




写在前面
索引覆盖
要了解索引覆盖,需要先了解几个索引的基础知识
B+树索引
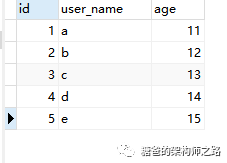
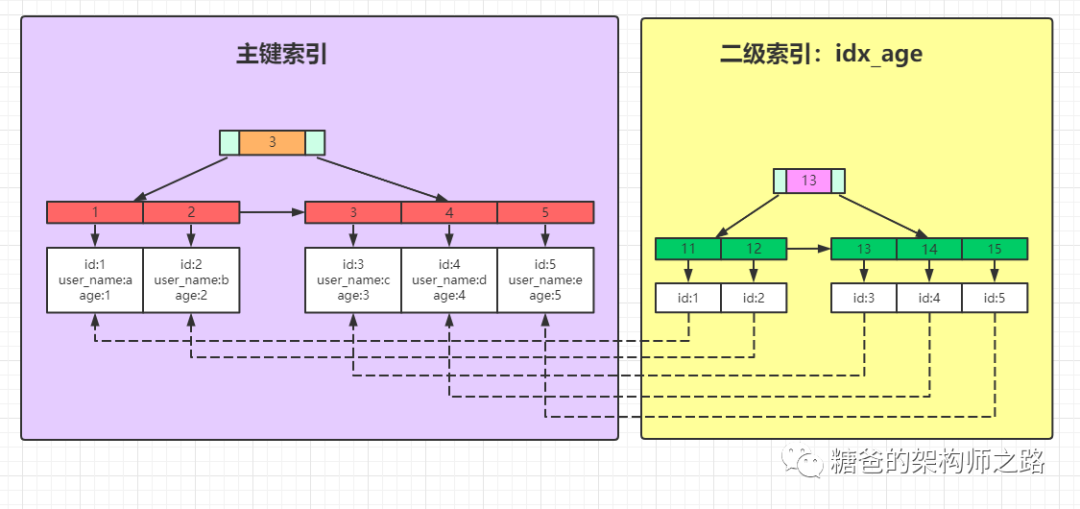
主键索引的叶子结点存的是整条记录,如上图紫色部分所示
非主键索引的叶子结点存的是主键的地址值,根据二级索引叶子结点中的地址可以找到主键索引中的这一条数据。所以非主键索引也被称为二级索引,如上图右半边黄色部分所示
select *from lyb_test where id = 2select *from lyb_test where age = 12
第一条语句使用主键作为检索条件,即为主键查询,根据上图所示我们知道,如果是主键查询,我们只需要搜索左边这颗主键索引树即可快速查询到id=2的这条数据
第二条语句使用的是二级索引、即age作为检索条件,这和主键查询有什么区别呢?如果是二级索引查询,则需要先搜索左侧的age索引树,得到id的值为2,再到右侧的主键索引树搜索一次。
像第二种查询语句这样,通过非主键索引查询数据时,我们先通过非主键索引树查找到主键值,然后再在主键索引树搜索一次(根据rowid再次到数据块里取数据的操作),这个过程称为回表,也就是说非主键索引查询会比主键查询多搜索一棵树
索引覆盖
结合上面的知识储备,我们进一步来优化一下刚才的SQL
select *from lyb_test where age = 12
select id from lyb_test where age = 12
由于查询的值是ID,而id的值已经在age索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,当SQL语句的所有查询字段(select列)和查询条件字段(where子句)全都包含在一个索引中,便可以直接使用索引查询而不需要回表。即在这个查询里,索引age已经“覆盖了”我们的查询需求,故称为索引覆盖。
还是基于刚才的表结构和数据,我们现在针对user_name和age建立联合索引,索引建立之后,查询姓名以b开头且年龄大于等于13的用户信息,SQL语句如下:
select * from user_table where username like 'b%' and age >= 13
根据(username,age)联合索引查询所有满足名称以"b"开头的索引,然后回表查询出相应的全行数据,再筛选出满足年龄大于等于13的用户数据。如果表中user_name以b开头的数据有n条,则需要回表n次
根据(username,age)联合索引查询所有满足名称以"b"开头的索引,然后直接再筛选出年龄大于等于13的索引,之后再回表查询全行数据。经过两次筛选之后,回表次数一定小于上述第一种情况
SET optimizer_switch = 'index_condition_pushdown=off';// 关闭SET optimizer_switch = 'index_condition_pushdown=on';// 开启
索引下推一般可用于所求查询字段(select列)不是/不全是联合索引的字段,查询条件为多条件查询且查询条件子句(where/order by)字段全是联合索引。假设表t有联合索引(a,b),下面语句可以使用索引下推提高效率
select * from t where a > 2 and b > 10
上述就是索引覆盖、回表、索引下推的相关概念和使用场景。当然针对MySQL的索引优化还有其他非常多的方式,我们可以在之后的文章中讨论。本文到这里就结束啦,谢谢小伙伴们的阅读~
