




上一章给大家了简单介绍了一下Zookeeper,以及单节点安装与一些基本用法,那本章将围绕Zookeeper的选举机制展开描述。。。
01
—
Zookeeper的集群搭建
说到Zookeeper的选举机制,首先我们需要搭建一个Zookeeper集群,配置与单节点配置相差无几,只不过需要在zoo.cnf中增加如下配置(对于单节点安装不清楚的伙伴自行翻阅《初识ZooKeeper(一)》):
[root@hadoop01 conf]# vi zoo.cfgserver.1=hadoop01:2888:3888server.2=hadoop02:2888:3888server.3=hadoop03:2888:3888
保存退出,然后将配置好的zookeeper scp到另外两个节点上(已做ip与主机名映射,至于怎么映射,请咨询度娘 ),然后分别启动,分别查看各个节点的状态:
),然后分别启动,分别查看各个节点的状态:
hadoop01:
[root@hadoop01 bin]# ./zkServer.sh statusJMX enabled by defaultUsing config: Using config: home/software/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower
hadoop02:
[root@hadoop02 bin]# ./zkServer.sh statusJMX enabled by defaultUsing config: Using config: home/software/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: leader
hadoop03:
[root@hadoop03 bin]# ./zkServer.sh statusJMX enabled by defaultUsing config: Using config: home/software/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower
02
—
Zookeeper的节点角色与状态
Zookeeper 节点有三种角色:
| 角色 | 描述 |
leader(领导者) | Zookeeper集群的leader节点,负责响应所有对ZooKeeper状态变更的请求。它会将每个状态更新请求进行排序和编号,以便保证整个集群内部消息处理的FIFO。 |
follower(追随者) | Zookeeper集群的follower节点,负责响应本服务器上的读请求,还要处理leader的提议,并在leader提交该提议时在本地也进行提交。 |
observer(观望者) | Zookeeper集群的observer节点,观察集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给leader节点进行处理。observer不会参与任何形式的投票,包括事务请求的投票和leader选举的投票。 |
Zookeeper节点有四种状态:
| 状态 | 描述 |
| leading | 领导者状态,说明当前服务器角色是leader。 |
| following | 跟随者状态,说明当前服务器角色是follower。 |
looking | 寻找leader状态,说明当前服务器角色认为当前集群中没有leader,因此需要进入leader选举状态。 |
| observing | 观察者状态。说明当前服务器角色是Observer。 |
03
—
Zookeeper的leader选举机制
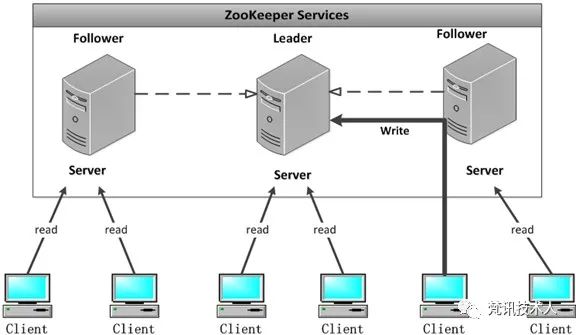
(图片来源于网络)
Zookeeper在3.4.0版本后使用的选举算法为FastLeaderElection,有两个触发方式:
集群刚启动。
leader服务器挂掉。
3.1 集群刚启动
server1启动时无法完成选举(至少两台服务器);
server2启动时,此时与server1进行通信,尝试寻找leader,每个服务器改变状态为looking;
每个server都随机一个有效时间段将自己作为leader然后给自己投票,投票时包含myid(比如有三台服务器,编号分别是1,2,3,编号越大,选举算法中权重越大)和Zxid(服务器中存放的最大数据ID,值越大说明数据越新,选举算法中权重越大),之后再将自己的投票发给集群中其他角色;
每个server接受来自不同节点发送过来的选票,首先判断选票是否有效(比如是否是本轮选票、是否是来自looking状态的服务器等),并与自己的myid和Zxid作比较,先比较Zxid,哪个服务器的Zxid最大则优先胜出,更改自己的状态为leading,成为leader,剩下节点状态改为following;若是Zxid相同,则比较myid,同理选出leader。
3.2 leader服务器挂掉
leader服务器挂掉后,集群停止对外服务,进行leader选举;
首先需要注意的是,在集群正常对外提供服务时,节点已有3个;
之后的选举流程同3.1选举流程。
04
—
Zookeeper的特性
过半性:
过半选举:只有一个节点胜过一半或者以上的节点的时候才能成为leader;
过半存活:只有当集群的节点存活一半以上的时候才能对外提供服务;
过半操作:只有当集群中的一半以上的节点同意执行,那么新的操作才会真正的被提交。
一致性:从集群的任意一个节点进入所获取的数据是相同的。
注意:Zookeeper的集群中的节点个数一般是奇数个(小伙伴们阔以了解下为何是奇数个)。
本章节到此就结束了,主要围绕Zookeeper集群的选举机制而做的简单介绍,首先介绍了集群的搭建,然后节点所担任的角色与会出现的状态,最后是Zookeeper的选举机制。在此感谢大家的阅读,同时也欢迎大家在评论区留下你的问题与建议。那么接下来有机会将介绍Zookeeper的ZAB协议以及深入源码看看Zookeeper是如何工作的,敬请期待。
