




目标网址:
aHR0cHM6Ly93d3cuY2xzLmNuL3RlbGVncmFwaA==
先打开网站,抓包发现返回数据为标准的 json 格式,甚好,乍一看很好抓取,写一个循环翻页即可,实际操作中却无法获取翻页数据,仔细查看参数,一个熟悉的字段出现了:sign,根据以往经验,sign 的值要做到每次请求都不同,大概率和时间戳有关,看来要抓数据首先得弄清楚 sign 是怎么生成的了,带着疑问我们往下看。 请求参数中确实有时间戳,按照 js 逆向的老套路先搜搜看:
请求参数中确实有时间戳,按照 js 逆向的老套路先搜搜看:
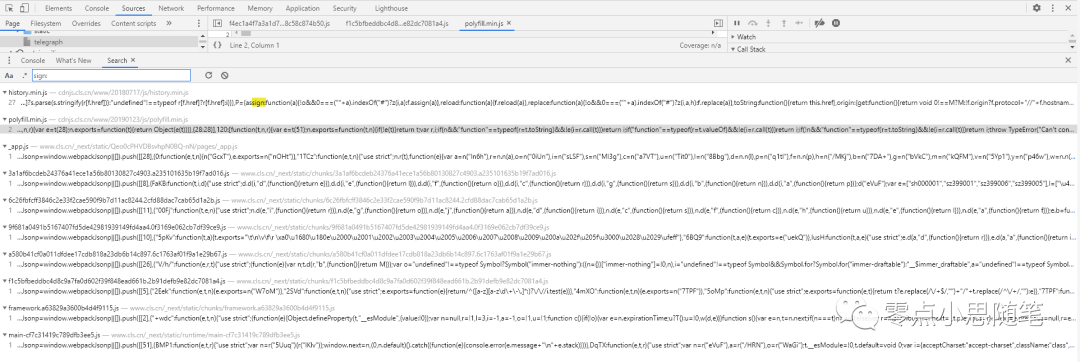
有很多文件中都有 sign,挨个打开查看,在有 sign 的地方打上断点,终于在这里找到了 sign 加密的地方。
主要的加密逻辑在这里:
sign: g(l({}, r))
接下来看看这些方法是怎么实现的,按 F11 进入函数内部: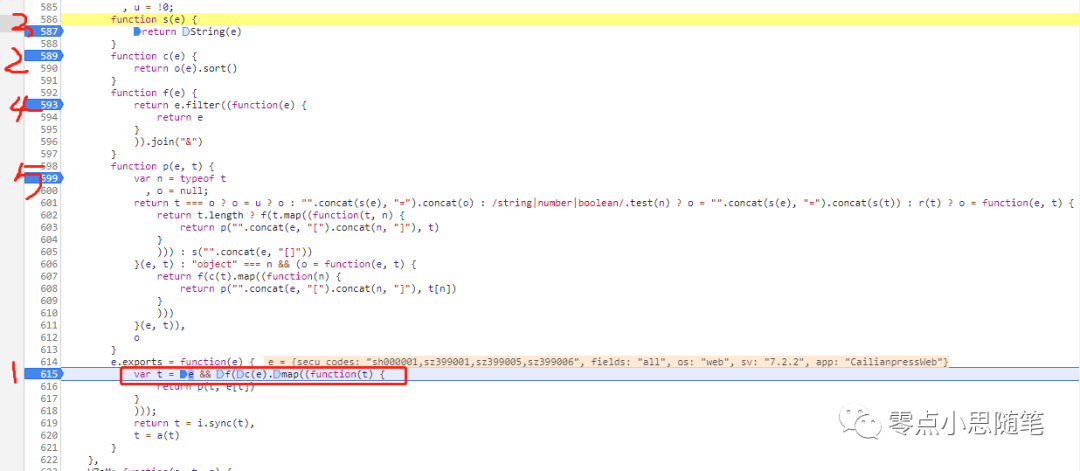 这里的 1-5 步骤最终实现的是把参数排序并按&拼接
这里的 1-5 步骤最终实现的是把参数排序并按&拼接 拼接好的结果当作参数传入下面这个函数:
拼接好的结果当作参数传入下面这个函数:
i.sync(t)
到这里似乎还没涉及到加密的过程,别慌,F11 接着往下走: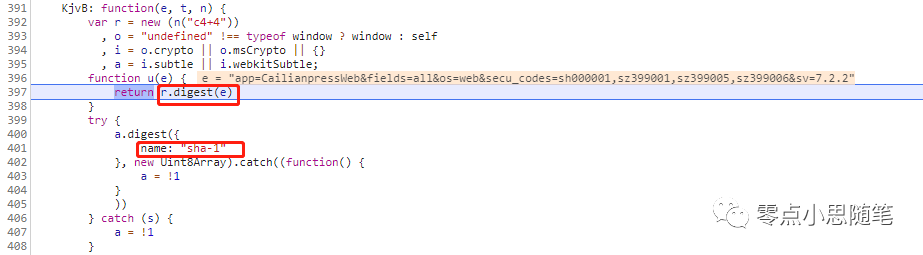 这里出现了 digest 和 sha-1,r.digist(e)执行结束后:
这里出现了 digest 和 sha-1,r.digist(e)执行结束后:
 到这里大胆猜测他是 sha-1 加密来验证,在该网站众多请求中,有一个请求的参数是固定的,暂且拿它来做验证,它的参数为:
到这里大胆猜测他是 sha-1 加密来验证,在该网站众多请求中,有一个请求的参数是固定的,暂且拿它来做验证,它的参数为:
{
"app": "CailianpressWeb",
"os": "web",
"rever": 1,
"sv": "7.2.2",
"type": "industry",
"way": "change",
"sign": "74710c1f5c0d69fa53b231a3a1bba607"
}
排序拼接后:app=CailianpressWeb&os=web&rever=1&sv=7.2.2&type=industry&way=change
在线加密测试:
sha-1 加密结果为:
f269128310e062d5952d641528ddae3138230466
这最后一步是把上面加密的结果传入 a(t) 这个函数:
F11 进入函数内部去看看 看到这里的 t.bytesToHex(r) 中的 to hex ,极大概率是 md5 加密:
看到这里的 t.bytesToHex(r) 中的 to hex ,极大概率是 md5 加密:
md5 加密结果为:
74710c1f5c0d69fa53b231a3a1bba607
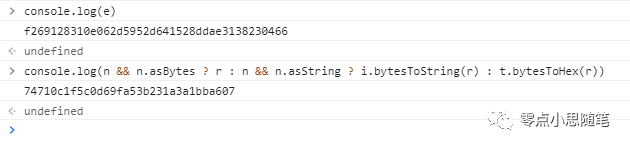
调试输出结果:
返回值:

Console 打印
分析到这一步,加密过程已经很清楚了:
参数排序、拼接 拼接后的结果先进行 sha-1 加密 sha-1 加密结果进行 md5 加密
其他请求也是一样的,不过就是加入时间戳而已。
Python 实现参数拼接、排序
def params_join(params):
temps = [str(key) + '=' + str(value) for key, value in params.items()]
temps = '&'.join(temps)
temp_split = temps.split("&")
temp_sort = sorted(temp_split)
result = '&'.join(temp_sort)
return result
if __name__ == '__main__':
param = {
"app": "CailianpressWeb",
"os": "web",
"rever": 1,
"sv": "7.2.2",
"type": "industry",
"way": "change",
}
params_join(param)
文章转载自零点小思随笔,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
