




前言
想必大家都应该看过《为什么不建议在 MySQL 中使用 UTF-8》这一类的文章。
原因就是 MySQL
中的 utf8
最大只支持 3字节 每字符,可能产生的问题就是无法插入特殊字符,比如emoji表情🙂。而这一类的特殊字符都是占 4字节,我们现在也都在正常地使用这类字符,所以都建议使用 utf8mb4
字符集去存储字段。
最近碰到的问题就是:我的字段也设成了 utf8mb4
,还是无法插入🙂…经过一系列的折腾,终于找到了问题的根源:character_set_server
。
解决过程
数据库环境:阿里云MySQL 5.6.16
“排查问题查找根源的过程往往都是通过控制变量,看是在哪个环节出错了。
”
1. 先测试本地 MySQL
复制相同接口,往数据库插入数据的代码就没什么放的了…
插入成功。至少可以排除程序代码问题。
目前本地数据库插入成功,阿里云数据库怎么都插入失败,说明两者数据库肯定还是有差异的。
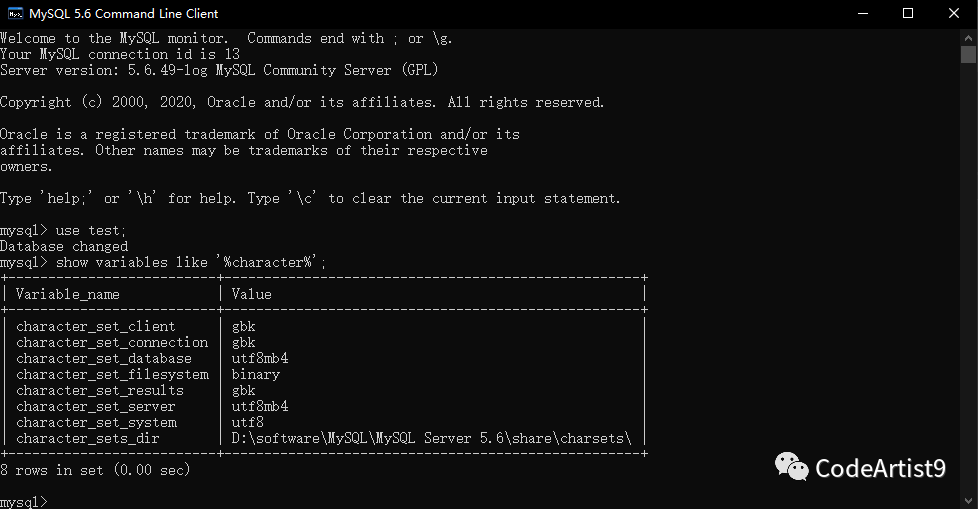
2. 比较两者数据库的字符集使用信息
使用 Navicat
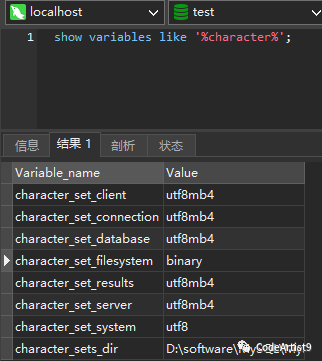
执行命令:查看相应数据库的字符集
show variables like '%character%';
阿里云库:
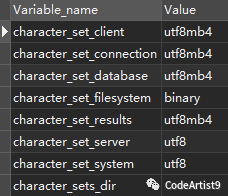
本地库:
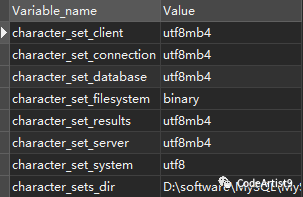
经比较,两者的变量属性 character_set_server
不一样:阿里云是 utf8
,本地是 utf8mb4
。
具体每个都什么意思,在下面的总结中说
3. 修改本地库 character_set_server 属性
先看看把本地数据库的改成 utf8
,再插入emoji表情还会不会有这问题。
执行命令
set character_set_server = "utf8";
执行完毕,再次调用接口,往本地数据库插入emoji表情😷,发现和阿里云库一样报错了。
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\xB7' for column 'msg_content' at row 1
当再尝试将 character_set_server
改回成 utf8mb4
时,还是报错无法插入,尝试重启 MySQL
服务。
重启后,可以正常插入了。
说明问题的根源就是在这:character_set_server
。
4. 更改配置
当前的阿里云库是线上正在使用的,改完后如果还要重启大概率会造成一定的问题,于是只能对服务的配置文件下手。
在数据库 URL 连接串后面加上:?characterEncoding=utf8
spring:
datasource:
url: jdbc:mysql://IP:port/库名?characterEncoding=utf8
再次调用接口,插入带有 emoji 符号的数据,插入成功,问题解决。
具体原因在下面总结中说
知识点总结
字符集和校对规则
字符集(CHARACTER SET) 为字母和符号的集合。例如 latin1
(MySQL默认), utf8
和 utf8mb4
等等…不同字符集的默认校对规则和1个字符最大支持的字节长度可能不一样。
校对规则(COLLATE) 为规定字符如何比较的指令。比如当我们 SQL
语句后面需要根据某个字段 order by
时,就会以这个指定的校对规则为准。
相关命令:查询 MySQL
数据库服务器中的所有可用字符集
SHOW CHARACTER SET;
utf8 和 utf8mb4
我们常说的 utf8
字符集一个字符可以表示1~4字节,然后我们的中文汉字是一个字占3字节。
但是 MySQL
中的 utf8
其实是阉割后的,一个字符只能表示1~3字节,而 utf8mb4
才是我们真正意义上的 utf8
。
Tip: MySQL
中的 utf8
是 utf8mb3
的别名,两者一样。
字符集使用级别优先级
“表字段 > 表 > 数据库(character_set_database) > 服务器(character_set_server)
”
如果指定了字符集 character set
和校对规则collate
,就以指定的为准。如果只指定字符集 character set
,则使用此字符集及其默认的校对规则collate
。如果既不指定字符集 character set
也不指定校对规则collate
,就使用数据库默认的。数据库的字符集不指定,那在创建的时候就使用服务器级别的。
MySQL 各字符集变量含义
character_set_client、character_set_connection以及character_set_results是客户端的设置。
character_set_client
:客户端来源数据使用的字符集(告诉转换器客户端发送的字符集)character_set_connection
:服务器接收到客户端的数据时转换器会将character_set_client
转为character_set_connectioncharacter_set_results
:服务器向客户端返回数据时使用的字符集character_set_system、character_set_server以及character_set_database是服务器端的设置。
character_set_system
:系统字符集,用于系统元数据(表名、字段名和函数名等)。默认就是utf8
,没必要进行更改character_set_server
:服务器级别使用的(默认)内部操作字符集;修改后生效需要重启MySQL
实例该参数修改后,仅对开启高权限账号的实例后来创建的数据库有效,对当前数据库无效。
character_set_database
:当前数据库使用的字符集,没有指定就使用character_set_server
指定的
说实话,信息太多了,看着头疼…下面画张图来表示 MySQL
中字符集间的转换过程
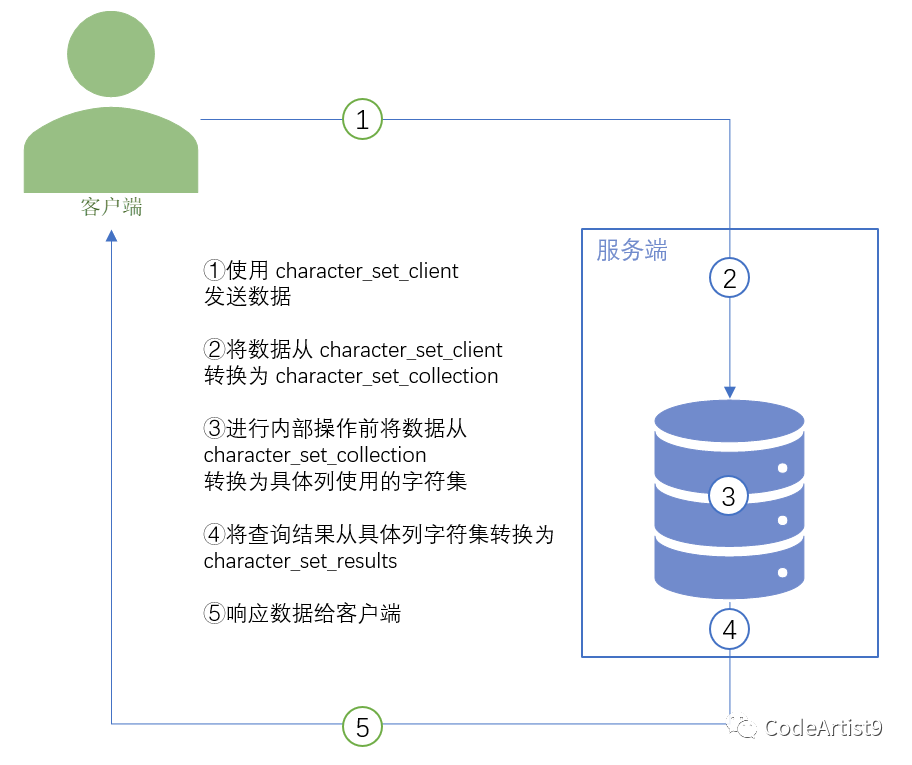
这里的客户端,就是我们的 Navicat
,DOS
命令行界面或者运行的应用程序。其实就是与我们 MySQL
建立连接的一方。
这里会发现,不同的客户端,character_set_client
, character_set_connection
以及 character_set_results
是不一样的。
characterEncoding=utf8
为什么 character_set_server
修改后需要重启才能生效,而在数据库 URL 连接串后面加上 ?characterEncoding=utf8
也行?
Tip: 这里的 utf8
指的是 Java 中的,这才是真正意义的 utf8
characterEncoding=utf8:相当于当前客户端(Java程序)的 character_set_client
, character_set_connection
和 character_set_results
字符集指定成了 MySQL
中的 utf8mb4
。
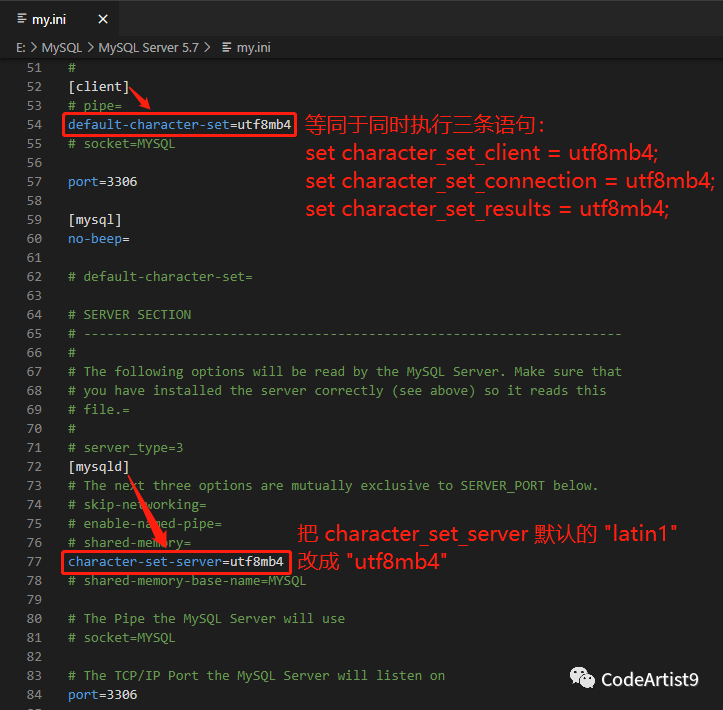
“这里相当于执行了一条命令:
set names utf8mb4;它的作用就是修改客户端的三个字符集设置。等价于同时执行了三条语句。
set character_set_client = utf8mb4;
set character_set_connection = utf8mb4;
set character_set_results = utf8mb4;
”
而这个设置,只针对于客户端与 MySQL
服务器的当前连接会话。 如果不写,默认这三个值以 character_set_server
的值为准。(改了 character_set_server
之后再重启,那就一劳永逸了)
而我们线上的数据库恰恰就是 utf8
,那么这三个字符集就统一成了 utf8
,emoji表情过来的时候,自然就不认识了。这也就是这次字段列设计成了 utf8mb4
却无法插入emoji表情的主要原因。
口说无凭,直接上最权威的官网解释。
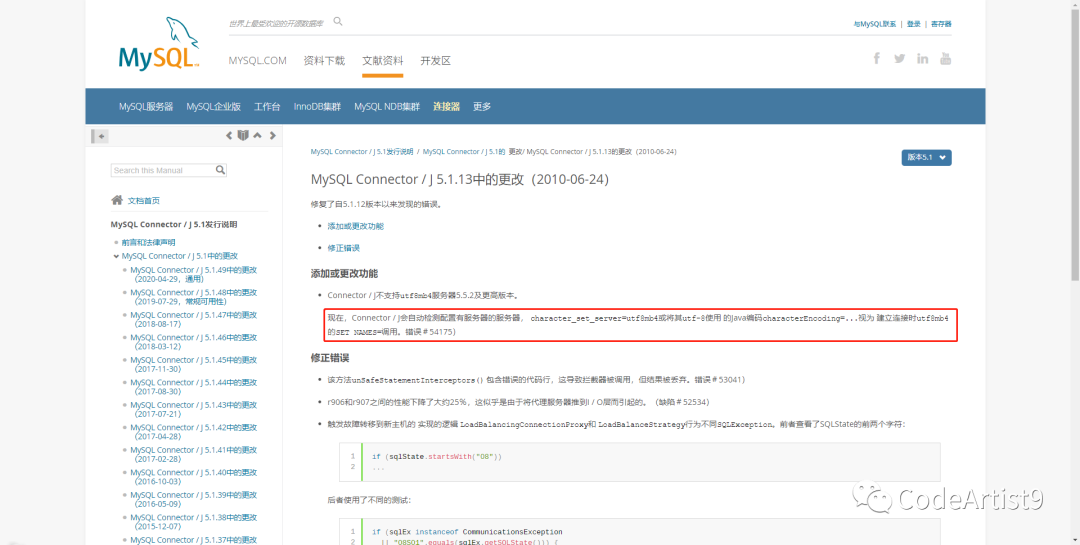
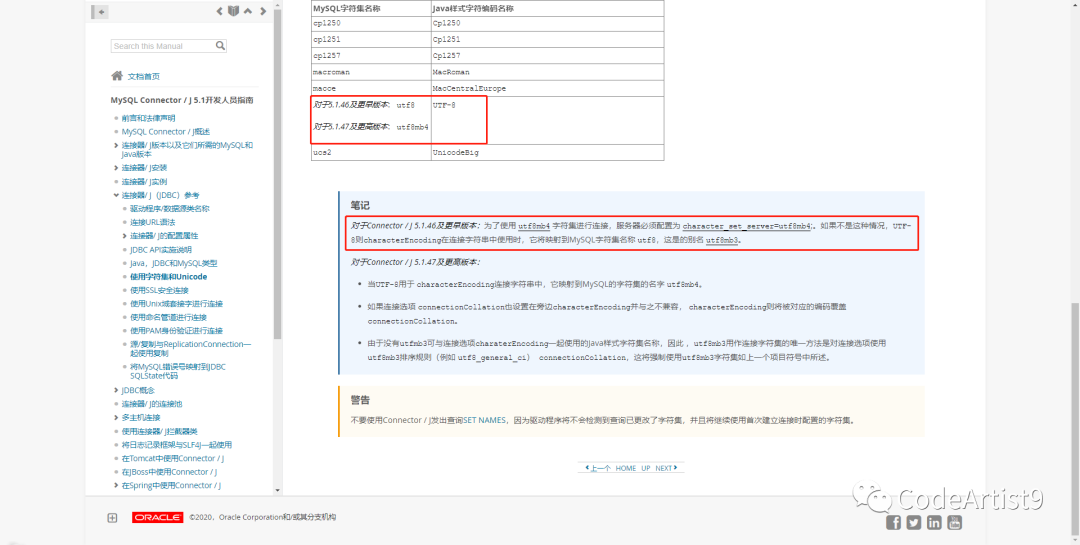
事后复盘
建议数据库实例建立起来的时候,先把该改的基本配置都改了。
避免以后都已经在线上运行了,因为一些问题如果还要重启
MySQL
服务那可太难受了。以
Windows
为例,配置文件默认是安装目录下的my.ini
文件。不同语言对
character-set-server
这项配置的处理方法不一样,至少Java
依赖于它(当你在 URL 后不指定 characterEncoding 时)。
参考资料
阿里云 MySQL字符集相关说明:https://help.aliyun.com/knowledge_detail/41706.htm
Changes in MySQL Connector/J 5.1.13:https://dev.mysql.com/doc/relnotes/connector-j/5.1/en/news-5-1-13.html
Using Character Sets and Unicode:https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-charsets.html
最后
要想数据能正常存储,字符集、编码一向是各大数据仓库的基本设置,希望这篇文章能让大家有所收获。
如果本文对你有帮助的话不妨点个赞👍和在看呦。
分享技术,稳住,我们能赢💪!
往期推荐

带你扒一扒 MySQL 的数据在磁盘上到底长什么样子…

大师,我悟了:为什么 MySQL 索引要用 B+tree ,而且还这么快?
HashMap 的 7 种遍历方式与性能分析!

点个在看你最好看

