





前言
在互联网项目中比较常用到的关系型数据库是MySQL,随着用户和业务的增长,传统的单库单表模式难以满足大量的业务数据存储以及查询,单库单表中大量的数据会使写入、查询效率非常之慢,此时应该采取分库分表策略来解决。
提示:以下是本篇文章正文内容,案例仅供参考
业务场景介绍
假设目前有一个电商系统使用的是MySQL,要设计大数据量存储、高并发、高性能可扩展的方案,数据库中有用户表。用户会非常多,并且要实现高扩展性,你会怎么去设计?OK咱们先看传统的分库分表方式
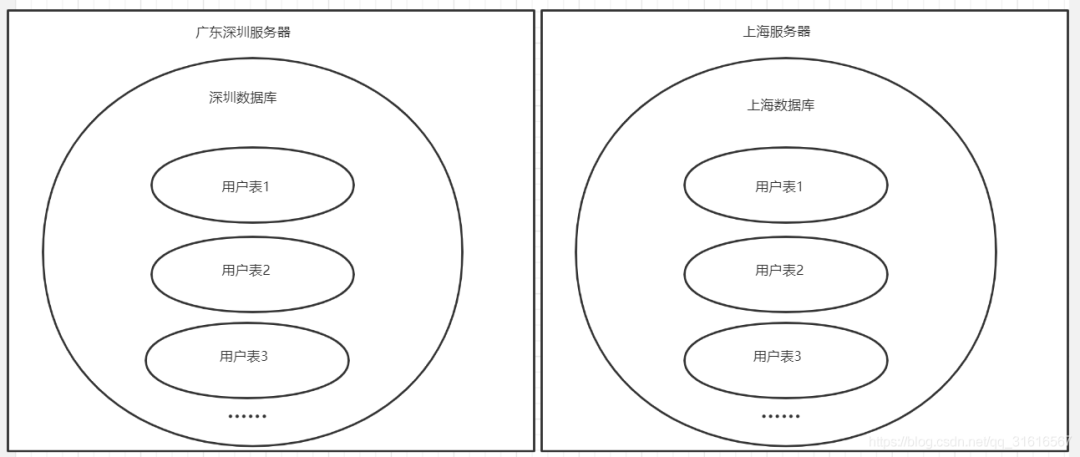
当然还有些小伙伴知道按照省份/地区或一定的业务关系进行数据库拆分
OK,问题来了,如何保证合理的让数据存储在不同的库不同的表里呢?让库减少并发压力?应该怎么去制定分库分表的规则?不用急,这不就来了
水平分库分表方法
RANGE
第一种方法们可以指定一个数据范围来进行分表,例如从1~1000000,1000001-2000000,使用一百万一张表的方式,如下图所示:
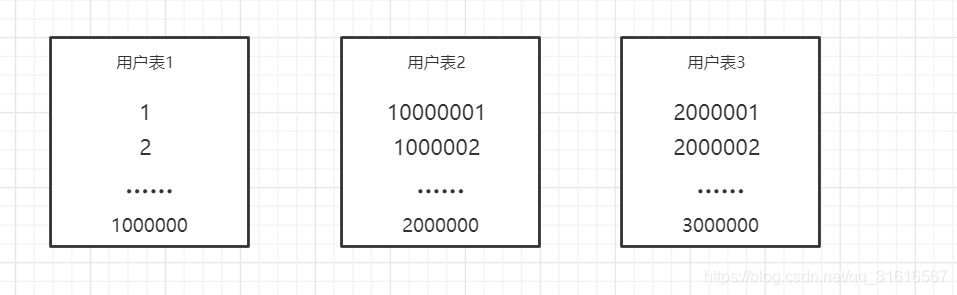
当然这种方法需要维护表的ID,特别是分布式环境下,这种分布式ID,在不使用第三方分表工具的情况下,建议使用Redis,Redis的incr操作可以轻松的维护分布式的表ID。
RANGE方法优点:扩容简单,提前建好库、表就好 RANGE方法缺点:大部分读和写都访会问新的数据,有IO瓶颈,这样子造成新库压力过大,不建议采用。
HASH取模
针对上述RANGE方式分表有IO瓶颈的问题,咱们可以采用根据用户ID HASG取模的方式进行分库分表,如图所示:
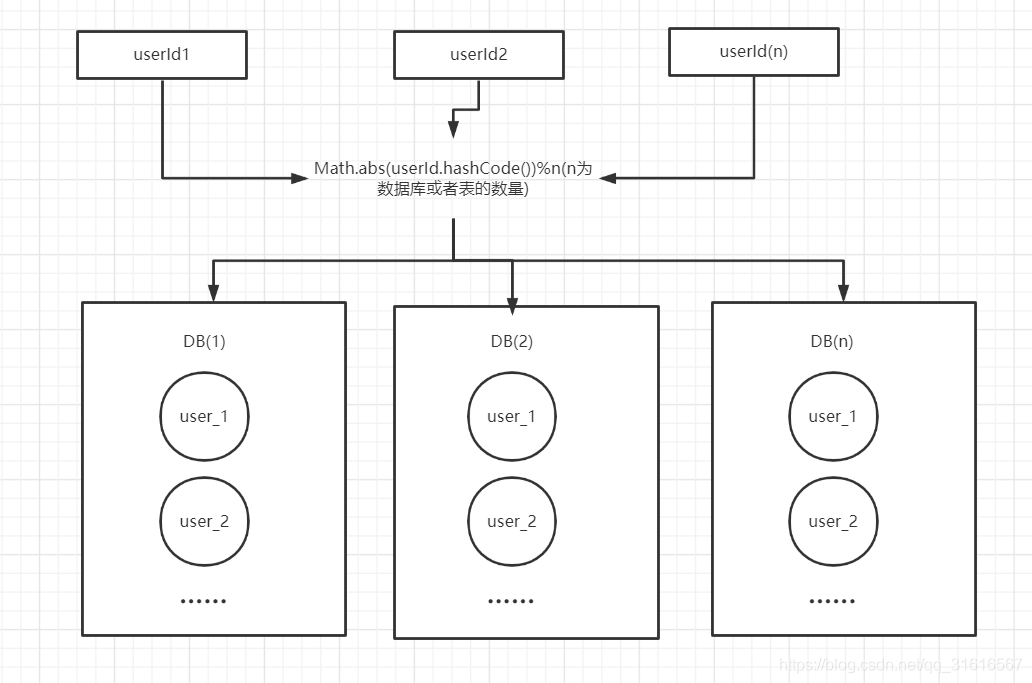
这样就可以将数据分散在不同的库、表中,避免了IO瓶颈的问题。
HASH取模方法优点:能保证数据较均匀的分散落在不同的库、表中,减轻了数据库压力。
HASH取模方法缺点:扩容麻烦、迁移数据时每次都需要重新计算hash值分配到不同的库和表。
一致性HASH
通过HASH取模也不是最完美的办法,那什么才是呢?
使用一致性HASH算法能完美的解决问题
普通HASH算法:
普通哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
普通的hash算法在分布式应用中的不足:在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%n,key是数据的key,n是机器节点数,如果有一个机器加入或退出集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
一致性HASH算法:
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个节点的空间中,即0~ (2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形,如下图所示。
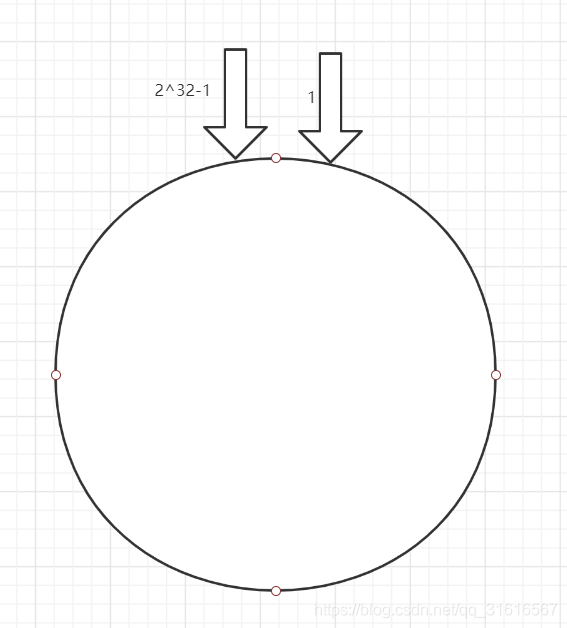
这个圆环首尾相连,那么假设现在有三个数据库服务器节点node1、node2、node3三个节点,每个节点负责自己这部分的用户数据存储,假设有用户user1、user2、user3,我们可以对服务器节点进行HASH运算,假设HASH计算后,user1落在node1上,user2落在node2上,user3落在user3上
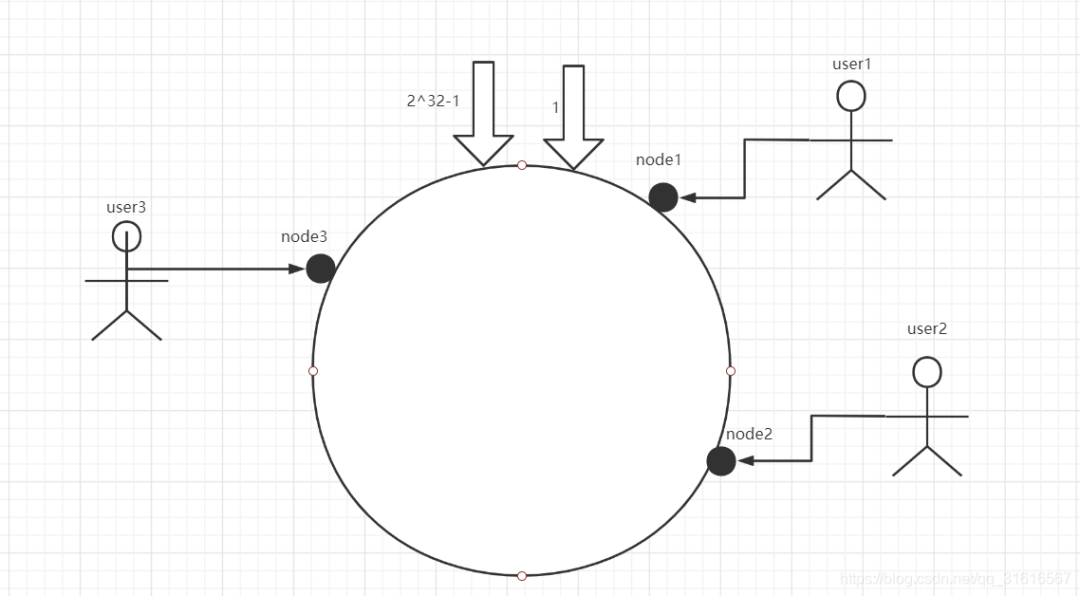
OK,现在咱们假设node3节点失效了。
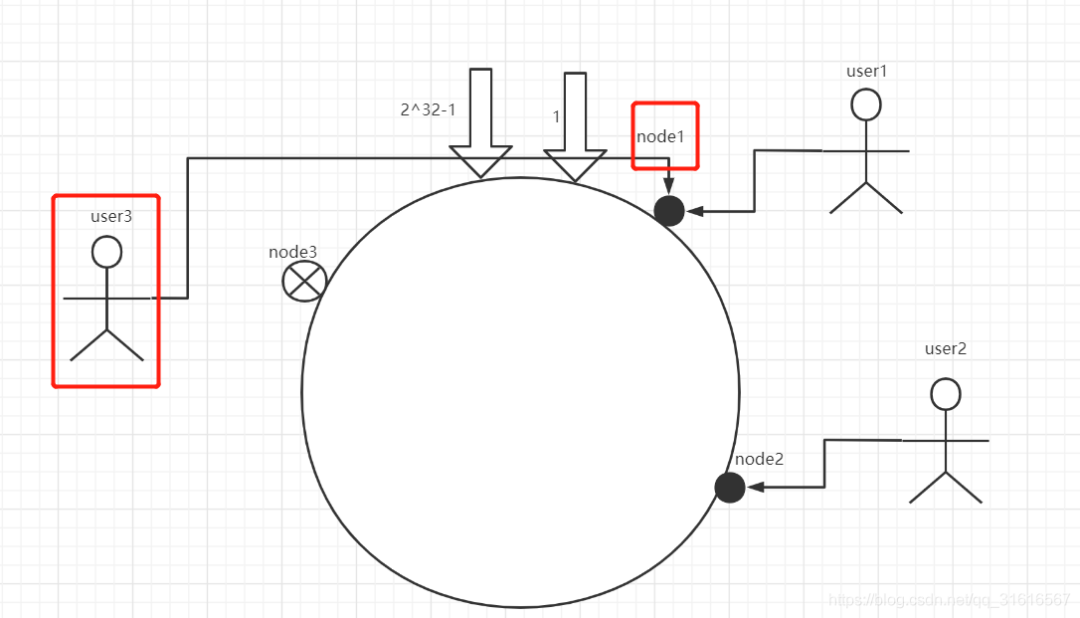
你会发现user3会落到node4上,你会发现,通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
当然还有一个问题还需要解决,那就是平衡性。从图我们可以看出,当服务器节点比较少的时候,会出现一个问题,就是此时必然造成大量数据集中到一个节点上面,极少数数据集中到另外的节点上面。
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个节点,称为虚拟节点。具体做法可以先确定每个物理节点关联的虚拟节点数量,然后在ip或者主机名后面增加编号。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “node 1-1”、“node 1-2”、“node 1-3”、“node 2-1”、“node 2-2”、“node 2-3”、“node 3-1”、“node 3-2”、“node 3-3”的哈希值,这样形成九个虚拟节点
例如user1定位到node 1-1、node 1-2、node 1-3上其实都是定位到node1这个节点上,这样能够解决服务节点少时数据倾斜的问题,当然这个虚拟节点的个数不是说固定三个或者至多、至少三个,这里只是一个例子,具体虚拟节点的多少,需要根据实际的业务情况而定。
一致性HASH方法优点:通过虚拟节点方式能保证数据较均匀的分散落在不同的库、表中,并且新增、删除节点不影响其他节点的数据,高可用、容灾性强。 一致性取模方法缺点:嗯,比起以上两种,可以认为没有。
总结
分库分表在分布式微服务架构环境下建议强烈使用一致性HASH算法来做,当然分布式环境下也会产生业务数据数据一致性、分布式事务问题,下期咱们再来探讨数据一致性、分布式事务的解决方案
转载于:https://juejin.cn/post/6923898244304994317
推荐阅读
SpringBoot常用注解速查,一键收藏了~ 建议收藏 | Linux 命令汇总 Java面试碰到这样的MyBatis面试题,你会回答吗? Java 100+ 经典面试题大全&答案,剑指名企Offer ! 实际开发中我们如何才能正确停止线程? 揭秘在使用多线程时为什么会带来性能问题? 关于wait/notify/notifyAll 方法的使用注意事项 都是线程安全,ConcurrentHashMap和Hashtable有什么区别? 实际工作中可能会遇到三类线程安全问题
干货分享
关注码上Java ,回复关键字面试宝典,领取一份嘟嘟平时收集的一些优质资源,包含咱们代码侠必备的优质简历模板、面试题库、电子书等资源大礼包一份(持续更新优质资源哦~),助力小伙伴们早日收获心仪offer,遇见更好的自己~
