




9月26日,Apache Hadoop Meetup上海站,现场来自于华为、腾讯、阿里、Cloudera、京东、滴滴、小米、美团、字节跳动、清华大学等IT公司和高校分享了他们的议题,吸引了来自线上线下共400多人参与。

在Hadoop Meetup @Shanghai的活动上,我们团队的郑振宇和姜逸坤为大家带来了《赋能Arm大数据开源生态,华为的探索之路》议题。
议题上半部分,华为鲲鹏开源软件生态拓展负责人郑振宇,为大家带来了关于华为在构建多样性算力生态上的一些思路和成果(可以参考公众号上一篇文章《一文看懂大数据领域Arm适配现状》)。

随后,华为鲲鹏开源软件生态使能负责人姜逸坤,以Hadoop在Arm平台的适配为例,为大家介绍了团队在Apache Hadoop社区构建Arm生态的历程和成果。
Hadoop支持Arm架构的关键历程

团队从2019年中旬开始投入到Hadoop的Arm支持工作中。最初也是最重要的工作是让Hadoop在Arm平台上正常跑起来。
随后,利用CI来保证Hadoop在Arm平台的持续可用。当这些工作完成后,团队的工作也得到了社区的认可,最终在2020年7月Hadoop社区官方发布了第一个Arm包。
在完成Arm适配的过程中,涉及了周边大量依赖软件的Arm支持,例如Protocolbuf、gRPC、LevelDB、Netty等不同领域的开源软件,这些软件通常也是其他开源项目的基础,当走Hadoop的Arm之路时,也顺便为其他项目提前探路和铺路。
在分享过程中,还为大家介绍了一个易于理解和有趣实例——一个小数点后第16位的问题:

通过上面的问题,让现场的同学了解了:其实在适配Arm的过程中,会发现其他架构场景下很多隐藏的问题,修复后也能完善开源软件在多架构场景下的健壮性。
Hadoop在Arm平台的性能优化
在完成了Hadoop在Arm平台上的优化后,我们的团队在思考另外一个问题:如何让Hadoop在Arm平台上更好用?
因为在适配阶段发现了很多和底层库相关的问题。所以,为了让Hadoop on Arm更好用,我们把目标瞄准了性能优化,从底层的压缩库做起。确定了这个目标后,我们分析了Hadoop在进行MapReduce任务中的压缩和解压的流程:

主要涉及5次压缩和4次解压,可以看到,压缩和解压在整体的流程中,还是占了很大比例的。而对于压缩库的选择上,华为的团队也是选择了市面上使用最多,最广的几个压缩库:
- Snappy:来自Google的压缩库,计算速度非常快,压缩比略逊一筹。
- Zlib/Gzip:历史悠久,使用广泛,是很多系统默认压缩库,压缩比理想,压缩速度稍慢。
- ZSTD:由Facebook开源的一块压缩库,在保证压缩比的情况下,压缩速率也很棒,具有很好的均衡性。
随后,来自华为计算的产品和开源联合团队开始了压缩库底层优化的硬核之路:

最终,从测试结果看,性能取得了非常明显的提升,并且秉承着“硬件开放,软件开源”的原则,所有优化代码均在贡献到上游社区,全部开源。最终,经过团队的实测,在Hadoop的端到端的性能测试上,也获得了很明显的效果,优化后较优化前整体性能提升10~14%左右:
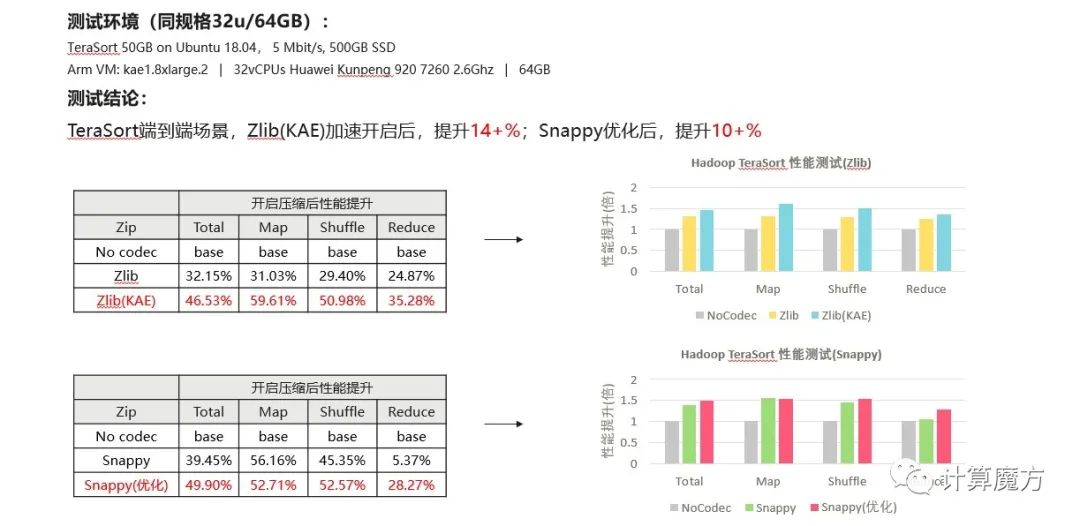
Hadoop多样性算力支持
在完成了压缩库底层的验证后,团队也对多样性算力进行了对比以及混合部署的验证。
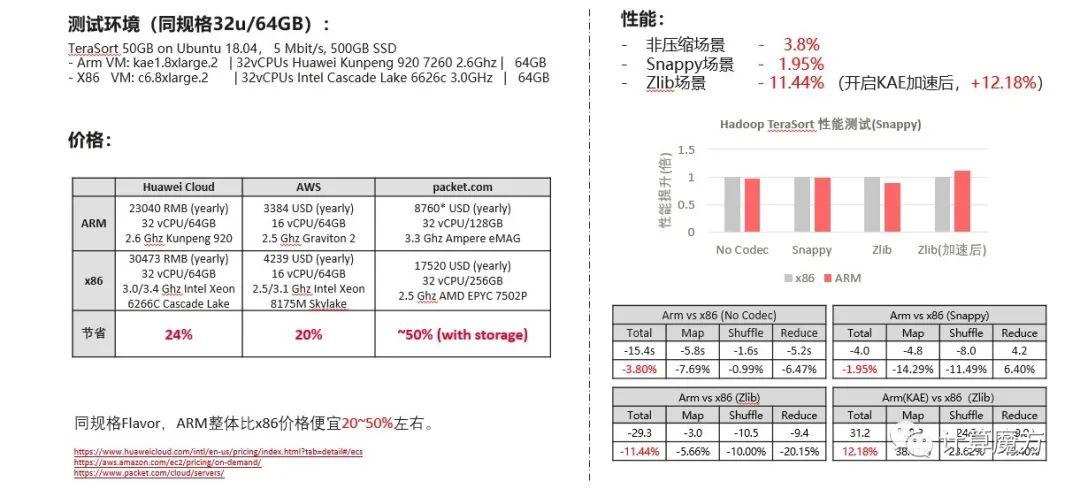
从测试结果可以看出,同规格的机器,性能保持持平,Arm的价格整体比X86便宜20%以上, 具有更好的性价比。
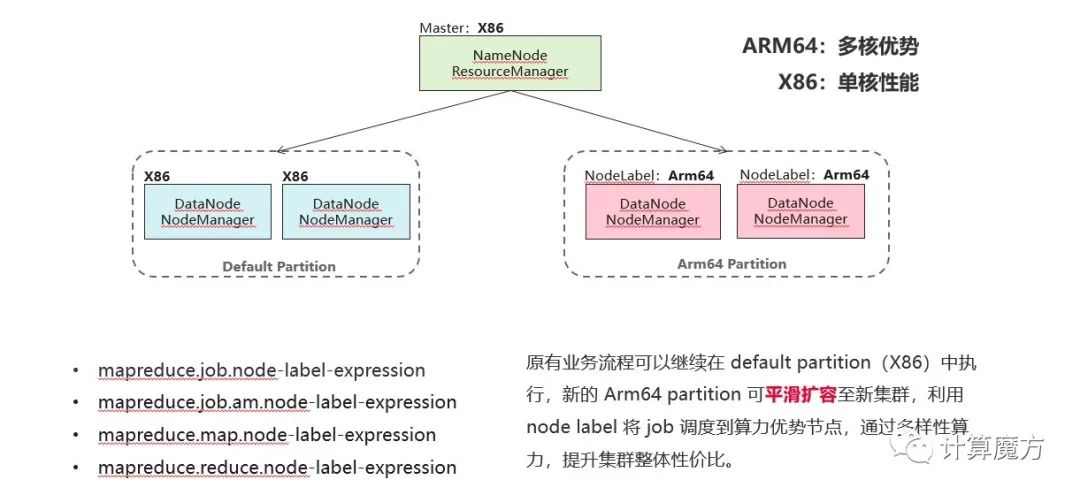
随后,也介绍了Hadoop集群如何在现有集群中进行扩容,可以利用Hadoop社区node label的能力,对新的机器进行标准,按需进行平滑扩容。
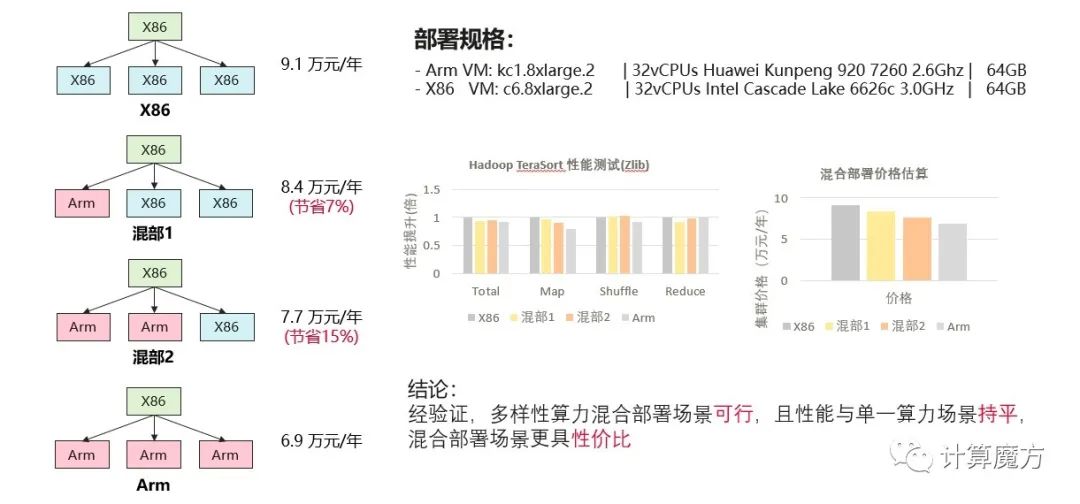
在混合部署的场景中,则为大家举了一个很直观的模拟场景,假设有3个数据节点,若全是单一架构的服务器,成本大概在9.1万元每年左右,随着多样性算力的不断加入,在保证算力性能基本持平的情况下,混合部署的成本能够降低7~15%。
Ask Me Anything

在最后的Ask Me Anything环节,有人问:Apache Spark在Arm优化上有什么计划吗?
来自华为的姜逸坤和郑振宇表示:目前Apache Spark 3.0.0版本已经完成了Arm支持,并且每天都会有Arm CI跑全量用例,来确保Spark在Arm可用,并且华为也会持续将Arm相关的优化推入到社区中,最新进展也将会为大家及时同步。
来自Databricks开源组技术主管,Apache Spark PMC & Committer范文臣也发表了自己的看法:Arm的支持不光是单一组件的问题,而是需要多个组件进行全面的支持,需要大家共同的努力,同时对华为在Hadoop、Spark社区为多样性算力支持所付出的努力表示认可和感谢。
总结
经过和现场同学的分享,在场的同学对多样性算力的有了初步了解,从活动的互动环节了解到,来自阿里巴巴、字节跳动、大众美团等公司的同学都已经开始或者有打算开始通过Arm启用多样性算力支持的计划。华为也将继续在Arm生态构建的路上不断耕耘,将更多的成果共享给整个生态,为多样性算力释放付出自己的努力。
文末福利

扫码关注,回复“0926” 获取 Hadoop Meetup 上海议题PPT。
