




需求分析
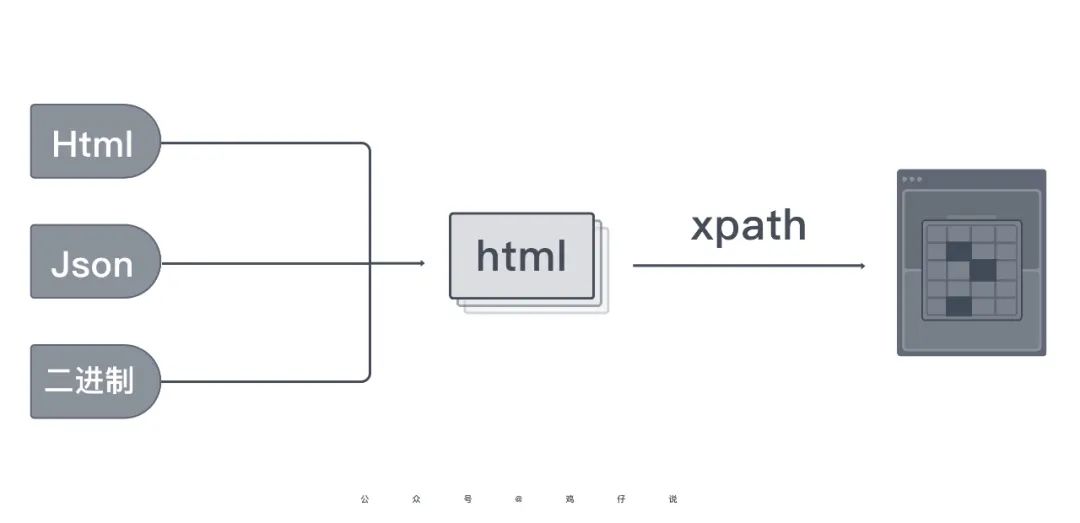
进一步分析
{ "design": "设计图.psd", "software": "sketch.dmg"}
{ "a": "a", "b": [ {"c": "c1", "d": "d1"}, {"c": "c2", "d": "d2"}]}
[ { "a": "a", "c": "c1", "d": "d1" }, { "a": "a", "c": "c2", "d": "d2" }]
import sysprint(sys.getrecursionlimit())>>>1000
再进一步分析
{ "a": "a", "b": [ {"c": "c1", "d": "d1"}, {"c": "c2", "d" : "d2"} ]}
[ { "$name": "a", "$value_type": "raw", "$parse_method": "json", "$parse_rule": "a", "$each": [] }, { "$name": "__datas__", "$value_type": "recursion", "$parse_method": "json", "$parse_rule": "b", "$each": [ { "$name": "c", "$value_type": "raw", "$parse_method": "json", "$parse_rule": "c", "$each": [] }, { "$name": "d", "$value_type": "raw", "$parse_method": "json", "$parse_rule": "d", "$each": [] } ] }]
[ {"a": "a", "c": "c1", "d": "d1"}, {"a": "a", "c": "c2", "d": "d2"}]
代码实现
def _pack_json(result, rules): item = {} for p_rule in rules: if p_rule.get("$value_type") == "raw": if p_rule.get("$parse_method") == "json": item[p_rule.get("$name")] = glom(result, p_rule.get("$parse_rule")) elif p_rule.get("$value_type") == "recursion": if p_rule.get("$parse_method") == "json": tmp_result = glom(result, p_rule.get("$parse_rule")) total_result = [] for per_r in tmp_result: total_result.append(_pack_json(per_r, p_rule.get("$each"))) item[p_rule.get("$name")] = total_result return item
def _unpack_datas(result: dict) -> list: if "__datas__" not in result: return [result] item_results = [] all_item = result.pop("__datas__") for per_item in all_item: if "__datas__" in per_item: tmp_datas = per_item.pop("__datas__") for per_tmp_data in tmp_datas: tmp_item = _unpack_datas(per_tmp_data) for per_tmp_item in tmp_item: item_results.append({**per_tmp_item, **per_item}) else: item_results.append({**result, **per_item}) return item_results
from loguru import loggerfrom glom import glomdef parse(result, rules): def _pack_json(result, rules): item = {} for p_rule in rules: if p_rule.get("$value_type") == "raw": if p_rule.get("$parse_method") == "json": item[p_rule.get("$name")] = glom(result, p_rule.get("$parse_rule")) elif p_rule.get("$value_type") == "recursion": if p_rule.get("$parse_method") == "json": tmp_result = glom(result, p_rule.get("$parse_rule")) total_result = [] for per_r in tmp_result: total_result.append(_pack_json(per_r, p_rule.get("$each"))) item[p_rule.get("$name")] = total_result return item def _unpack_datas(result: dict) -> list: if "__datas__" not in result: return [result] item_results = [] all_item = result.pop("__datas__") for per_item in all_item: if "__datas__" in per_item: tmp_datas = per_item.pop("__datas__") for per_tmp_data in tmp_datas: tmp_item = _unpack_datas(per_tmp_data) for per_tmp_item in tmp_item: item_results.append({**per_tmp_item, **per_item}) else: item_results.append({**result, **per_item}) return item_results pack_result = _pack_json(result, rules) logger.info(pack_result) return _unpack_datas(pack_result)



 好看的人都点了在看
好看的人都点了在看
文章转载自鸡仔说,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
