




今儿来写写Zookeeper这个组件,主要围绕几个方面
(1)集群搭建
(2)集群架构
(3)ZK的数据模型
(4)客户端命令使用
(5)能做什么
首先,了解一个Zookeeper是什么,其是一个开源的分布式协调服务,分布式数据一致性的解决方案。
一、集群搭建
(1)将安装包上传至服务器解压,我的目录是/usr/soft
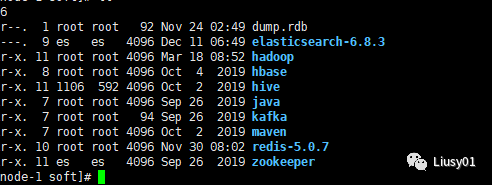
(2)进入/usr/soft/zookeeper/conf目录将zoo_sample.cfg改成zoo.cfg

(3)修改配置文件zoo.cfg
//配置zookeeper数据存放目录dataDir=/usr/soft/zookeeper/zkData//客户端端口clientPort=2181//分别配置集群节点信息server.1=cnode-1:2888:3888server.2=cnode-2:2888:3888server.3=cnode-3:2888:3888
下面这个配置:
1、server.1:配置节点在集群中的唯一id
2、cnode-1:对应节点的ip地址,也可以是主机名
3、2888:集群间通信的端口,也即是follower和leader交换消息所使用的端口
4、3888:进行leader选举的接口
server.1=cnode-1:2888:3888
(3)在zookeeper数据存放目录(也就是zoo.cfg里面的dataDir)新建一个文件myid
我设置的目录是/usr/soft/zookeeper/zkData,
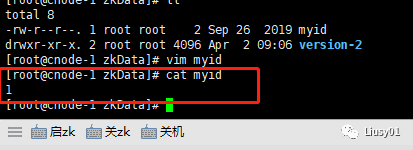
myid文件里面对应的值就是zoo.cfg文件中节点在集群中的唯一id
(4)将上述配置好的zookeeper目录分别用scp发送到其他两台机器上,并修改相应的myid文件
(5)启动集群,分别启动每一个节点

查看节点状态:

cnode-3是leader节点
(6)集群节点数量为什么是奇数?
在ZooKeeper的选举中,如果过半的节点都选一个节点为leader的话,那么这个节点就会是leader节点,也就是因为这个原因,ZooKeeper集群,只要有过半的节点是存活的,那么这个ZooKeeper就可以正常的提供服务。比如有5个ZooKeeper节点,其中有2个节点宕机了,这个时候还有3个节点存活,存活个数超过半数,此时集群还是正常提供服务,所以ZooKeeper集群本生是没有高可用问题的。又因为存活的判断依据是超过半数,所以一般搭建ZooKeeper集群的时候,都使用奇数台,这样会比较节约机器,比如我们安装一个6台的ZooKeeper集群,如果宕机了3台就会导致集群不可用,因为这个时候存活的节点数没有超过半数了,所以6台和5台的效果是一样的,用5台比较合适。
二、集群架构
(1)leader(领导者):为客户端提供读和写的功能,负责投票的发起和决议,集群中只有此角色才能接收写请求。
(2)follower(跟随者):为客户端提供读服务,如果是写请求,则转发至leader节点,在选举过程中进行投票。
(3)observer(观察者):此角色节点只能提供读服务,不参与其他功能,是为了提高集群的读取性能而产生的节点。
配置observer节点只需在其zoo.cfg文件中添加两个配置:
peerType=observerserver.n=host:2888:3888:observer
三、ZK数据模型
ZK的数据模型和文件系统类似,类似于下图。每一个节点称为:znode,是ZK中的最小的数据单元,每一个znode都可以保存数据和挂载子节点,从而构成一个层次化的属性结构。
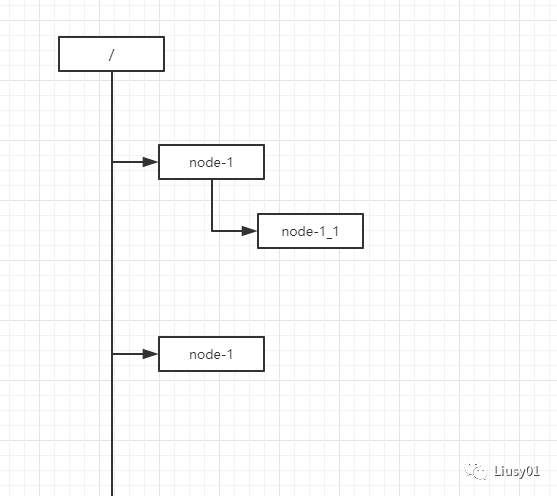
节点特性:
持久化节点 :节点创建后会一直存在zookeeper服务器上,直到主动删除
持久化有序节点 :每个节点都会为它的一级子节点维护一个顺序
临时节点 :临时节点的生命周期和客户端的会话保持一致。当客户端会话失效,该节点自动清理,临时节点下不可创建子节点。
临时有序节点 :在临时节点上多了一个顺序性特性
需要注意的是,临时节点下不可以在创建子节点。
四、客户端命令使用
(1)连接客户端,进入bin目录下执行sh zkCli.sh start命令
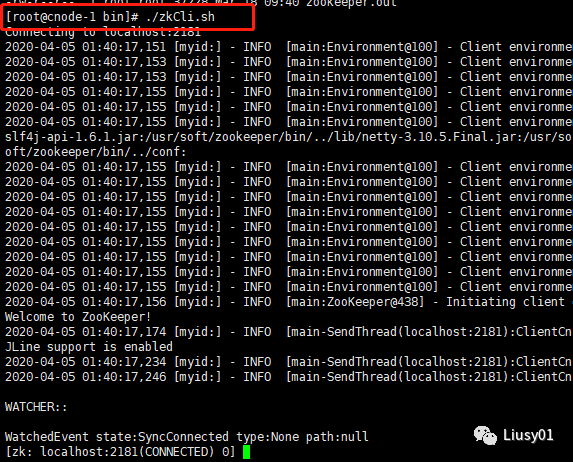
(2)查看客户端支持的所有命令,用help
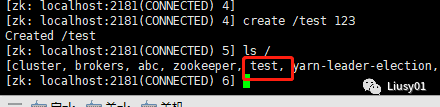
(3)创建节点
create [-s] [-e] path data acl
-s 表示节点是否有序
-e 表示是否为临时节点
默认情况下,是持久化节点
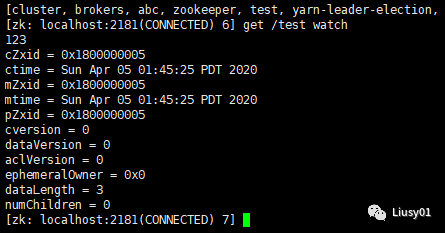
(4)获取节点信息
get path [watch]:watch表示监听此节点变化,当节点信息被修改时,当前客户端可以接收到相应的信息
例如我在cnode-1节点用客户端监听/test节点
在cnode-2节点改变/test的值
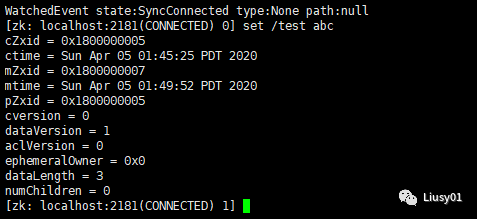
之后在cnode-1节点会受到提醒:

(5)删除节点
delete path 和 rmr path 都可以
(6)stat信息,也就是get path命令执行后获取的
1、节点被创建时的事务idcZxid = 0x18000000052、创建时间ctime = Sun Apr 05 01:45:25 PDT 20203、节点最后一个修改的事务idmZxid = 0x18000000054、最后一次修改时间mtime = Sun Apr 05 01:45:25 PDT 20205、当前节点下的子节点最后一次被修改的事务idpZxid = 0x18000000056、子节点版本号cversion = 07、数据版本号dataVersion = 08、acl版本号,节点权限aclVersion = 09、临时节点所属客户端的sessionidephemeralOwner = 0x010、数据长度dataLength = 311、子节点数量numChildren = 0
五、Zookeeper能做什么
(1)订阅发布
利用的是节点的watch机制
(2)分布式锁
每个客户端都会在某个目录下注册一个临时有序节点,每次最小的节点会获取锁,当前节点会去监听上一个较小节点,如果较小节点失效之后,就会去获取锁。
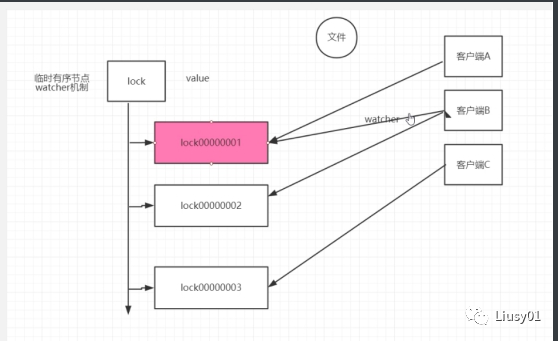
(3)负载均衡
(4)统一命名服务
(5)master选举
每个客户端都去zookeeper下创建相同的节点,哪个客户端创建成功,其就成为master。其他客户端就监听此节点的变化。
kafka,hadoop,hbase都用到ZK去进行master选举。



老罗说交个朋友

