





点击上方蓝字,关注我们
需求介绍
数据膨胀,指的是物理数据文件的大小明显高于实际存储的数据量。 甚至某些特殊场景下,一个表中只有一条简单的数据,但是表对应的物理文件可能已经达到M级甚至G级。
为了解决数据膨胀,GaussDB(DWS)通过vacuum和FSM来清理和重用物理空间。 本文简单介绍FSM的设计和原理,并通过一个例子对FSM功能进行简单的测试和验证。
数据膨胀的原因
INSERT很简单,就是将元组插入到页面的空闲空间中; DELETE则是将元组标记为旧版本,但是即使这个旧版本对所有事务都不可见了,这个元组占用的空间也不会归还给文件系统; UPDATE相当于DELETE+INSERT,等于是占用了两条元组的位置,类似DELETE,旧版本的元组依然占用着物理空间。
设计方案
实现过程
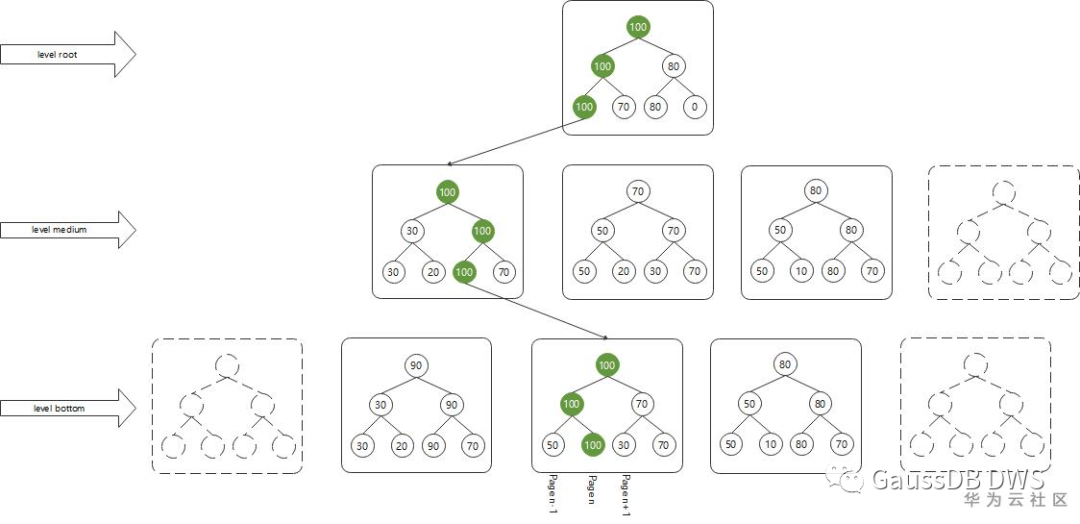
level root和level medium都是用来查找level 2中的FSM页面的 level bottom是用来查找符合要求的heap页面的
FSM信息的可视化读取
FSM查找和维护的逻辑并不复杂,但是整个过程对外是不可见的。因此GaussDB(DWS)提供了pagehack工具来读取FSM文件,帮助查看当前数据页的空闲空间情况。
下面结合pagehack工具解析FSM文件进一步理解FSM机制:
初始化数据
首先新建行存表并插入大量数据。分布列数据固定,为了让数据都落入一个dn,方便后面分析。
删掉 2 条位于第一个heap page的数据。因为是新建的表,所以数据会从前往后顺序的落到数据页面里,c2等于1和2的两条数据一定在第一个页面上。
create table t1(c1 int, c2 int); -- 建行存表insert into t1 values(15, generate_series(1,100000000)); -- 插入数据delete from t1 where c2= 1 and c2=2; --删掉 2 条位于第一个heap page的数据。
生成FSM文件并落盘
vacuum t1; -- 生成FSM文件checkpoint; -- 刷盘
用pagehack解析FSM文件
pagehack -t fsm -f 73916_fsm > 73916_fsm.log
2.打开文件,从第一个fsm block开始看。第一个fsm block属于 level root,看到一共111个fsm block,下层的最大空闲空间是31,且在数组0的位置上。
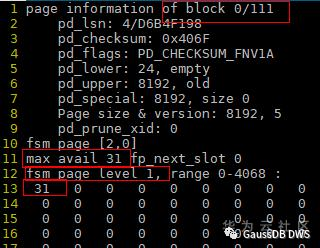
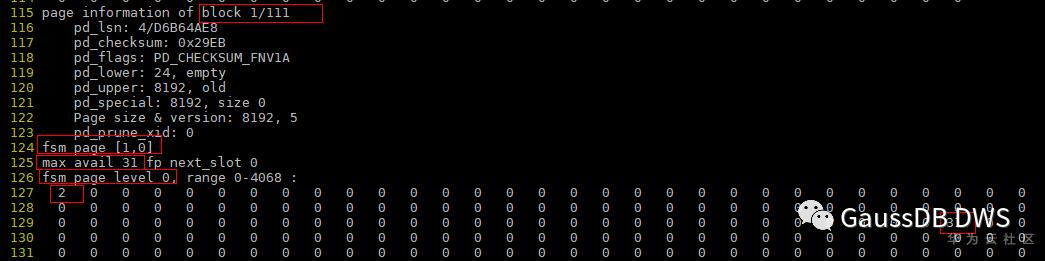
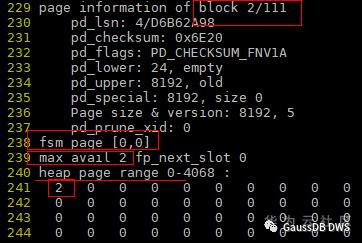
5.第4个及后面的一直到110的block的信息如下,可以看到整个heap page都没有剩余空间了,这是因为这些页面一直在插入,没有删除数据。
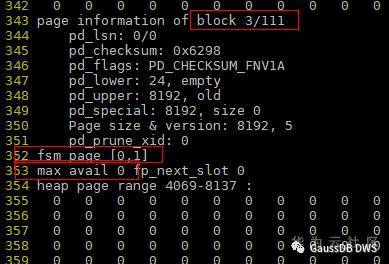
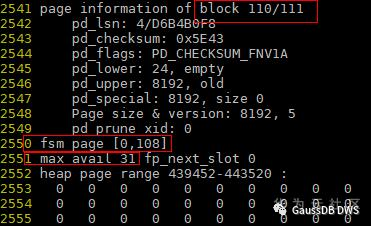
从12553这行开始算,到12628的第26个位置为31,(12628-12553)40+26 = 3026。用page range算:439452+3026 = 442478。按 8k 页面算:4424788192 = 3,624,779,776;


看一下实际文件大小:1073741824*3+403554304 = 3,624,779,776,与刚才算的结果相同。

思考总结
我们一开始向空表顺序插入了大量的数据,页面也是顺序的扩展 在442478页面的时候,最后的数据插入完毕,并且还留有31个空间可用 当我们从第一个页面删除了两条数据后,第一个页面空余出了2个空间 fsm树的样子类似:
fsm block 0 (31,0,0...0) / fsm block 1 (2,0,0...0,31,0...0) / fsm block 2 fsm block 110(2,0,0...0) (0,0...0,31,0...0)
在level bottom这层的fsm block中,按顺序存放的就是heap block的空闲空间值。 1亿条数据用了108个slot,而一个fsm block 有4000+个叶子,所以肯定是用不完的。
对于日常运维的建议是:
打开autovacuum,让GaussDB(DWS)自动的帮你做vacuum,这样新的数据就可以通过FSM机制复用空闲页面,以减少数据膨胀带来的磁盘空间浪费。



