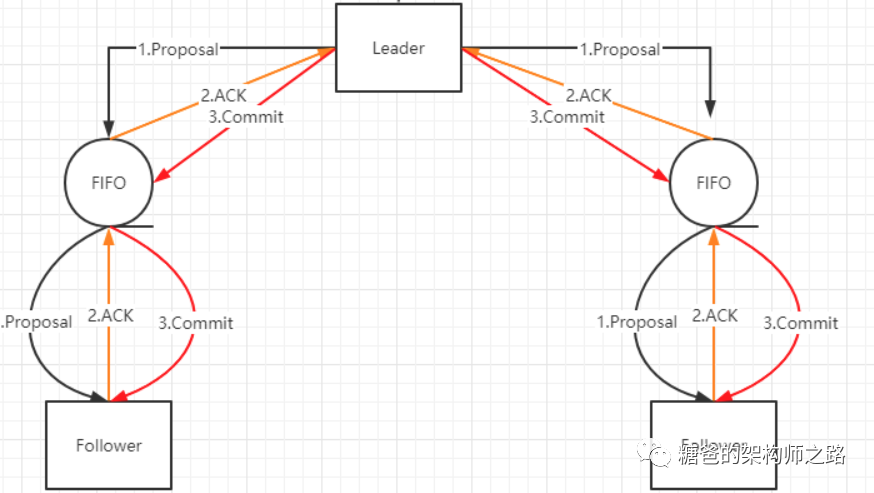
所有正常运行的服务器,要么成为Leader,要么成为Follower并和Leader保持同步。Leader服务器需要确保所有的Follower服务器能够接收到每一条事务Proposal,并且能够正确地将所有已经提交了的事务Proposal在内存中执行。具体点说,Leader服务器会为每一个 Follower 服务器都准备一个队列,并将那些没有被各Follower服务器同步的事务以Proposal消息的形式逐个发送给 Follower服务器,并在每一个Proposal消息后面紧接着再发送一个Commit 消息,以表示该事务已经被提交。等到Follower服务器将所有其尚未同步的事务 Proposal 都从 Leader 服务器上同步过来并成功保存到本地后,Leader服务器就会将该 Follower 服务器加入到真正的可用Follower列表中,并开始之后的其他流程。如下是正常情况下的数据同步流程图:
一个事务在Leader上提交了,并且过半的Follower都响应Ack了,但是Leader在Commit消息发出之前宕机了。
假设一个事务在 Leader 提出之后,Leader 宕机了。
确保已经被 Leader 提交的 Proposal 必须最终被所有的 Follower 服务器提交
确保丢弃已经被 Leader 提出的但是没有被提交的 Proposal
所以,根据上述要求Zab协议需要保证选举出来的Leader需要满足以下条件
新选举出来的 Leader 不能包含未提交的 Proposal 。即新选举的 Leader 必须都是已经提交了 Proposal 的 Follower 服务器节点
新选举的 Leader 节点中含有最大的 zxid
为了保证上述两个条件可以高效的被实现,ZAB协议引入了zxid。关于zxid在漫谈ZAB协议——选举中已经进行了详细的介绍,这里我们在简单回顾一下。
zxid是一个64位的数字,其中低32 位可以看作是一个简单的单调递增的计数器,针对客户端的每一个事务请求,Leader服务器在产生一个新的事务Proposal的时候,都会对该计数器进行加1操作。而高32位则代表了Leader 周期epoch的编号。每当选举产生一个新的Leader服务器,就会从这个Leader服务器上取出其本地日志中最大事务 Proposal的zxid,并从该zxid中解析出对应的epoch 值,然后再对其进行加1操作,之后就会以此编号作为新的 epoch,并将低32位置0来开始生成新的zxid。ZAB协议中的这一通过epoch编号来区分 Leader 周期变化的策略,能够有效地避免不同的Leader 服务器错误地使用相同的zxid编号提出不一样的事务 Proposal的异常情况,这对于识别在Leader 崩溃恢复前后生成的 Proposal非常有帮助,大大简化和提升了数据恢复流程。
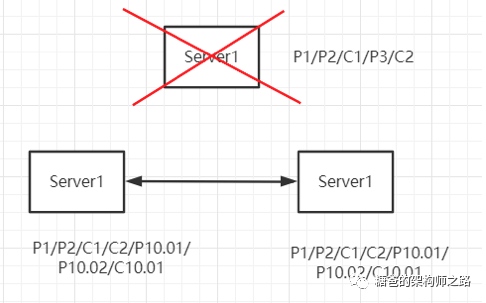
基于这样的策略,当一个包含了上一个 Leader 周期中尚未提交过的事务 Proposal 的服务器启动时,其肯定无法成为 Leader,原因很简单,因为当前集群中一定包含一个 Quorum集合,该集合中的机器一定包含了更高 epoch的事务 Proposal,因此这台机器的事务 Proposal 肯定不是最高,也就无法成为 Leader 了。当这台机器加入到集群中,以Follower 角色连接上Leader服务器之后,Leader 服务器会根据自己服务器上最后被提交的 Proposal来和 Follower 服务器的 Proposal进行比对,比对的结果当然是 Leader 会要求 Follower 进行一个回退操作——回退到一个确实已经被集群中过半机器提交的最新的事务 Proposal。举个例子来说,如下图,集群正常运行过程中的某一个时刻, Server1 是 Leader 服务器,其先后广播了消息 P1、P2、C1、P3 和 C2。假设初始的 Leader 服务器 Server1 在提出了一个事务 P3 之后就崩溃退出了,从而导致集群中的其他服务器都没有收到这个事务 Proposal。于是,当 Server1 恢复过来再次加入到集群中的时候,ZAB 协议需要确保丢弃 P3 这个事务。
数据同步方式
peerLastZxid:该 Follower服务器最后处理的 zxid。
minCommittedLog:Leader 服务器Proposal缓存队列committedLog中的最小zxid。
maxCommittedLog:Leader服务器Proposal缓存队列committedLog中的最大zxid。
ZooKeeper集群数据同步通常分为四类
直接差异化同步(DIFF 同步)
场景:minCommittedLog < peerLastZxid < maxCommittedLog
先回滚再差异化同步(TRUNC+DIFF 同步)
场景:Leader 服务器在已经将事务记录到了本地事务日志中,但是没有成功发起 Proposal流程的时候就挂了。即上面针对异常数据处理举例的那种情况。
仅回滚同步(TRUNC同步)
场景:peerLastZxid > maxCommittedLog
全量(快照)同步(SNAP同步)
场景:peerLastZxid < maxCommittedLog或Leader 服务器上没有提议缓存队列,peerLastZxid != lastProcessedZxid(Leader 服务器数据恢复后得到的最大 ZXID)。
在初始化阶段,Leader 服务器会优先初始化以全量同步方式来同步数据,之后会根据 Leader和Follower 服务器之间的数据差异情况来决定最终的数据同步方式。
总结

 ~~
~~