




微信搜索“coder-home”或扫一扫下面的二维码,关注公众号,
第一时间了解更多干货分享,还有各类视频教程资源。扫描它,带走我

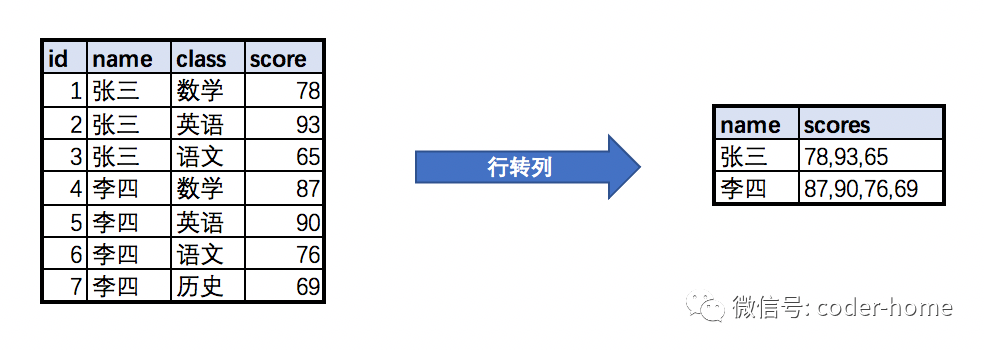
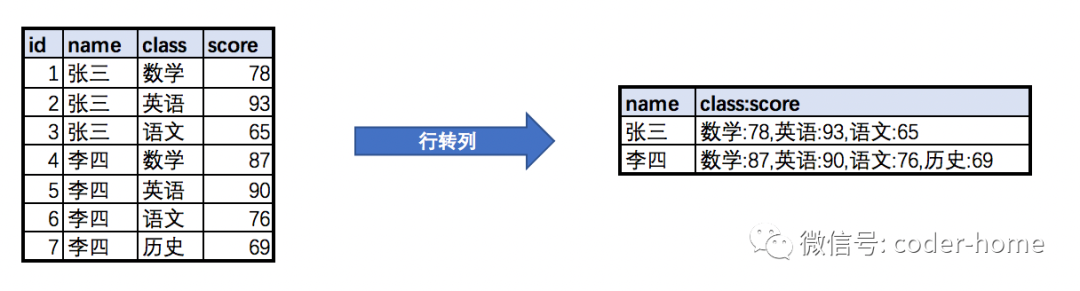
行转列与列转行的概念
什么是行转列
什么是列转行
行转列实验示例
示例一:使用聚合函数
示例二:使用group_concat函数
示例三:使用动态SQL语句块
列转行实验示例
示例一:使用union all功能
示例二:使用substring_index函数
最后总结
行转列与列转行的概念
这里需要重申一下行转列和列转行的区别。有很多的贴子在介绍的时候没有严格的区分,命名介绍的是列转行该如何操作,但是帖子的标题确写的是行转列。自始至终都没有提过列转行的事情。所以,我觉的这里应该有必要做一次区别和认识。
什么是行转列
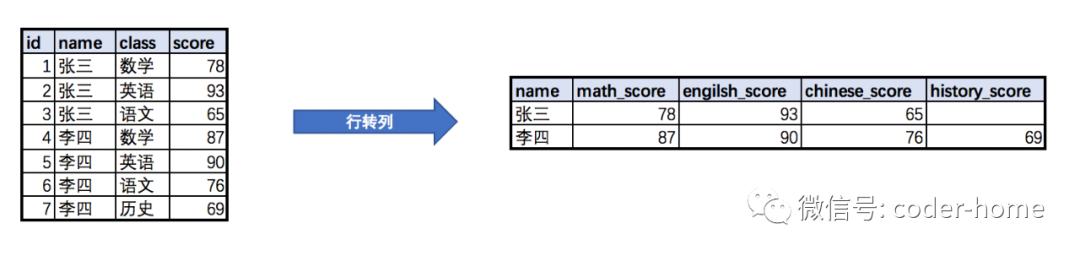
所谓的行转列是指把数据表中具有相同key值的多行value数据,转换为使用一个key值的多列数据,使每一行数据中,一个key对应多个value。
行转列完成后,在视觉上的效果就是:表中的总行数减少了,但是列数增加了。
如下所示的转换过程就是一个简单的行转列的过程:
什么是列转行
所谓的列转行是指把表中同一个key值对应的多个value列,转换为多行数据,使每一行数据中,保证一个key只对应一个value。
列转行完成之后,在视觉上的效果就是:表中的列数减少了,但是行数增加了。
如下所示的转换过程就是一个简单的列转行过程:

行转列实验示例
在进行实验之前,我们需要先准备好我们的实验环境,准备好表和表中的初始化数据。
准备初始化表结构
CREATE TABLE `student_x` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`class` varchar(255) DEFAULT NULL,
`score` int(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;准备初始化表中的数据
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (1, '张三', '数学', 78);
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (2, '张三', '英语', 93);
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (3, '张三', '语文', 65);
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (4, '李四', '数学', 87);
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (5, '李四', '英语', 90);
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (6, '李四', '语文', 76);
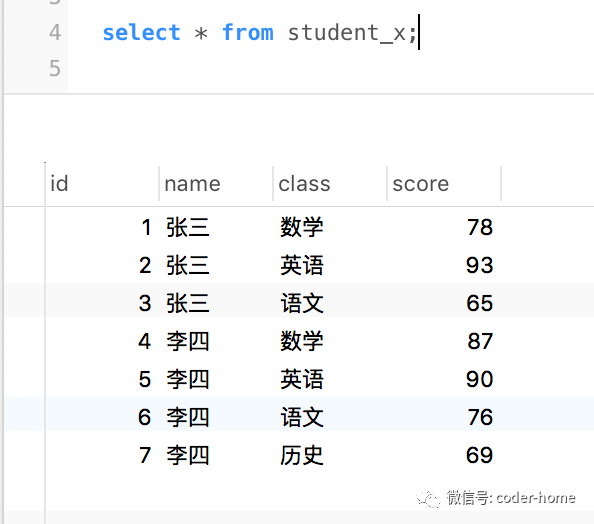
INSERT INTO `student_x`(`id`, `name`, `class`, `score`) VALUES (7, '李四', '历史', 69);进行行转列的实验环境最后如下所示:
示例一:使用聚合函数
我们在这个示例中,使用聚合函数sum、max、min、avg
来完成我们的行转列的需求,具体的实验如下。
下面是我们需要完成行转列的效果图:
使用
case when
语句来拼装新的数据列select name,
case when class = '数学' then score else null end as math_score,
case when class = '英语' then score else null end as engilsh_score,
case when class = '语文' then score else null end as chinese_score,
case when class = '历史' then score else null end as history_score
from student_x;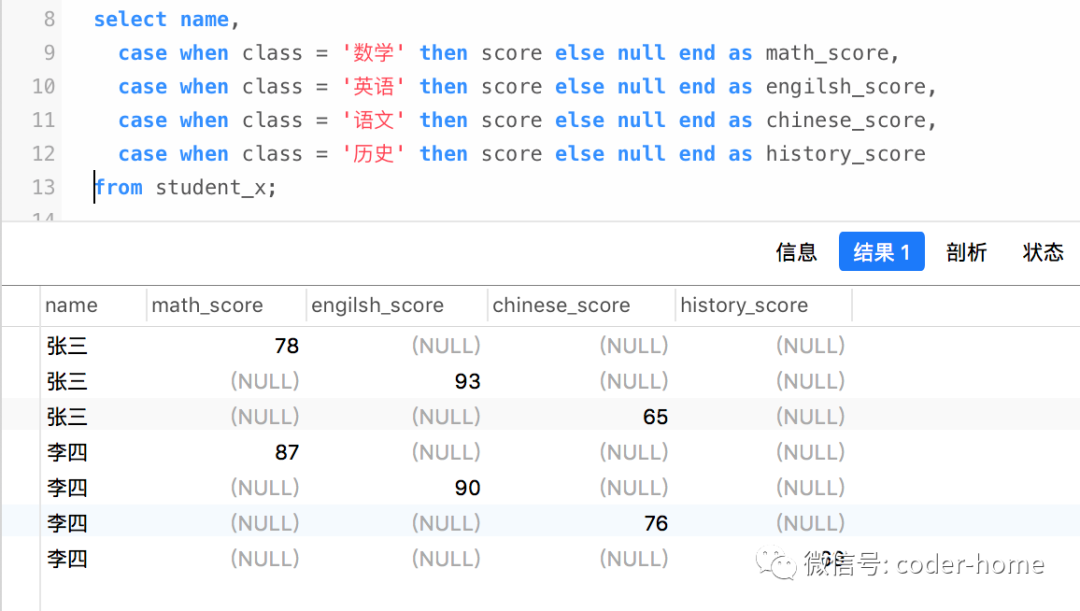
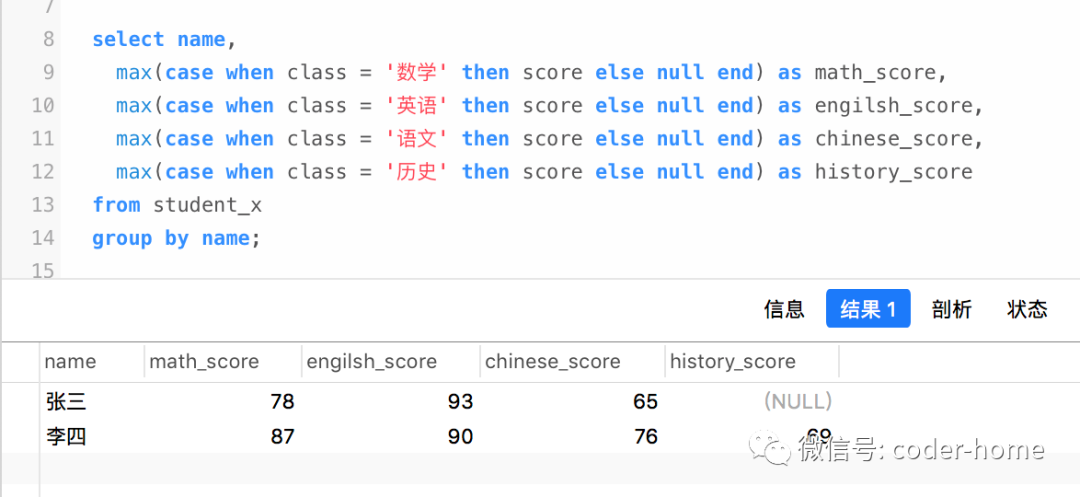
基于上面的效果图,我们需要把数据结果,按照name列进行聚合,让姓名相同的数据行合并为同一行来展示,同时,每一列的科目中,只有一行数据是有成绩的,其他行成绩都是空null,所以他们结合使用max函数,可以达到合并行,并且每列的科目成绩不会因为合并行而影响到最后的每一科目的成绩。实现上述转换的SQL语句如下:
select name,
max(case when class = '数学' then score else null end) as math_score,
max(case when class = '英语' then score else null end) as engilsh_score,
max(case when class = '语文' then score else null end) as chinese_score,
max(case when class = '历史' then score else null end) as history_score
from student_x
group by name;
我们上面使用了
case when
语句来判断,其实if
语句也可以达到case when
语句的效果。如下是使用if
语句的结果:select name,
max(if(class = '数学', score, null)) as math_score,
max(if(class = '英语', score, null)) as engilsh_score,
max(if(class = '语文', score, null)) as chinese_score,
max(if(class = '历史', score, null)) as history_score
from student_x
group by name;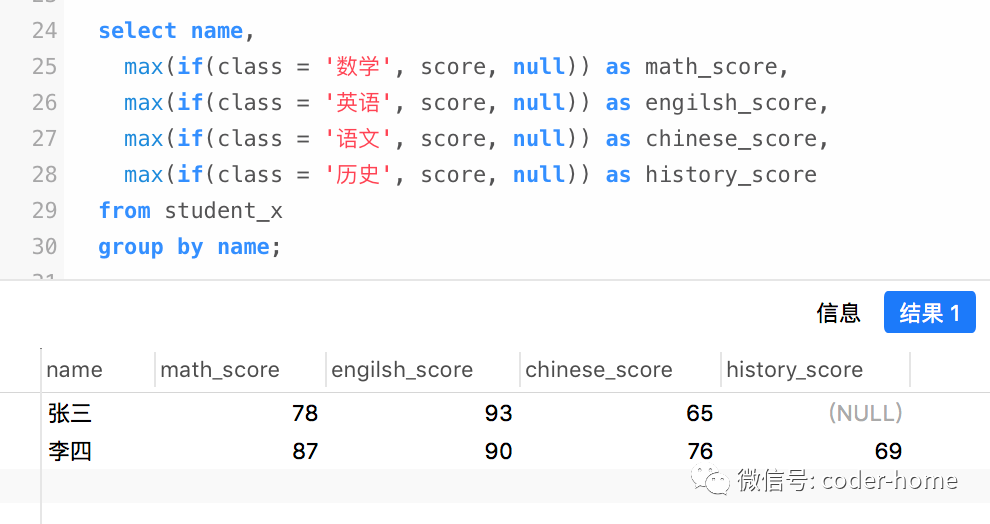
实现过程分析
这里我们使用了聚合函数max,把每一个学生的姓名作为key,进行分组统计。
因为每一个学生对应每一门科目的成绩只有一行记录,所以我们使用聚合函数sum统计后的每一科目的成绩,仍然是该科目单独的成绩。
如果这里每一个学生对应每一门科目有多个成绩记录,这里就不能使用聚合函数max了,如果使用max,最后的结果将是每一个学生对应每一门科目成绩的最大值。
这里之所以使用max的目的是为了达到一个分组的效果。这里的max可以使用sum、min、avg等聚合函数替换掉,它们三个的效果和sum函数的效果在这里是一样的。
总结:上面的这样的实现方式,使大家经常使用的,也是大家最熟悉的一种方式。但是这样的写法有一个问题,就是当我们的科目名称变动或者增加或者减少的时候,我们SQL语句也需要作出对应的修改。因为我们在SQL语句中已经使用了hard code
硬编码的方式把科目的名称给写死了,所以这样的SQL不太灵活。
我们可以参考使用下面的几种写法,每一种写法稍微有点不同,但是这些方式基本都能满足我们的需求。
示例二:使用group_concat函数
上面使用的聚合函数是一种类似于硬编码的方式来实现,为了避免硬编码,我们可以使用gourp_concat
函数来实现,但是这个函数所能实现的效果和使用聚合函数的方式实现的效果有一点点差异,区别的地方就是在展现转换后的列的时候不太一样。具体可以看下面的效果。
我们要达到的效果图如下:
要达到如上的效果图,我们使用group_concat函数即可直接完成,SQL语句如下:
select name,
group_concat(score separator ',') as 'scores'
from student_x
group by name;
我们可以发现上面的转换后的列是合并在一个列中显示的,我们肯能不太清楚各个逗号分隔的成绩分别代表哪个科目。所以我们需要在转换后的列中增加显示科目的名称,达到如下的效果:

达到上图所示的效果图的SQL语句如下所示:
select name,
group_concat(class separator ',') as classes,
group_concat(score separator ',') as scores
from student_x
group by name;
此外我们还可以科目名称和科目成绩放在一起,然后以逗号分隔显示,这样能够更清楚的看到每一个科目对应的成绩是多少。达到如下图所示的效果:
如下的SQL就可以满足上面图片所示的效果:
select name,
group_concat(class,':',score separator ',') as 'class:score'
from student_x
group by name;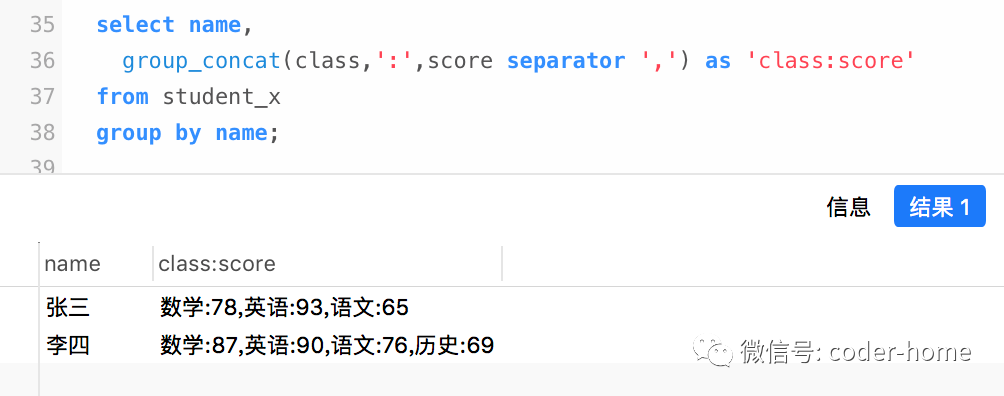
总结:使用group_concat
函数所能达到的效果,和使用聚合函数相比,它不需要因为科目的变动而修改SQL语句,所以它可能更灵活一些。同时,它也有自己的缺点。那就是它的列展现的方式和使用聚合函数相比,不能分开展现,只能以指定的分隔符来连接起来放在一列展现。
当然对于如果我们需要使用分开的列来展现转换后的各个科目的成绩,我们基于group_concat函数转换后的结果,再结合substring
函数或者substring_index
函数来对结果列进行截取和拆分来实现把一列分为多列展示的效果。但是这样的效果有有点hard code
函数的效果了,因为在截取字符串的时候,需要使用指定从哪里开始截取,截取到哪里,截取第几个元素等问题。
示例三:使用动态SQL语句块
其实,在我们想对数据进行“行转列”的过程中,我们真正的难点在于不知道每一个学生到底是选修了几个科目,并且不知道这几个科目具体是什么科目,也就导致我们不知道我们的select后面的字段到底需要写哪些字段。
如果我们能够把select name,[colums] from student_x group by name;
语句中的columns
给准确定位到是哪些字段,那么我们的SQL也就完成了90%
。所以接下来我们需要动态的去拼装我们的columns字段内容。
动态拼装SQL语句的过程如下:
我们要达成如下的行转列的效果:
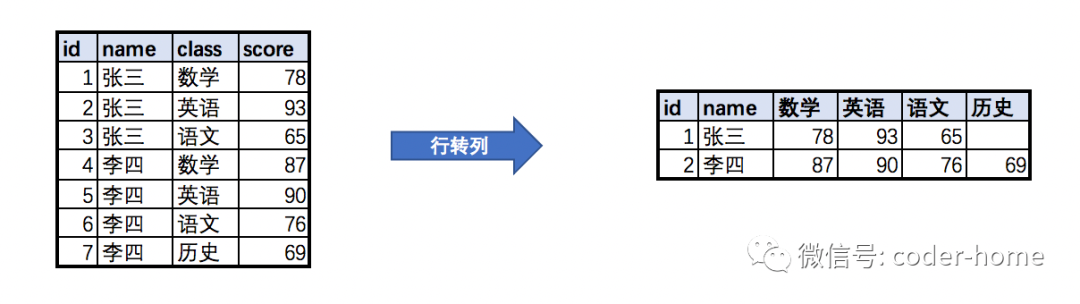
首先确认一下,学生所选择的所有的科目有哪些,我们使用distinct语句来得到这个结果集合。
select distinct class from student_x;
也就是说,所有的学生,他们选项的课程无非就上述4中课程中的一种或者多种。我们在select后面的columns字段,最多的情况下,也就是拼装这4个课程。而对于没有选项其中某一门课程的学生来说,他对应的这个没有选择的课程的成绩为空null或者0。
那么我们使用动态拼装这个columns的结果的SQL语句如下:
set @select_columns = ''; -- 定义变量
select
@select_columns := concat(@select_columns,'sum(if(class= \'',class,'\',score,null)) as ',class, ',') as select_column -- 赋值的时候,使用concat函数连接最后的字段集合
from (
select distinct class from student_x -- 统计去重后的科目名称集合
) as t; -- 为变量赋值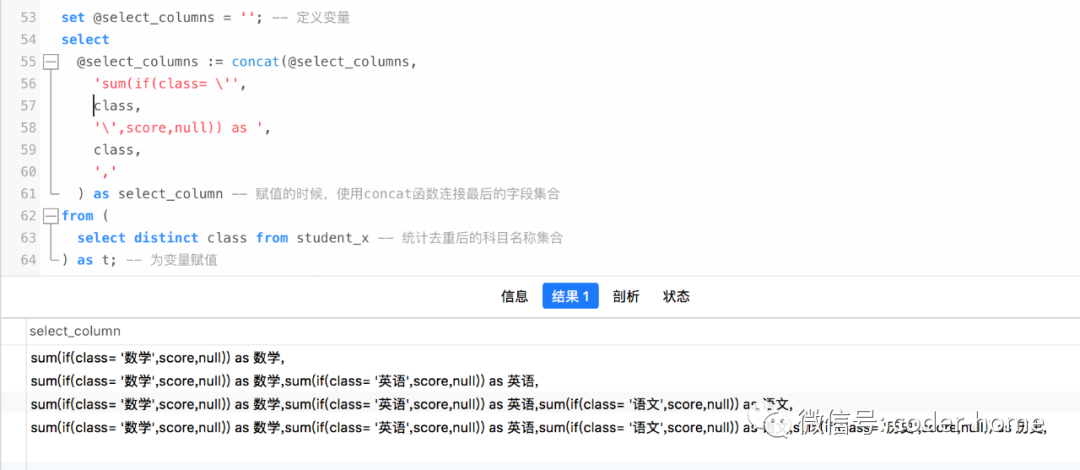
select @select_columns; -- 查看变量结果

拼装最后完整的行转列的SQL语句,SQL和结果如下所示:
set @select_sql := concat('select name, ',
substring(@select_columns, 1, char_length(@select_columns) - 1),
' from student_x group by name;'
); -- 使用concat函数,拼装SQL语句
select @select_sql; -- 查看最后拼装的完整的SQL语句
最后执行SQL语句如下:
-- 准备执行SQL语句
prepare stmt from @select_sql;
execute stmt; -- 执行SQL语句
deallocate prepare stmt; -- 释放变量资源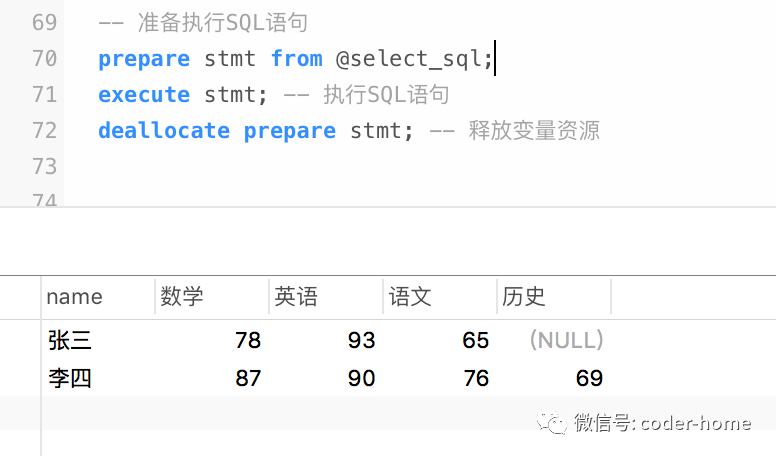
最后合在一起的SQL语句如下:
set @select_columns = ''; -- 定义变量
select
@select_columns := concat(@select_columns,'sum(if(class= \'',
class,'\',score,null)) as ',class, ',') as select_column -- 赋值的时候,使用concat函数连接最后的字段集合
from (
select distinct class from student_x -- 统计去重后的科目名称集合
) as t; -- 为变量赋值
select @select_columns; -- 查看变量结果
set @select_sql := concat('select name, ',
substring(@select_columns, 1, char_length(@select_columns) - 1),
' from student_x group by name;'
); -- 使用concat函数,拼装SQL语句
select @select_sql; -- 查看最后拼装的完整的SQL语句
-- 准备执行SQL语句
prepare stmt from @select_sql;
execute stmt; -- 执行SQL语句
deallocate prepare stmt; -- 释放变量资源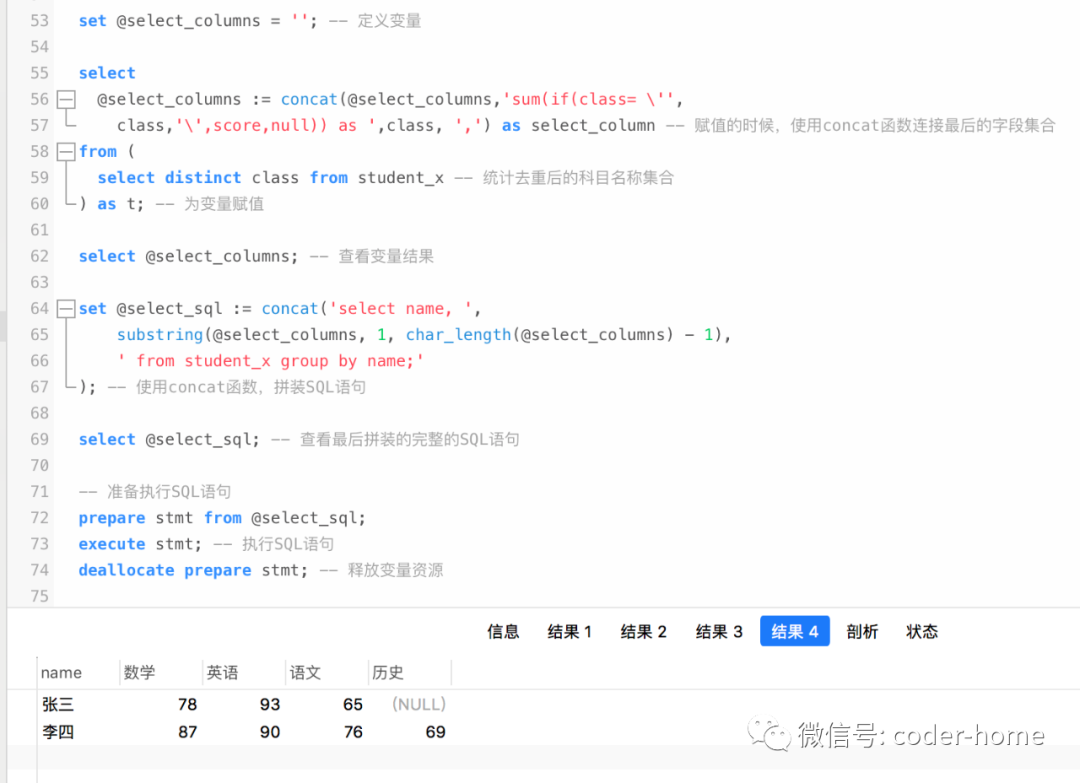
总结:上面这种动态拼装SQL语句的方式避免了因为科目的变化而导致的SQL语句需要重写的问题,可以动态的去生成需要查询的科目名称和数目。但是这样的写法稍微有点复杂,不像前面我们使用聚合函数max或者group_concat那么简单明了。
列转行的示例
示例一:使用union all功能
在进行列转行的实验之前,我们需要先准备好我们的实验环境,准备好表和表中的初始化数据。表结构和初始化数据如下:
准备初始化表结构
CREATE TABLE `student_y` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`math_score` bigint(255) DEFAULT NULL,
`engilsh_score` bigint(255) DEFAULT NULL,
`chinese_score` bigint(255) DEFAULT NULL,
`history_score` bigint(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;准备初始化表中的数据
INSERT INTO `student_y`(`id`, `name`, `math_score`, `engilsh_score`, `chinese_score`, `history_score`) VALUES (1, '张三', 78, 93, 65, NULL);
INSERT INTO `student_y`(`id`, `name`, `math_score`, `engilsh_score`, `chinese_score`, `history_score`) VALUES (2, '李四', 87, 90, 76, 69);进行列转行的实验环境最后如下所示:
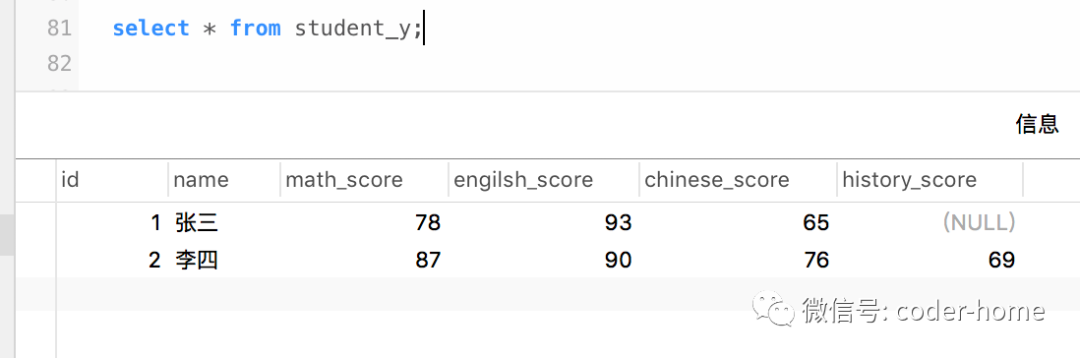
实验环境准备后之后,接下来我们开始使用union all的功能来实现列转行的功能。
我们要达到的列转行的转换效果如下:
我们可以对所有学生的每一个科目的成绩进行单独查询,结果如下:
select name, math_score as score from student_y;
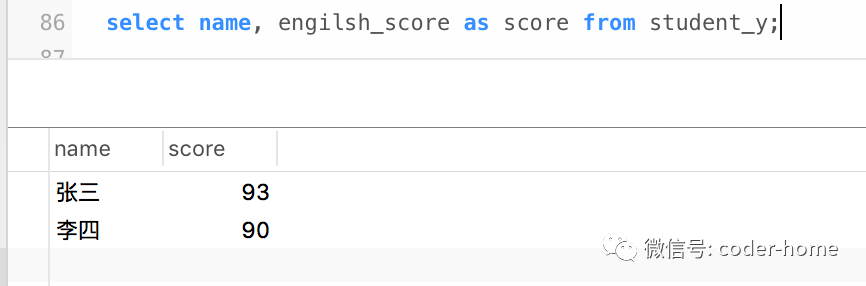
select name, engilsh_score as score from student_y;
select name, chinese_score as score from student_y;
select name, history_score as score from student_y;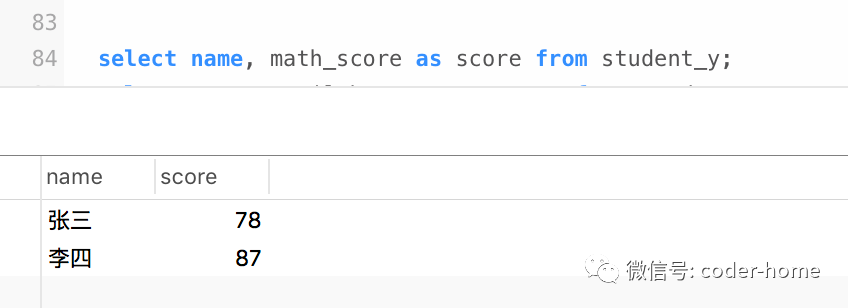
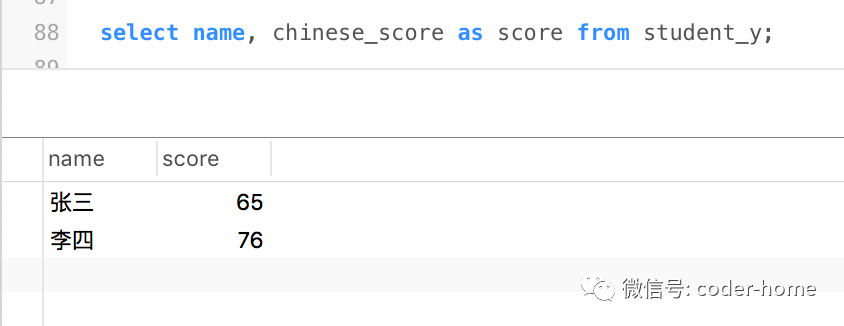
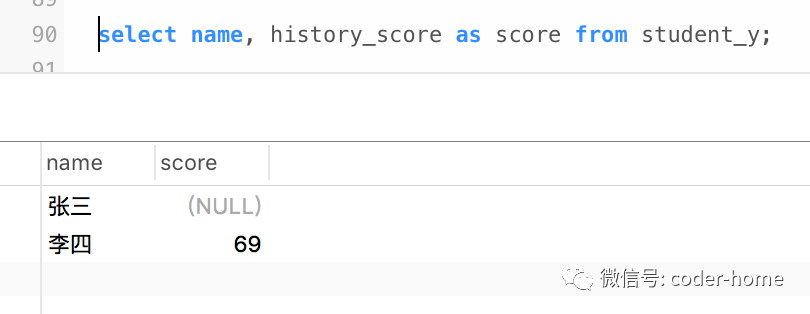
基于上面的每一个查询结果,把最后的结果使用
union all
关键词合并在一起,效果如下:select name, math_score as score from student_y
union all
select name, engilsh_score as score from student_y
union all
select name, chinese_score as score from student_y
union all
select name, history_score as score from student_y;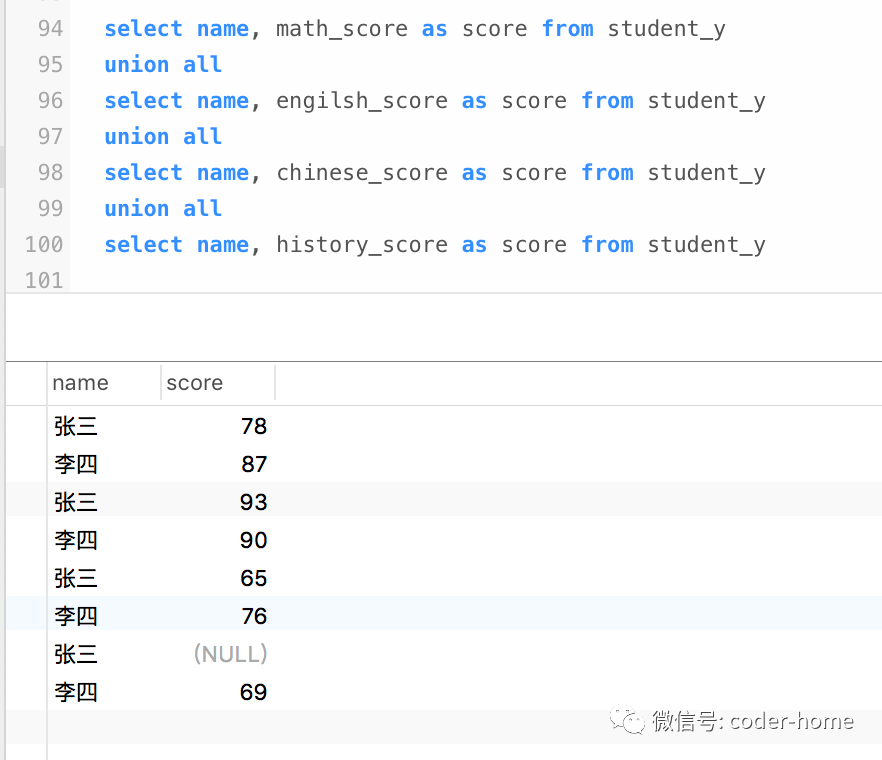
此时,我们发现结果中已经大概实现了列转为行的需求。但是顺序没有达到要求,每个人的各个科目的成绩应该挨着,但是目前是没有挨着的。所以我们需要在基于上面的查询结果,外面在包裹一层查询,增加一个order by语句在外层查询中,即可得到我们想要的顺序。如下所示:
select * from (
select name, math_score as score from student_y
union all
select name, engilsh_score as score from student_y
union all
select name, chinese_score as score from student_y
union all
select name, history_score as score from student_y
) as x order by name;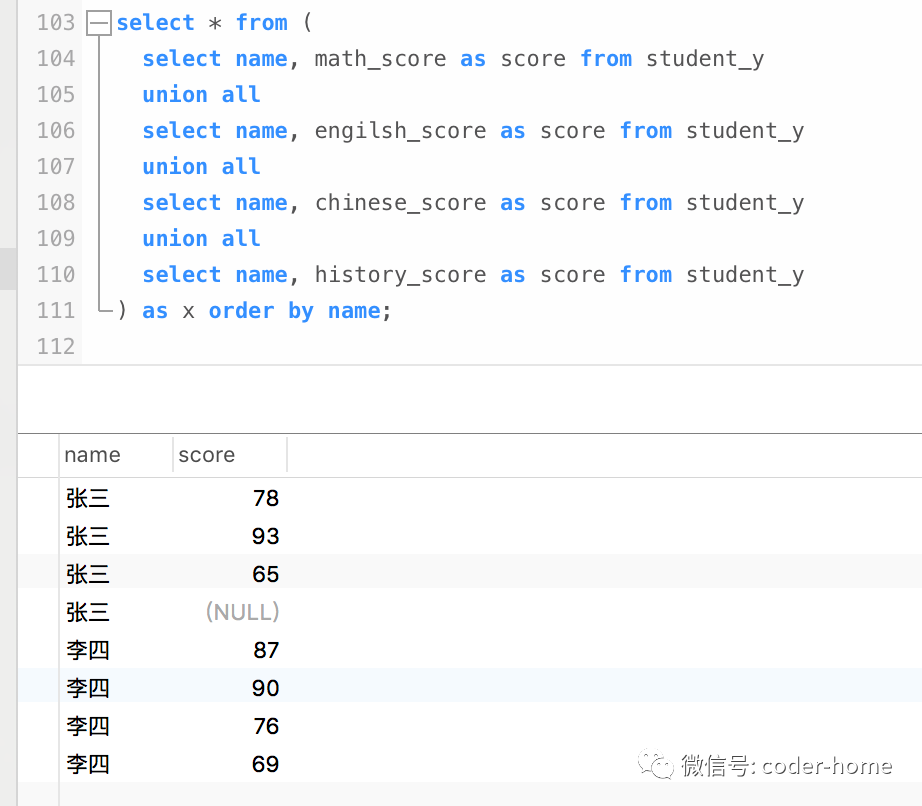
此时的结果已经很接近我们的最后想要的结果了,但是我们发现,每个学生的成绩我们不能区分各个科目的成绩是多少,所以我们需要把科目也纳入到结果集中,也就是我们在查询的时候,要把各个成绩对应的列名称也包含到查询的字段中。于是就有了如下的SQL
select * from (
select name, 'math_score' as class, math_score as score from student_y
union all
select name, 'engilsh_score' as class, engilsh_score as score from student_y
union all
select name, 'chinese_score' as class, chinese_score as score from student_y
union all
select name, 'history_score' as class, history_score as score from student_y
) as x order by name,class;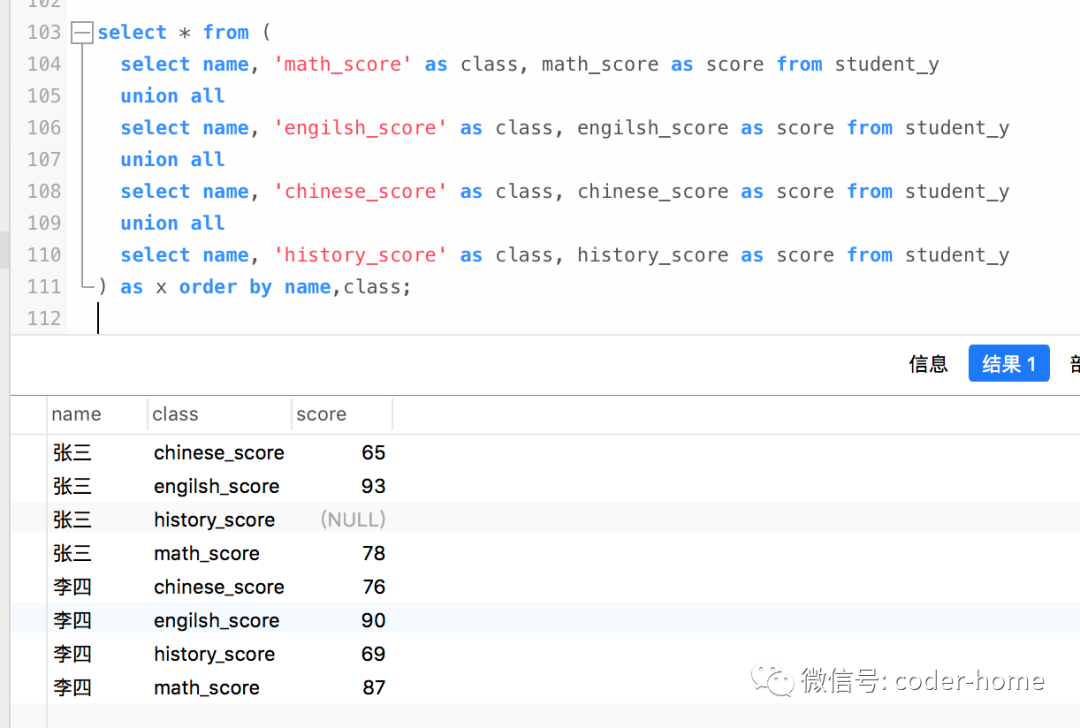
总结:这里我们采用了union all的功能,把所有学生每个科目的成绩单独查询出来,然后把结果集继续合并。最后达到我们想要的列转为行的效果。但是我们发现此时的SQL语句中,和前面我们在进行行转列的时候,使用聚合函数的方式来实现行转列的方式类似,使用了hard code的硬编码,如果科目名称或数目发生改变,我们的SQL语句也需要跟着动态的去修改,这是这种方式的缺陷。但是优点就是比较容易理解。
示例二:使用substring_index函数
有的时候,我们的列转行的表,并不是像前面示例一那样,所有的列都是分开的。它有时候会是这样的数据内容,多个字段是通过一个特定的符号链接起来的。
准备实验环境用的表结构:
CREATE TABLE `student_y2` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`scores` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;初始化使用用的数据:
INSERT INTO `student_y2`(`id`, `name`, `scores`) VALUES (1, '张三', '78,93,65');
INSERT INTO `student_y2`(`id`, `name`, `scores`) VALUES (2, '李四', '87,90,76,69');最后环境如下:

环境准备好之后,我们开始基于这样的一个表,来进行列转行的操作。
使用
substring_index(str, delim, count)
函数来拆分字段,这里需要理解一下substring_index()
函数的功能。基于上面解释的该函数的功能,我们可以得到如下的结果:
select
x.name,
x.scores,
char_length(x.scores) as length_scores,
char_length(replace(x.scores, ',', '')) as length_scores_with_out_comma,
char_length(x.scores) - char_length(replace(x.scores, ',', '')) + 1 as colum_num,
substring_index(x.scores, ',', 1) as score1,
substring_index(x.scores, ',', 2) as score12,
substring_index(x.scores, ',', 3) as score123,
substring_index(x.scores, ',', 4) as score1234,
substring_index(substring_index(x.scores, ',', 1), ',', -1) as colum1,
substring_index(substring_index(x.scores, ',', 2), ',', -1) as colum2,
substring_index(substring_index(x.scores, ',', 3), ',', -1) as colum3,
substring_index(substring_index(x.scores, ',', 4), ',', -1) as colum4
from student_y2 as x;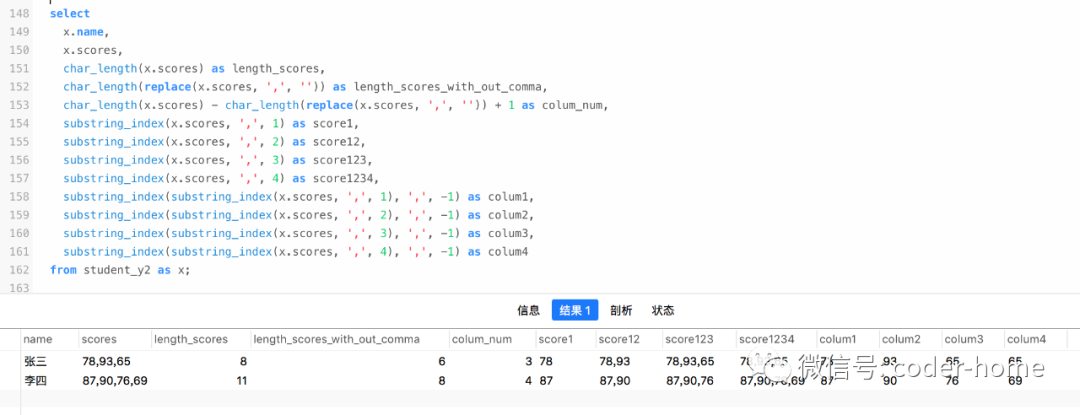
如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容;
相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容;
如果想获取某个字符串中间的某个字符串,那就先得到左边的全部,然后基于截取后的字符串在得到右边的全部就可以得到想要的字符串。
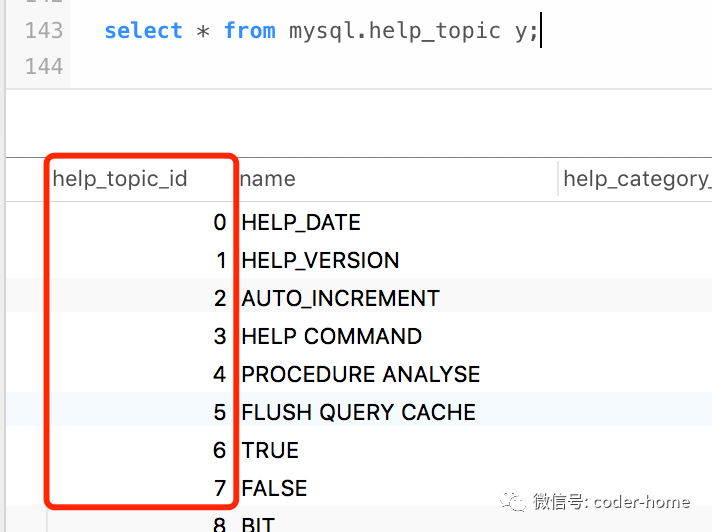
从上面的结果可以看出,我们可以使用substring_index函数来截取原始表中的score的值,根据逗号进行截取。问题的关键是我们需要使用一个序列来动态的判断该解决到哪个位置。而MySQL中刚好有一个系统表
mysql.help_topic
,这个表可以提供我们需要的序列0,1,2,3,4,5,6...n
。基于这个表,我们可以构建出如下的SQL和结果:select * from mysql.help_topic y;
select
x.name,
substring_index(substring_index(x.scores, ',', y.help_topic_id + 1), ',', -1) as 'score'
from student_y2 as x
join mysql.help_topic y
on y.help_topic_id < (length(x.scores) - length(replace(x.scores, ',', '')) + 1);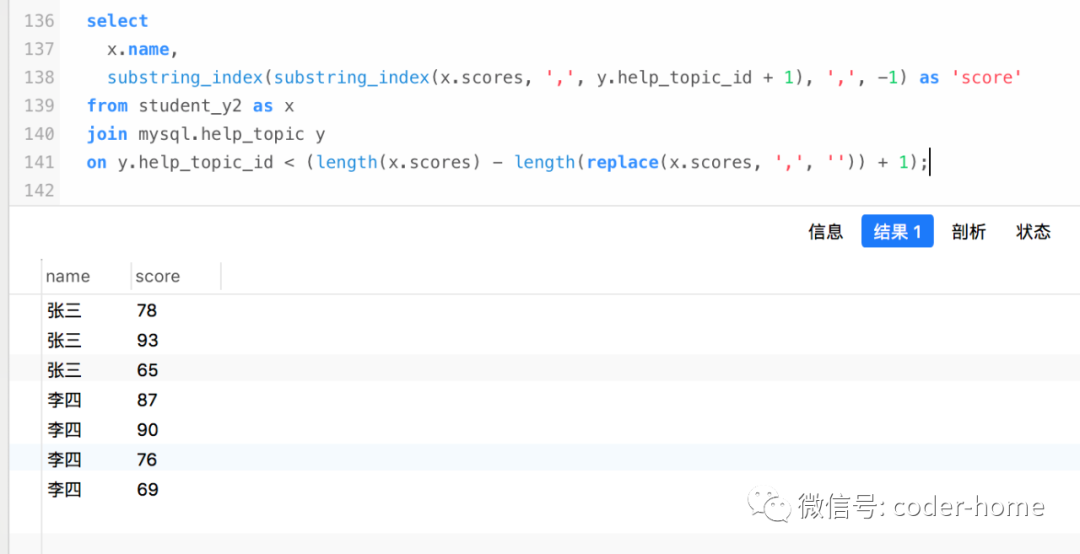
此时我们使用了
mysql.help_topic
表的主键值help_topic_id
的值,关联的时候使用了小于的关系,这就会每次都循环查并判断表中的数据,知道不满足关联的条件,这个技巧很巧妙。如果我们不使用mysql.help_topic
,我们自己创建一个一行一列的表,表中的数据是从0,1,2,3,4,5,6...n
一直自增的数据,也可以达到同样的效果。
总结:我们使用了substring_index
函数结合一个序列表mysql.help_topic
来完成了动态的将列转行的功能。这种方式不会因为列中的数据增加或减少而导致SQL需要重新,它可普适性比较好,可以应对大多数是列转行的需求。但是它缺点是不太容易理解,SQL语句的技巧性比较强。并且对于输入的原始行数据也要特殊的格式要求,要求是使用特定的符号链接的字符串作为一个列的数据出现在原始的输入数据中。
最后总结
我们在文章的开始,首选针对行和列相互转行的概念做了简单澄清,因为有很多人会把行转列和列转行给混淆。行转列和列转行的最明显的区分如下:
行转列,最后的结果中行变少了,列变多了。
列转行,最后的结果中列变少了,行变多了。
紧接着,我们分别针对行转列和列转行进行了实验演示。
在行转列的实验中,我们采用了三种方式来做演示。
使用聚合函数max来实现行转列的需求。
优点:便于理解,也是大家经常或首先想到的方式。
缺点:如果key值变动相应的SQL语句需要作出对应的调整。
使用group_concat来实现行转列的需求。
优点:key值的变动不会导致SQL的重写。
缺点:行转列之后的结果,列不是分开显示的,是以某种符号间隔连接在一起组从字符串展示的。
使用动态拼装SQL语句块的方式来实现行转列的需求。
优点:key值的变动不会导致SQL的重写,同时列的展示方式和使用max聚合函数的展示结果一致。
缺点:SQL语句分多步,过程有点复杂,不太容易理解。
在列转行的实验中,我们采用了两种方式来做演示。
使用union all功能来实现列转行的需求。
优点:便于理解,这样的方式使我们首先能想到的实现方式。
缺点:key值的变动将导致SQL需要重写。
使用substring_index函数结合连续自增序列来完成列转行的需求。
优点:key值的变动不会导致SQL的重写。
缺点:不太容易理解,里面有很巧妙的SQL技巧。对于输入列有特殊的要求,需要使用指定的字符连接在一起组成字符串作为输入的多列。
行转列的变种分类:
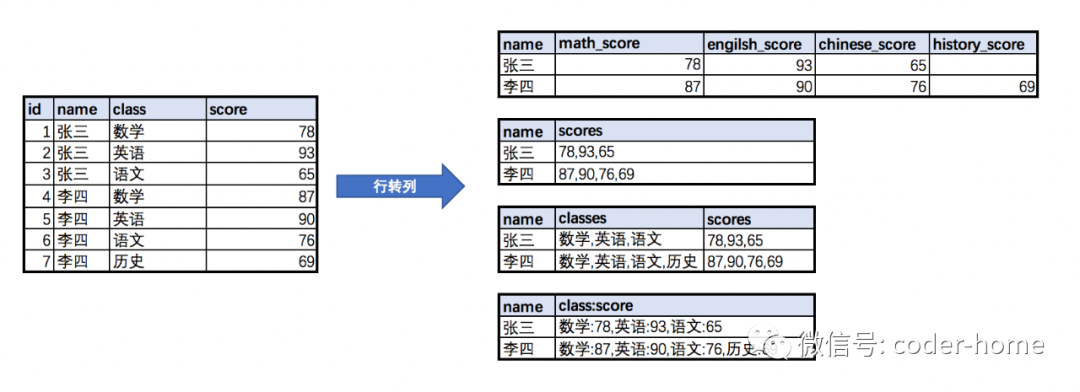
列转行的变种分类:

微信搜索“coder-home”或扫一扫下面的二维码,关注公众号,
第一时间了解更多干货分享,还有各类视频教程资源。扫描它,带走我
