




目标网址:
aHR0cHM6Ly9oYW9odW8uamlucml0ZW1haS5jb20vdmlld3MvcHJvZHVjdC9pdGVtP2lkPTMzODAyODQ5MDY2NzU1MDM3NDAmcGFnZV9pZD0zMzgwMjg1NDczNTYxMTMyMTA3Jm9yaWdpbl90eXBlPTE=
首先打开 F12 ,查看加密字段
token: b34323eaa8af06860ac231d719f9daf6
token 字段,一个很中规中矩的字段,还是老方法,先搜搜看,只要 js 文件中出现,极大概率就是加密位置:
在加密位置,打上断点并调试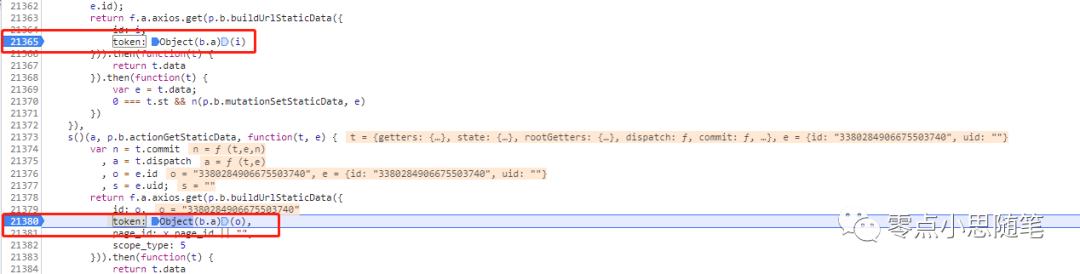 token 由 token: Object(b.a)(o) 生成。
token 由 token: Object(b.a)(o) 生成。
接下来追入函数内部去看看具体是怎么实现的。按 F11 进入
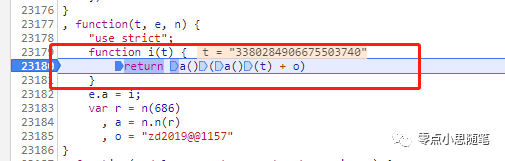 函数 function i(t) 的返回值 a()(a()(t) + o) 就是 token 值,这里 的参数 t 就是商品 id,o 的值也是固定的且为:"zd2019@@1157"。
函数 function i(t) 的返回值 a()(a()(t) + o) 就是 token 值,这里 的参数 t 就是商品 id,o 的值也是固定的且为:"zd2019@@1157"。
这里主要处理逻辑是 a():
先把参数 t 传入 a(),假设返回值为 x x 和 参数 o 做字符串拼接 最后把拼接好的字符串再传入 a()
那么 a() 这个函数的内部实现就至关重要了,下面按 F11 进入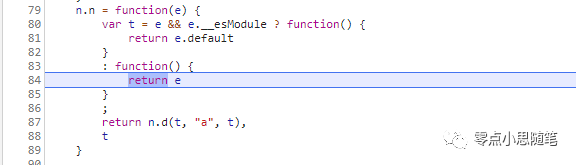 这里还看不出具体加密信息,不要着急,鼠标移到函数返回值 e 上面,发现这个 e 是一个函数,再按 F11 进入
这里还看不出具体加密信息,不要着急,鼠标移到函数返回值 e 上面,发现这个 e 是一个函数,再按 F11 进入 果然功夫不负有心人,看到 MD5 关键字,再结合上面我们对 a() 的分析,其加密逻辑已然明了,按照分析步骤实现加密过程:
果然功夫不负有心人,看到 MD5 关键字,再结合上面我们对 a() 的分析,其加密逻辑已然明了,按照分析步骤实现加密过程:
id 3380284906675503740 先进行 MD5 加密--->x x + zd2019@@1157 --->y 最后 y 进行 MD5 加密

f27a5bfc7019c7de4c37042507e75b93 和 zd2019@@1157 拼接后再加密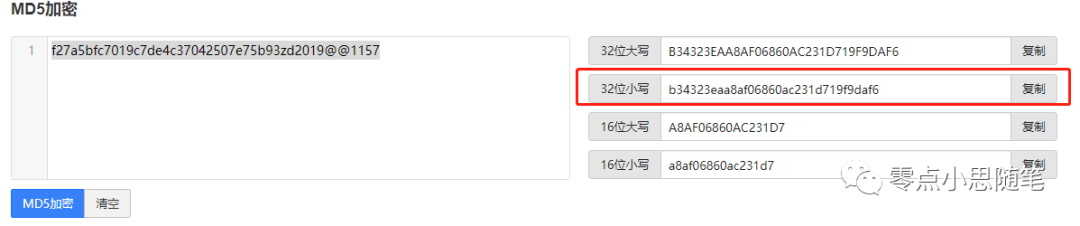 按照分析最后加密结果为:b34323eaa8af06860ac231d719f9daf6
按照分析最后加密结果为:b34323eaa8af06860ac231d719f9daf6
现在把浏览器端的调试继续进行到最后,来验证上面的结果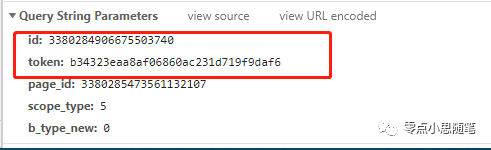
 Python 实现
Python 实现
import hashlib
def str_md5(params):
# s.encode()#变成bytes类型才能加密
m = hashlib.md5(params.encode())
result = m.hexdigest()
return result
if __name__ == '__main__':
id_str = '3380284906675503740'
step_1 = str_md5(id_str)
step_2 = step_1 + "zd2019@@1157"
token = str_md5(step_2)
print(token)

文章转载自零点小思随笔,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
