





最近对Python 方面的新技术非常感兴趣,想知道那些大公司都在使用了哪些python技术及相关技术。在BOSS直聘上搜索“python” 关键字可以看到使用Python的公司的招聘信息,通过分析他们的招聘信息来进行python技术的针对性学习。
BOSS直聘:

效果图:

下面是爬虫的具体步骤:
安装scrapy
具体的使用可以看作者的另一篇博文:
https://blog.csdn.net/qq_37892223/article/details/82766670
分析网站
BOSS 的搜索结果页的url是:
https://www.zhipin.com/c101020100/?query=python&page=3
不难知道,其中 query是查询参数,page是当前页面,根据这两个我们就很好写爬虫了。
开始编写岗位列表页爬虫
生成scrapy项目:
scrapy startproject boss_job
进入项目目录下:
cd boss_job
生成spider
scrapy genspider job_info zhipin.com
在 job_info 爬虫中, start_requests控制起始url:
def start_requests(self):
keyword = 'python'
query_job_url = "https://www.zhipin.com/c101020100/?query={keyword}&page={page}&ka=page-{page}"
for i in range(1, 10):
url = query_job_url.format(keyword=keyword, page=i)
yield Request(url=url)
启动爬虫,进行测试:
import scrapy
from scrapy.crawler import CrawlerProcess
from boss_job.boss_job.spiders.job_info import JobInfoSpider
process = CrawlerProcess() # 括号中可以添加参数
process.crawl(JobInfoSpider)
process.start()
发现全部返回403:

分析可能是user-agent(浏览器头),在setting.py中进行配置:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'boss_job.downloadermiddlewares.user_agent.RandomUserAgentMiddleware': 100,
}
记住,scrapy默认遵守Robots协议,需要关掉此项配置
ROBOTSTXT_OBEY = False
RandomUserAgentMiddleware随机浏览器头设置:
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
def __init__(self):
self.agent = UserAgent()
@classmethod
def from_crawler(cls, crawler):
return cls()
def process_request(self, request, spider):
request.headers.setdefault('User-Agent', self.agent.random)
再次抓取就可以正常访问了:

下面使用xpath解析网页,在parse函数中:
def parse(self, response):
jobs = response.xpath('//div[@class="job-list"]/ul/li')
for job in jobs:
item = BossJobItem()
company_name = job.xpath('div/div[@class="info-company"]/div/h3/a/text()').get()
job_detail_detail_url = job.xpath('div/div[@class="info-primary"]/h3/a/@href').get()
item['company_name'] = company_name
item['job_detail_detail_url'] = self.zhilian_link + job_detail_detail_url
yield item
设置pipeline管道和优先级
custom_settings = {
'ITEM_PIPELINES': {
'boss_job.pipelines.BossJobPipeline': 300,
}
}
> 在pipeline中:class BossJobPipeline(object):
def __init__(self):
self.job_items = []
def process_item(self, item, spider):
self.job_items.append(copy.deepcopy(dict(item)))
return item
def close_spider(self, spider):
with open('job.json', 'w', encoding='utf-8') as file_pipeline:
json.dump(self.job_items, file_pipeline, ensure_ascii=False)
到此为止已经完成了BOSS直聘列表页的抓取了,最终结果为:

下面开始抓取岗位详情页面
分析页面

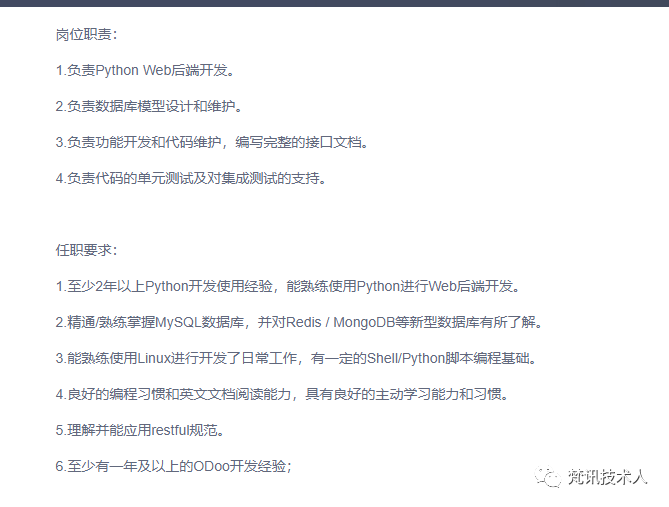
我们要抓取的就是这些 职位描述,岗位职责等信息。
使用命令生成爬虫:
scrapy genspider job_detail zhipin.com在spider中,首先读取json文件获取刚才爬虫抓取到的job详情url:
def get_job_url(self):
with open('job.json', 'r', encoding='utf-8') as file_pipeline:
return json.load(file_pipeline)使用xpath进行解析:
def parse(self, response):
item = BossJobDetailItem()
job_detail = response.xpath('string(//div[@class="detail-content"]//div[@class="text"])').get(
default='').replace('\n', '').replace(' ', '')
company_name = response.xpath('//div[@class="job-sec"]/div[@class="name"]/text()').get(default='')
item['job_detail'] = job_detail
item['company_name'] = company_name
yield item
在pipeline中:
class BossJobDetailPipeline:
def __init__(self):
self.job_items = []
def process_item(self, item, spider):
self.job_items.append(copy.deepcopy(item['job_detail']))
return item
def close_spider(self, spider):
job_details = ''.join(self.job_items)
self.generate_word_count(job_details)
def generate_word_count(self, job_details: str):
# job_details = jieba.cut(job_details)
self.generate_image(job_details)
@staticmethod
def generate_image(job_details):
d = path.dirname(__file__)
backgroud_Image = np.array(Image.open("111.jpg"))
# 绘制词云图
# mask=backgroud_Image, # 设置背景图片
wc = WordCloud(
font_path='font.ttf', # 显示中文,可以更换字体
background_color='white', # 背景色
width=1200,
height=800
# max_words=30, # 最大显示单词数
# max_font_size=60 # 频率最大单词字体大小
).generate(job_details)
# 传入需画词云图的文本
image = wc.to_image()
image.show()
最终的效果图
执行第二个爬虫就可以看到下图:

本爬虫所有的代码都在 作者 Gitbub上,欢迎大家访问:
https://github.com/starryrbs/awesome-scrapy

