




6月25日SIGMOD 2021圆满落下帷幕。数据管理国际会议(Special Interest Group on Management Of Data.)由美国计算机协会(ACM)数据管理专业委员会(SIGMOD)发起,是数据库领域具有最高学术地位的国际性学术会议。

2007年6月,第26届SIGMOD在北京举行,也是第一次在亚洲国家举行,当年来自中国大陆高校的论文仅有4篇。时隔14年SIGMOD在中国第二次举办,来自中国大陆高校的论文达到26篇,这离不开中国数据库领域研究者、从业者、开发者和用户的共同努力。作为本次大会的金牌赞助商,偶数科技、百度、VMware、Google、Oracle、Amazon、Snowflake等企业为SIGMOD 2021提供了大力支持。

SIGMOD 2021的Research Papers 188篇,Industrial Papers 21篇,接收率分别为42%和39%。Research Papers中第一作者来自北大8篇、清华6篇。

快速了解学术会议一般都从Keynotes(通常是由大咖做的主题报告)的内容入手,有些会议还安排针对特定研究的Tutorials(专题讲座,向观众分享论文的实践和落地过程)。参会者还可以根据行程和研究方向选择不同的Curated Sessions(分论坛),本届SIGMOD大会Curated Sessions涵盖了数据管理、数据结构、流计算、实用安全和数据库系统隐私、查询处理和优化、高性能系统、图数据、数据科学、分布式计算和云计算等领域。话不多说,接下来我们就通过Keynotes和Tutorials以及Best Papers,一起了解下大咖在顶会上分享了哪些硬核内容。
Keynotes
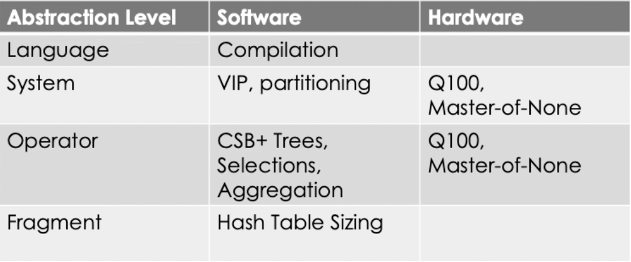
利用和设计现代硬件进行数据密集型计算:抽象的作用
Kenneth A. Ross (哥伦比亚大学)

包括数据管理系统在内的现代信息密集型系统大多都基于RAM,数据管理的研究人员和从业者自然将重点从I/O优化转移到内存结构中的性能上。Ross教授总结提炼了从上世纪70年代至今硬件在数据管理方面的跃迁,以及软件和硬件是如何进行复杂计算的设计,通过概念抽象给出了他的洞察:硬件平台的优化是可被理解和评估的。从单行代码到整个编程/查询语言,都可以被不同程度的抽象。
深度数据集成
Wang-Chiew Tan (Facebook AI)

在数据集成领域,深度学习技术促成了某些最先进的成果,包括信息提取、实体匹配、数据清理和表理解。Wang-Chiew通过虚拟数据集成、数据仓库、数据湖的演进阐述了深度数据集成的生态理念(包括强相关数据源的发现、数据抽取、schema匹配、实体匹配、数据清洗等方面)。通过案例(RoBERT/DistillBERT预训练的NLP模型进行实体匹配)讨论了深度学习的优势、挑战、潜在机遇。
演讲中Wang-Chiew也提到了ML大神Andrew Ng今年发表的一篇论文《以模型为中心转为以数据为中心的AI》,“当一个系统表现不佳时,许多团队会本能地尝试改进代码。但对于许多实际应用来说,更有效的方法是专注于改善数据。”“BERT、GPT-3等花哨的模型只占商业问题的20%。数据质量才区分部署水准的关键;每个人都可以得到预训练模型或授权API。”

深度数据集成的影响
有限计算资源下大数据计算的复杂性理论与高效算法
李建中 (哈尔滨工业大学)

虽然目前存在很多计算模型(如Map-Reduce), 但是这些计算模型都假定计算资源无限, 没有考虑大数据计算的资源受限特点。李教授重点介绍了大数据研究的理论方面,特别是大数据计算的复杂性理论和高效算法(压缩计算方法、(ε, δ)-近似计算方法、I/O高效计算方法),并分享了他的研究团队在大数据计算复杂性理论和高效算法方面取得的研究成果。
Tutorials
AI遇见DB: AI4DB与DB4AI
李国良(清华大学)

数据库和人工智能可以相互促进。一方面,人工智能可以使数据库更加智能(AI4DB),例如传统基于经验的数据库优化技术(如代价估算、连接次序、knob调优、索引建议)不能满足不同应用程序和用户对大规模数据库的高性能需求,尤其是数据库上云之后;另一方面,数据库技术可以优化AI模型(DB4AI),例如,复杂的代码和训练模型导致AI很难部署,数据库技术可降低人工智能模型使用的复杂度,加速人工智能算法,并在数据库内赋能AI。李国良教授回顾了关于AI4DB(基于学习的数据库配置、优化、设计、监控和安全方面的技术)和DB4AI(AI的声明语言、数据治理、训练加速和推理加速)的现有研究,并提出了AI4DB和DB4AI的研究挑战和未来发展方向。
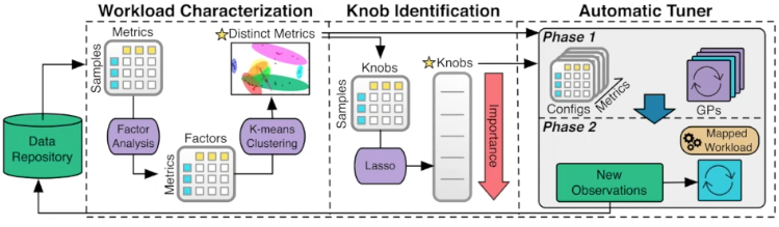
基于大规模机器学习的数据库系统调优
数据库系统的实用安全性和隐私性
Xi He(滑铁卢大学)

计算机技术使每个人生活中大量的数字痕迹得以收集、存储和应用分析,例如追踪新冠感染者的的密切接触者,同时也出现了个人隐私泄露等的问题。因此我们需要一种通用的、可信赖的、提供端到端安全和隐私保证的数据库系统。本节tutorial描述了不同设置下数据库系统的安全性和隐私需求及其对应工具,并演示了这些安全性和隐私数据库系统的设计原则和优化方向。
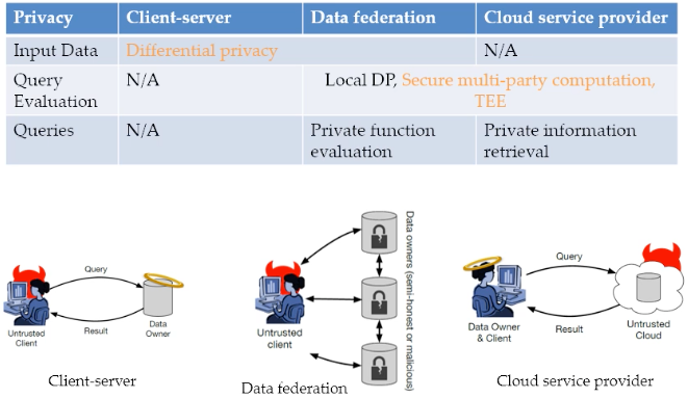
数据库系统安全技术与方法概要
深度学习:系统与责任
Abdul Wasay(哈佛大学)

本节tutorial特别关注三个关键方面:1) 从系统和数据管理的角度批判性地思考存储、数据移动和计算,神经网络经典权衡的问题可以变得更为丰富;2) 如果神经网络可以帮助甚至替代数据库系统组件(如优化器)作出决策,那么经典的数据系统设计问题也可以被重新审视;3) 神经网络应用于人类社会重大问题时,要将伦理道德与数据管理及系统性能联系起来考量。
神经网络权衡优化
别了,老古董SSD:存储设备协同设计时代展望
Alberto Lerner(瑞士弗里堡大学)

固态硬盘(SSD)领域正在不断发展,但这都是以块设备和POSIX I/O的抽象不变为前提。然而,这些抽象逐渐阻碍了性能并且无法继续简化软件。通过隐藏在内部机制的遗留接口使用SSD会导致不稳定的性能;另外,由于传统I/O抽象的不足,SSD和数据库管理系统(DBMS)的协同设计有望成为一个完整的研究领域。如何设计机制和策略耦合DBMS和SSD内部的存储管理器?作为大脑的SSD FTL可置于应用程序的控制之下,改变SSD子系统以响应工作负载;或者在SSD中代表数据库执行逻辑。Lerner通过DBMS/SSD协同设计技术提出了仿真原型,并认为数据库和存储未来的无缝集成是下一代数据库系统开发的核心。
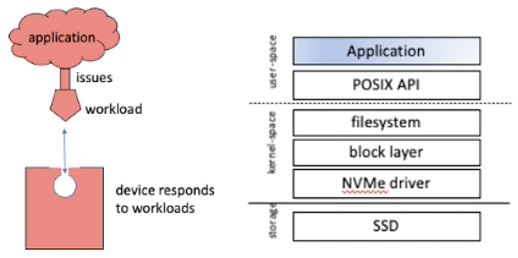
数据和控制的逻辑架构图
大型异构信息网络上的内聚子图搜索:应用、挑战和解决方案
林学民(新南威尔士大学)

异构信息网络(HINs)的应用(如社区搜索、朋友推荐)已经引起了学术界和工业界的广泛关注。本节Tutorial对现有的基于HINs的内聚子图搜索进行了全面的回顾,对这些工作中的模型和解决方案进行了分析和比较,并提出了新的研究方向。

组群推荐示例
许可链的属性、技术和应用
Amr El Abbadi(加州大学圣塔芭芭拉分校)

与免许可区块链(如比特币)不同,许可链的特点正在吸引大量大规模数据管理系统,但这些系统必须满足四个主要需求:机密性、可验证性、性能和可伸缩性。为了满足以上需求,可以针对不同假设和成本进行权衡。Amiri通过介绍供应链管理、大型数据库和多平台众包工作环境这三种不同的应用,展示了这些技术在现实生活中的实用性。
区块链账簿
通过深度学习方法研究Text-to-SQL系统
Georgia Koutrika(希腊雅典娜研究中心)

深度神经网络的发展,以及Text-to-SQL系统专有的大型训练数据集为该研究领域铺平了道路。本节tutorial涵盖神经网络中自然语言表示的最先进技术、引发研究和竞争的基准、基于深度学习技术Text-to-SQL系统。
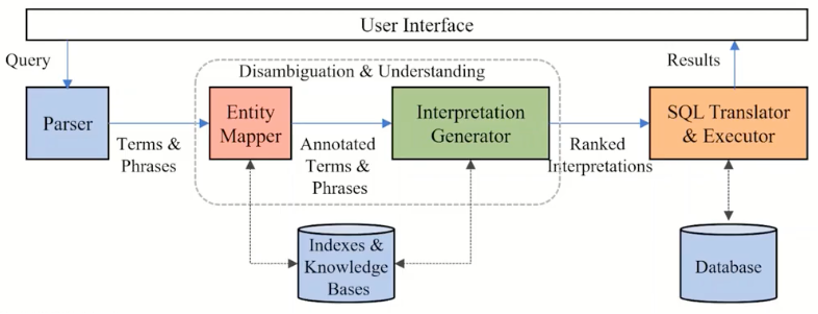
Text-to-SQL系统工作流
图数据库和知识图谱时代的查询
Marcelo Arenas(智利天主教大学)

图数据库和知识图谱在工业界已经有了成功的解决方案。本节tutorial提供这些开发背后的数据管理任务的概念图,以及数据模型和查询语言。
GNN(图神经网络)
最佳论文
Bao让智能查询优化切实可行
Ryan Marcus(麻省理工学院 & 英特尔研讨院)

Bao (the Bandit optimizer) 通过给予每个查询优化提示,使现有查询优化器更智能。Bao将现代树型CNN与汤普森采样(一种被广泛研究的强化学习算法)相结合。因此,Bao会自动从错误中学习并适应查询工作负载、数据及其schema的变化。实验证明了Bao可以快速学习策略以提高端到端查询性能,改善由多个长耗时查询的工作负载引起的尾部延迟。与商业系统相比,Bao在云上可以提供更低的成本和更好的性能。
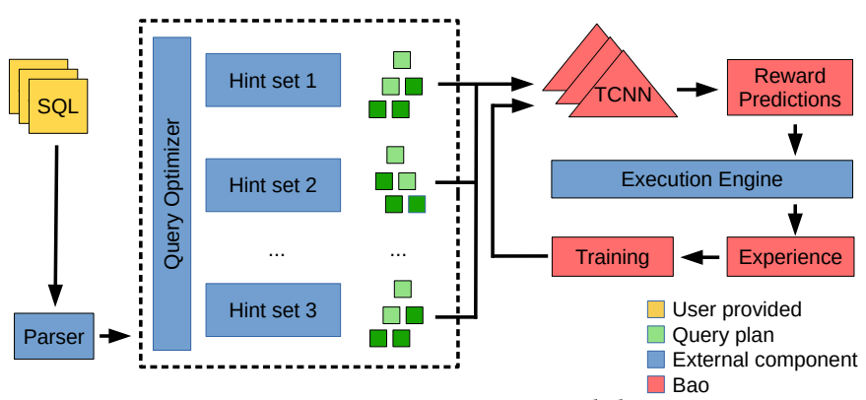
Bao的系统模型
DFI -高速网络的数据流接口
Lasse Thostrup(德国达姆施塔特工业大学)

数据流接口DFI (Data Flow Interface) 可以使数据处理系统更容易利用高速网络,而无需考虑RDMA的复杂度。DFI通过提高抽象层次,消除了网络通信的复杂性,使开发人员更容易通过声明来表示数据路径,进而完成分布式数据处理任务。实验表明,DFI能够支持各种以数据为中心的应用程序,同时保证应用程序的高性能和低复杂度。下图以流的初始化重置为例,流的执行是DFI上基于元组的push和消费原的例证。
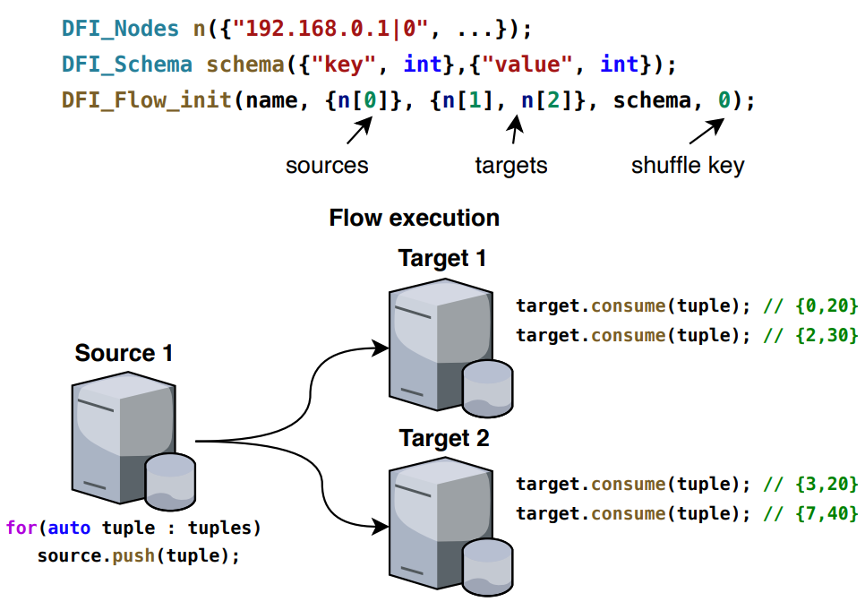
DFI的编程和执行模型
SliceLine:基于线性代数的切片快速查找可用于机器学习模型的调试
Matthias Boehm(奥地利格拉茨技术大学)

切片发现 (Slice finding)可找到top-K的数据切片(如“性别女性”、“学位博士”这样的并列链接谓语),但是数据切片模型的训练结果通常相对不佳。与决策树相比,一般的切片问题查找允许切片重叠,结果造成搜索空间巨大,因此现阶段主要停留在基于单节点内存的小数据集的启发式调试。该论文整体解决了切片查找的可伸缩性。利用切片大小、误差和结果分数的单调性进行剪枝。此外,论文提出了基于线性代数的简洁枚举算法,该算法在现有机器学习系统上进行快速枚举和自动并行化。通过真实的回归和分类数据集进行实验发现,有效的剪枝、高效稀疏的线代算法让精确枚举变得可行,甚至在超出单节点内存的数据集上也可实现。
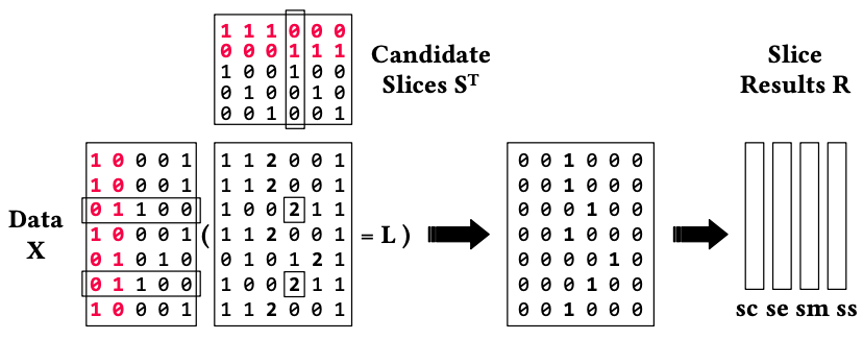
切片矢量化评估示例
热点话题
Cloud-Native
经过近些年的高速发展,云计算现在已经不如从业者视野。云原生不仅仅是将物理机换成云上的虚拟机,更重要的是软件(特别是基础软件DBMS)要根据云环境的特点重新设计和实现,进而才能充分发挥云环境的优势。本届SIGMOD大会中很多学者也从硬件跃迁的角度来探究数据库管理系统的研究方向。
AI for System
过往经常提 Systems for AI,现在已经开始讨论 ML for Systems。尽管SIGMOD 2018就出现了这个方向的论文——《智能索引结构案例》,但在本届大会各类演讲中被多次提及成为热门话题。当然其中也不乏争议,如机器学习现阶段的可解释性下不能满足数据库开发者的常见的查询计划分析等工作场景。
