




关于索引在 MySQL 的使用过程中有多重要应该不需要过多介绍,且看官网中的一句话。"改善 SELECT 性能的最佳方法是为查询语句中用到的列创建一个或多个索引。"
MySQL 官网中关于优于与索引篇的介绍写到:
The best way to improve the performance of
SELECT
operations is to create indexes on one or more of the columns that are tested in the query. The index entries act like pointers to the table rows, allowing the query to quickly determine which rows match a condition in theWHERE
clause, and retrieve the other column values for those rows. All MySQL data types can be indexed.Although it can be tempting to create an indexes for every possible column used in a query, unnecessary indexes waste space and waste time for MySQL to determine which indexes to use. Indexes also add to the cost of inserts, updates, and deletes because each index must be updated. You must find the right balance to achieve fast queries using the optimal set of indexes.
索引分类
从数据结构角度划分:
B-tree 索引:基于 B+tree 实现
Hash 索引:基于 hash 算法实现
Full-text 索引:基于倒排索引实现
从存储角度划分:
聚集(也叫聚簇)索引:索引对应的数据行的逻辑顺序与物理存储顺序一致
非聚集索引:逻辑顺序与物理存储顺序不一定一致
从功能角度划分:
普通索引:最基础、最普通的索引
唯一索引:索引列的所有值都只能出现一次,即必须唯一
主键索引:特殊的唯一索引,不能有空值
联合索引:索引建立在多个列上
InnoDB vs. MyISAM
MySQL 不同的存储引擎之间对索引的实现也不尽相同。以 InnoDB 与 MyISAM 为例,看一下它们之间的异同。
首先 InnoDB 与 MyISAM 的索引都是基于 B-tree 这种数据结构实现的,具体来说是 B+tree。B-tree 与 B+tree 的差别是 B-tree 是所有节点都会保存数据信息,而是 B+tree 的非叶子节点不保存数据信息,只有索引本身的信息,并且叶子节点之间有双向指针 。
基于 InnoDB 引擎的数据表,其数据与索引是存储在一起的,而基于 MyISAM 的是分开存储的。当然这也就导致它们的叶子节点在指向数据时的不同。
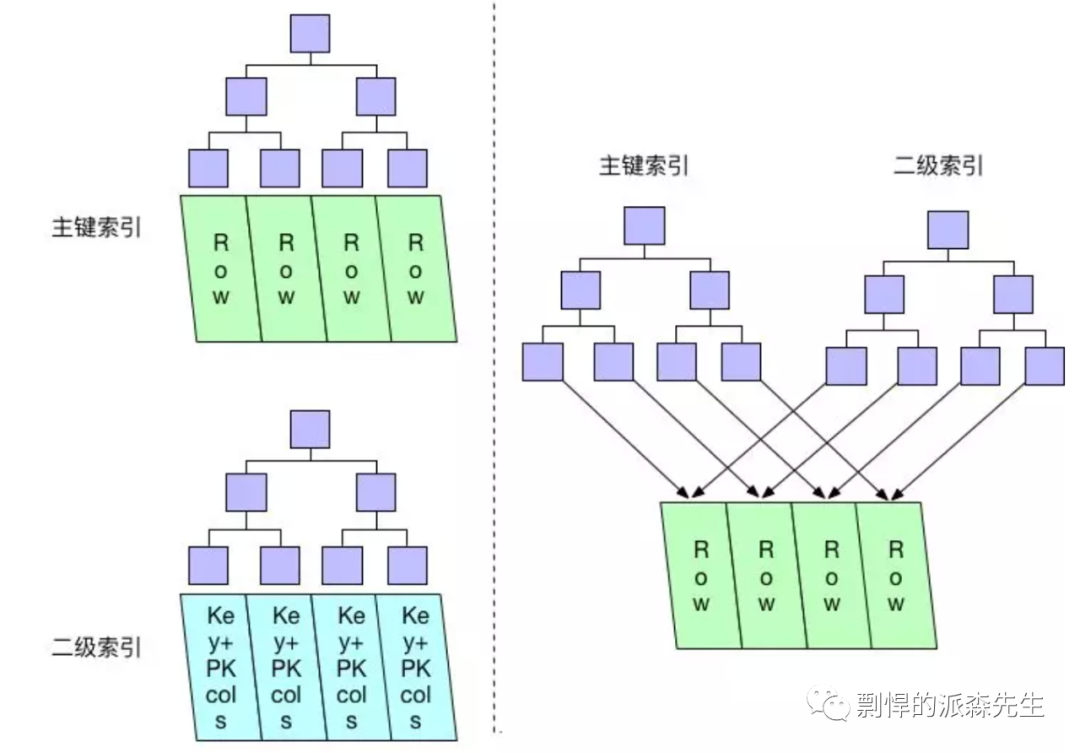
从上图可以看出,MyISAM(右侧) 的主键索引(非聚集索引)与二级索引的叶节点都存储着指针,指向对应的数据行。InnoDB(左侧)的主键索引(聚集索引)的每个叶节点都包含了主键值和所有的剩余列;二级索引的叶节点中存储的不是"行指针"而是主键值,并以此作为指向行的"指针"。
B-tree vs. B+tree
MySQL 为什么选择 B+tree 这种数据结构作为索引呢?
先假设用 B-tree 存储,那么应该长这样:
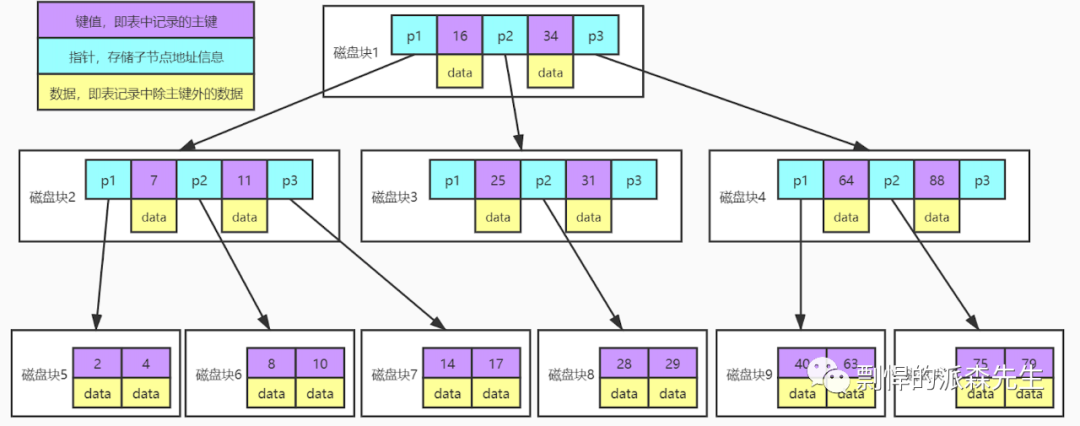
这样会有什么的副作用呢?MySQL 在内存中存储数据的最小单位是页(也就是上图中的磁盘块),而页的默认大小是 16KB。如果一条数据的大小是 1KB,那么一个索引页最大也不会超过 16(假设忽略指针的大小) 条数据。如果一张表有 100W 的数据量,那么定位一条数据需要遍历页的次数就是 5 次。(16**n >= 100W 或 4n >= log100W)经过这 5 次页读取,也就意味着经过了 5 次 IO 操作,速度相对较慢。
假设用 B+tree 存储,那么应该是这样的:
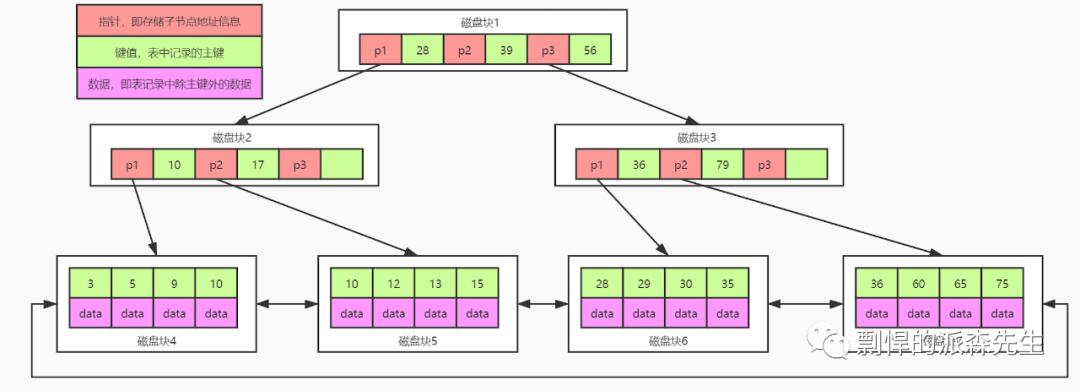
再次分析在 100W 数据中定位一条数据的过程。假设表的主键字段为 unsigned int 类型,大小为 4 个字节,指针大小为 6 字节,此时是要考虑指针大小的。现在一个索引能存储的数据量大小为 16K/10,为 1600 条。那么只需要经过两次索引页,一次数据页就可以读取数据。
比较两者,可以看出,使用 B+tree 时经过的 IO 次数明显要少。更何况这仅仅是 100W 的数据量,如果是 1000W 的数据量呢,效果只会更明显。当然技术是没有优劣之分,只有合适的才是最好的。B+tree 只是在这种场景下效果很好,而 B-tree 也有自己的应用场景,比如 MongoDB WiredTiger 引擎就用到了 B-tree 。
索引匹配
索引这么好用,但是使用可没有那么简单。
首先不要给所有列加索引,因为索引会占用额外空间,并且在修改数据时也要修改索引,还会引发写性能的下降。那么应该给哪些列添加索引呢?
符合业务需求,业务必须要用的时候才加索引;
一定要有主键,并且使用尽量小的数据类型,如 40亿 以内的数据量使用 int unsigned 类型;
建立恰当的联合索引,但是要避免索引重复;
使用区分度大的列建立索引,或者作为索引的最左项;
对于 varchar/char 类型的列,可以使用列的部分内容建立索引,从而减少索引大小。
索引有了,索引匹配是怎样的呢?
最左匹配原则,主要针对 varchar/char 类型以及联合索引;
查询条件中索引列不要使用函数,不要有隐式类型转换,不解释了;
where 语句、join 语句、order by 语句、group by 语句甚至要查询的列尽量都用到索引;
尽量使用主键索引。
覆盖索引
解释一下为什么查询语句中尽量让 select 出来的字段命中索引。
索引是一种高效的查找数据方式,它的高效不仅体现在可以快速定位对应的数据行,而且它也是一种数据的直接获取方式。MySQL 可以使用索引来直接获取列的数据,这样就不需要回表读取数据行。如果一个索引包含所有需要查询的字段的值,我们就称之为覆盖索引。
覆盖索引是非常有用的工具,能够极大地提高性能。SQL 查询只需要扫描索引而无需回表,会带来很多好处:
索引条目数量和大小通常远小于数据行的条目和大小,所以如果只需要读取索引,那么 MySQL 就会极大地减少数据访问量;
因为索引是按照列顺序存储的,所以对于 I/O 密集型的范围查找会比随机从磁盘读取每一行数据的 I/O 要少的多;
InnoDB 的二级索引在叶子节点中保存了行的主键,如果二级索引能够覆盖查询所需要的数据,则可以避免对主键索引的第二次查询,也就是避免了回表。
总结
当我们理解了索引是什么,也学会了如何使用索引时,这下我们的 SQL 一定可以跑得飞起。什么?你居然还写出了慢 SQL!好吧,下篇我们再来说如何优化 SQL 吧。
