




前言
大家好,今天我们来学习一下Debezium关于Oracle连接器的原理。了解一下原理方便我们实现全量同步,增量追平
快照
首先我们需要知道一个叫快照的理论。我们把kafka停止一下,白名单修改成一个新的表hr.DEPARTMENTS,然后再次启动。
[root@localhost config]# more dbz-test-connector.properties name=testoracledbconnector.class=io.debezium.connector.oracle.OracleConnectordb_type=oracletasks.max=1database.server.name=oracle12cdatabase.tablename.case.insensitive=truedatabase.oracle.version=12+database.hostname=192.168.56.130database.port=1521database.user=c##dbzuserdatabase.password=dbzdatabase.dbname=ORCLCDBdatabase.pdb.name=ORCLPDB1database.history.kafka.bootstrap.servers=localhost:9092database.history.kafka.topic=debezium.oracledatabase.history.skip.unparseable.ddl=truelog.mining.batch.size.max=100000include.schema.changes=truetable.whitelist=hr.DEPARTMENTSerrors.log.enable=true
观察日志的输出。
[2021-06-23 14:30:20,210] INFO Context created (io.debezium.pipeline.ChangeEventSourceCoordinator:102)[2021-06-23 14:30:20,267] INFO Snapshot step 1 - Preparing (io.debezium.relational.RelationalSnapshotChangeEventSource:94)[2021-06-23 14:30:20,267] INFO Snapshot step 2 - Determining captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:103)[2021-06-23 14:30:20,520] INFO Snapshot step 3 - Locking captured tables [ORCLPDB1.HR.DEPARTMENTS] (io.debezium.relational.RelationalSnapshotChangeEventSource:110)[2021-06-23 14:30:20,531] INFO Snapshot step 4 - Determining snapshot offset (io.debezium.relational.RelationalSnapshotChangeEventSource:116)[2021-06-23 14:30:20,632] INFO Snapshot step 5 - Reading structure of captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:119)[2021-06-23 14:30:21,124] INFO Snapshot step 6 - Persisting schema history (io.debezium.relational.RelationalSnapshotChangeEventSource:123)[2021-06-23 14:30:23,720] INFO Snapshot step 7 - Snapshotting data (io.debezium.relational.RelationalSnapshotChangeEventSource:135)[2021-06-23 14:30:23,720] INFO Snapshotting contents of 1 tables while still in transaction (io.debezium.relational.RelationalSnapshotChangeEventSource:295)[2021-06-23 14:30:23,720] INFO Exporting data from table 'ORCLPDB1.HR.DEPARTMENTS' (1 of 1 tables) (io.debezium.relational.RelationalSnapshotChangeEventSource:329)[2021-06-23 14:30:23,721] INFO For table 'ORCLPDB1.HR.DEPARTMENTS' using select statement: 'SELECT * FROM "HR"."DEPARTMENTS" AS OF SCN 7492772' (io.debezium.relational.RelationalSnapshotChangeEventSource:337)[2021-06-23 14:30:23,744] INFO Finished exporting 27 records for table 'ORCLPDB1.HR.DEPARTMENTS'; total duration '00:00:00.024' (io.debezium.relational.RelationalSnapshotChangeEventSource:382)[2021-06-23 14:30:23,759] INFO Snapshot - Final stage (io.debezium.pipeline.source.AbstractSnapshotChangeEventSource:81)[2021-06-23 14:30:23,764] INFO Snapshot ended with SnapshotResult [status=COMPLETED, offset=OracleOffsetContext [scn=7492772]] (io.debezium.pipeline.ChangeEventSourceCoordinator:114)
日志打印了生成快照的步骤,总共7个步骤。
1.确定要捕获的表 2.对要捕获的表设置 ROW SHARE MODE
的锁定,以确保任何表都不会发生结构更改。3.读取Oracle数据库重做日志中的SCN位置 4.捕获所有相关表的结构 5.释放步骤3在获取的锁定 6.扫描所有相关数据库表和schema,并测试在步骤3( SELECT * FROM … AS OF SCN 123) 读取的 SCN 位置是否有效,并为每一行生成一个事件并将该事件写入到对应表的 Kafka主题中。 7.最后在连接器中记录快照的成功完成。
这里我们能看到,它实际上还做了一件事。
Finished exporting 27 records for table 'ORCLPDB1.HR.DEPARTMENTS'
也就是它把全部的数据都导出来了,这样可以方便我们进行初始化。
我们可以用kakkacat这个工具来查看。
[root@localhost kafkacat-1.6.0]# kafkacat -b localhost:9092 -t oracle12c.HR.DEPARTMENTS | grep -i offset% Auto-selecting Consumer mode (use -P or -C to override)% Reached end of topic oracle12c.HR.DEPARTMENTS [0] at offset 27
这里的offset正好是27条记录,对应整个表的数据量。如果表的数据量很大的话,我想这个方式应该不合适。
我们的连接器执行完快照之后,就会在从SCN号之后执行流式传输,可以确保连接器不会错过数据库的任何更新。类似于ogg中的抽取进程。如果连接器因任何原因再次停止,则在重新启动时,连接器会继续从停止的位置流式传输更改。
最后我们来说说snapshot.mode连接器属性的设置。
initial : 连接器执行数据库快照,之后它将转换为流式更改。(这是默认值)。 schema_only: 连接器捕获所有相关表的结构,不创建快照,执行上述所有步骤。并在之后创建流式更改。
我们来测试一下snapshot.mode=schema_only的效果,修改配置文件。我们把之前kafka的topic都删除,重新运行。这里修改database.server.name是希望它重新建一个topic,方便观察。
database.server.name=ora12ctable.whitelist=hr.s2snapshot.mode=schema_only
可以看到这次日志到了snapshot的第7步,直接Skipping snapshotting of data
[2021-06-24 22:47:23,125] INFO WorkerSourceTask{id=testoracledb-0} Source task finished initialization and start (org.apache.kafka.connect.runtime.WorkerSourceTask:225)[2021-06-24 22:47:23,132] INFO Metrics registered (io.debezium.pipeline.ChangeEventSourceCoordinator:99)[2021-06-24 22:47:23,132] INFO Context created (io.debezium.pipeline.ChangeEventSourceCoordinator:102)[2021-06-24 22:47:23,186] INFO Snapshot step 1 - Preparing (io.debezium.relational.RelationalSnapshotChangeEventSource:94)[2021-06-24 22:47:23,186] INFO Previous snapshot was cancelled before completion; a new snapshot will be taken. (io.debezium.relational.RelationalSnapshotChangeEventSource:97)[2021-06-24 22:47:23,187] INFO Snapshot step 2 - Determining captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:103)[2021-06-24 22:47:23,456] INFO Snapshot step 3 - Locking captured tables [ORCLPDB1.HR.S2] (io.debezium.relational.RelationalSnapshotChangeEventSource:110)[2021-06-24 22:47:23,463] INFO Snapshot step 4 - Determining snapshot offset (io.debezium.relational.RelationalSnapshotChangeEventSource:116)[2021-06-24 22:47:23,587] INFO Snapshot step 5 - Reading structure of captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:119)[2021-06-24 22:47:24,321] INFO Snapshot step 6 - Persisting schema history (io.debezium.relational.RelationalSnapshotChangeEventSource:123)[2021-06-24 22:47:26,698] INFO Already applied 2 database changes (io.debezium.relational.history.DatabaseHistoryMetrics:137)[2021-06-24 22:47:26,703] INFO Snapshot step 7 - Skipping snapshotting of data (io.debezium.relational.RelationalSnapshotChangeEventSource:139)[2021-06-24 22:47:26,704] INFO Snapshot - Final stage (io.debezium.pipeline.source.AbstractSnapshotChangeEventSource:81)[2021-06-24 22:47:26,718] INFO Snapshot ended with SnapshotResult [status=COMPLETED, offset=OracleOffsetContext [scn=8637351]] (io.debezium.pipeline.ChangeEventSourceCoordinator:114)[2021-06-24 22:47:26,720] INFO Connected metrics set to 'true' (io.debezium.pipeline.metrics.StreamingChangeEventSourceMetrics:70)[2021-06-24 22:47:26,720] INFO Starting streaming (io.debezium.pipeline.ChangeEventSourceCoordinator:157)
查看相关topic信息,注意我们先查看ora12c这个topic。也就是database.server.name。
./kafka-console-consumer.sh --bootstrap-server 192.168.56.170:9092 --topic ora12c --from-beginning --property print.key = true | jq
这个topic存放到是我们的表的ddl语法。
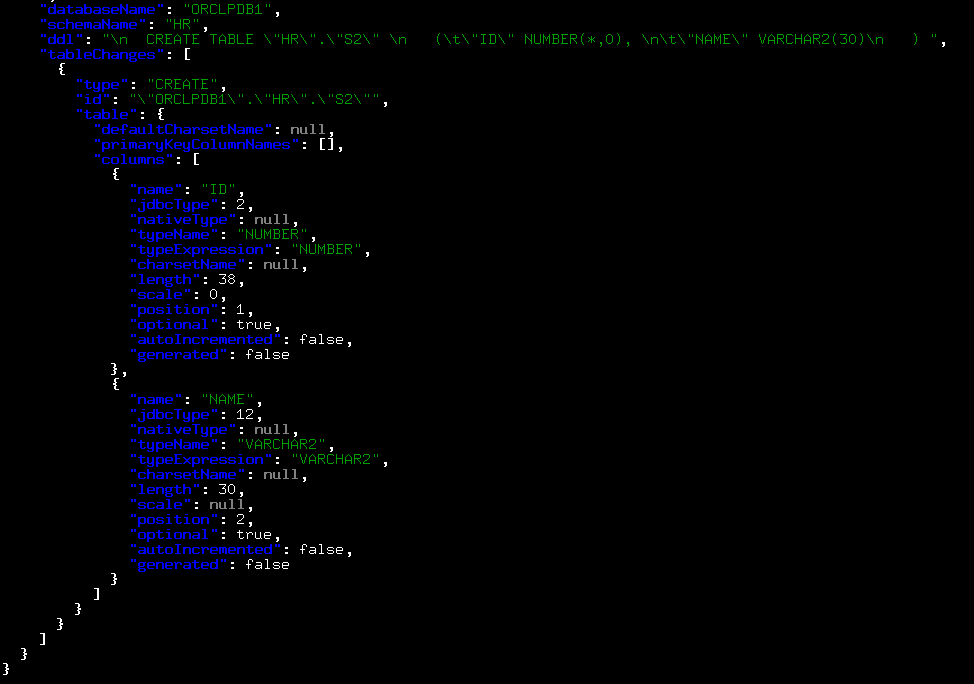
这个表原本包含两条数据。我们来查看一下表的topic信息,也就是ora12c.HR.S2这个topic。可以看到并未创建。
[root@localhost bin]# kafkacat -b 192.168.56.170:9092 -t ora12c.HR.S2% Auto-selecting Consumer mode (use -P or -C to override)% ERROR: Topic ora12c.HR.S2 error: Broker: Unknown topic or partition
我们在Oracle里面插入一条数据。
SQL> insert into s2 values(3,8); 1 row created.SQL> commit;Commit complete.
再次查看就能看到这个topic和插入的数据了。
./kafka-console-consumer.sh --bootstrap-server 192.168.56.170:9092 --topic ora12c.HR.S2 --from-beginning --property print.key = true | jq
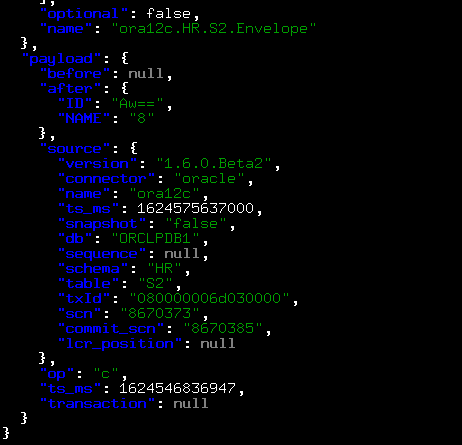
所以,总结一下,如果设置snapshot.mode=schema_only,他只创建的一个database名字的topic,然后捕获白名单表的ddl。如果你之后插入数据,它就会根据你的表名再创建一个topic,并把数据存放在带表名字的topic里面。
我们可以利用这个方法进行数据的初始化:
1.首先按照snapshot.mode=schema_only设置,进行流式复制。(保证从当点进行流式捕捉,不创建快照捕获初始化的数据)。
2.然后查到topic中第一条记录的scn号。
3.根据这条记录的scn-1来进行数据初始化(select * from t as of scn -1),创建视图或者是实体表。然后通过DataX一类的软件导入到PG中。
4.等待初始化完成之后在让pg连接进行消费。
这样我们就能实现全量同步,增量追平。
后记
这几天有点忙,Postgresql的消费端一直没时间测试。未完待续。。。
