




之前谈过ArrayList的扩容,它是一个动态数组,插入删除元素都需要移动元素,扩容则需要进行数组拷贝,今天我们来聊聊真正动态的数据结构
LinkedList,顾名思义,链表存储数据的容器称为结点,每个结点之间用一个或者两个链串起来形成一种无需扩容的结构。这样一种数据结构,无需处理固定容量,但是也因此牺牲了其随机访问的效率,不能通过索引查找,需要遍历到对应位置进行插入或者删除
1 链表
1.1 什么是链表
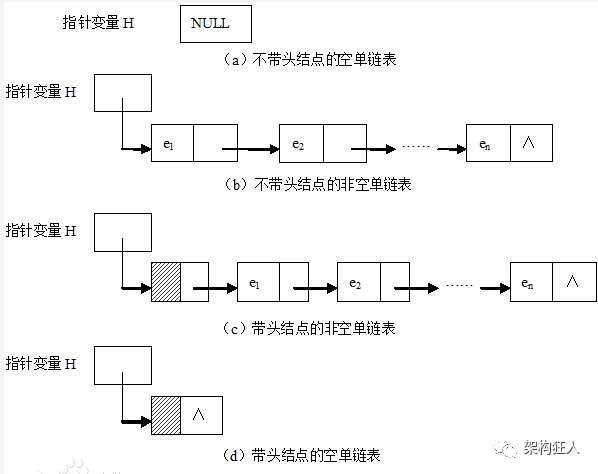
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可以动态生成
百度百科中定义的单链表:(指针变量可以不用管)
1.1 链表的作用
将数据按照一定顺序串联存储在结点中,允许在任意位置插入和删除结点,且无需处理固定容量,做到动态添加和删除
1.2 单向链表
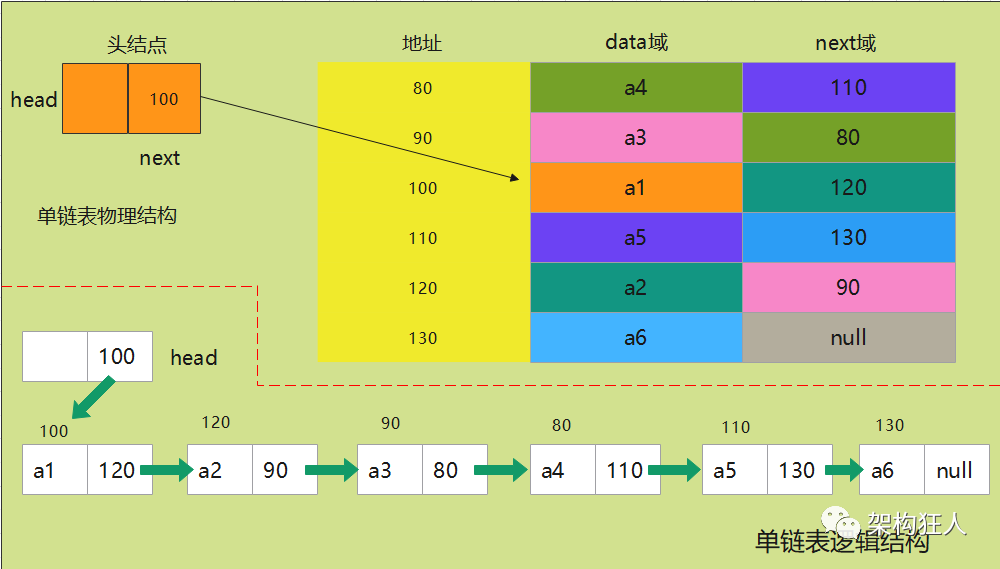
一个结点中包含数据和下一个节点的地址,尾节点没有下一个结点,所以指向null。访问某个节点只能从头节点开始查找,然后依次往后遍历
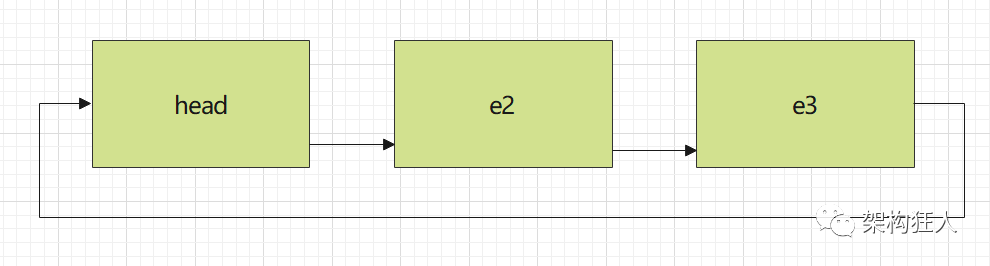
单向循环链表:单链表基础上,尾结点next指向头结点
1.3 双向链表
双向链表的每个结点包含以下数据:上一个结点的地址,自身结点数据,下一个结点的地址.尾结点没有下一个结点,所以指向null。这样的结构,比如我拿到链表中间的一个节点,即可以往前遍历,也可以往后遍历,这是双向链表的优势
双向循环链表的尾结点的下一个结点是头结点,头结点的上一个节点是尾结点
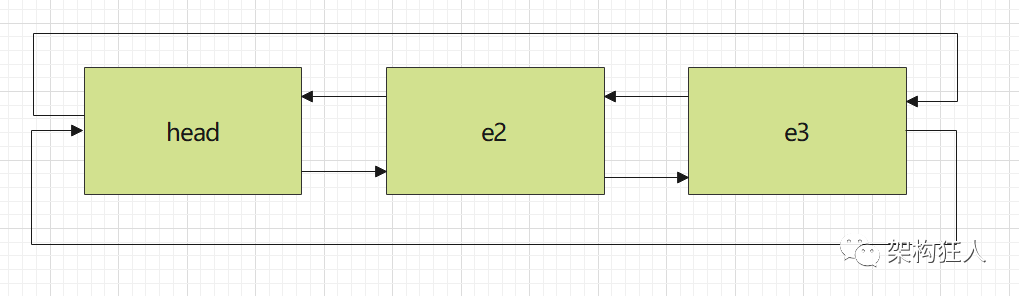
2 LinkedList各个版本对比
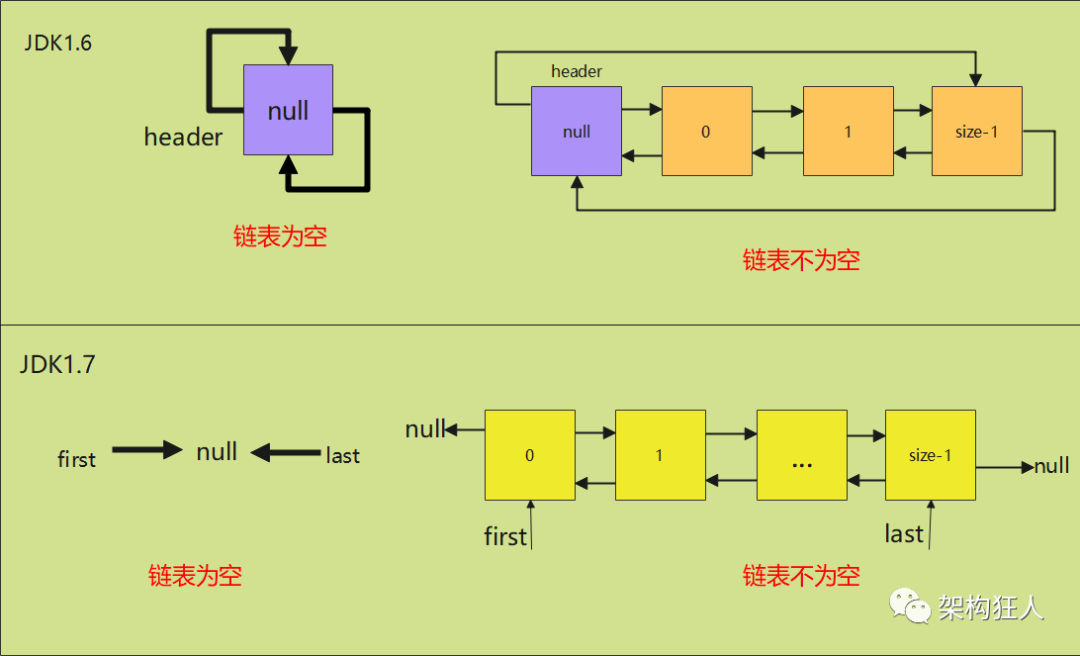
(1) JDK1.6使用的是一个带有头结点的双向循环链表,头结点不存储实际数据
(2) JDK1.7之后使用的是不带头结点的普通的双向链表,增加两个节点指针first、last分别指向首尾节点,相比之前节约了head结点的部分内存,其他并无太大差别
3 LinkedList重要属性及方法

//记录链表中节点的个数transient int size = 0;//记录链表中第一个节点transient Node<E> first;//记录链表中最后一个节点transient Node<E> last;private static class Node<E> {E item; //当前节点保存的数据Node<E> next;//指向下一个结点的引用Node<E> prev;//指向上一个结点的引用Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
LinkedList继承自Deque,所以需要支持removeFirst、removeLast等一系列操作,因此需要First、Last记录首尾结点
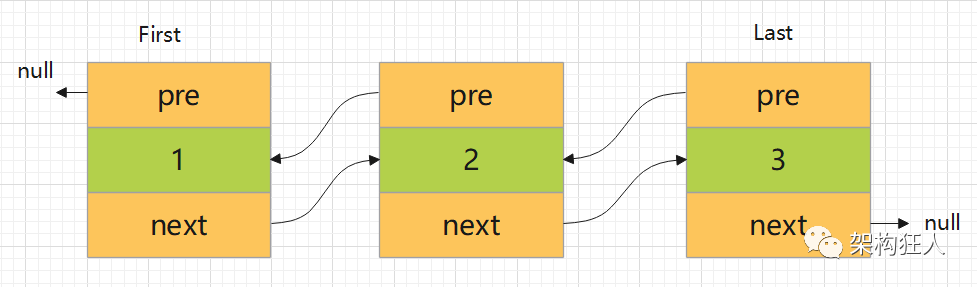
3.1 添加元素
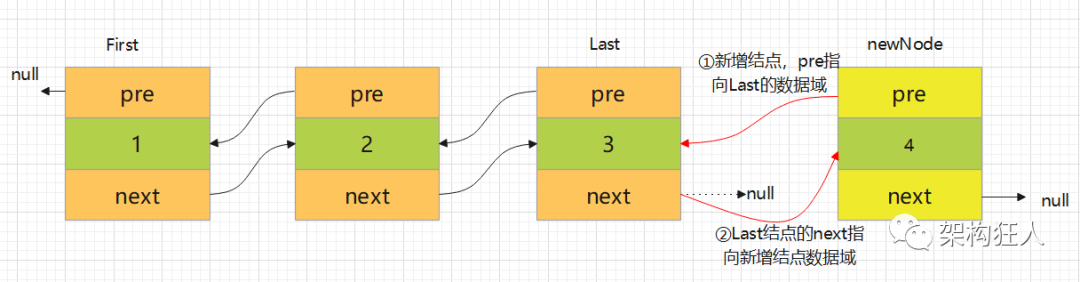 流程图:
流程图:
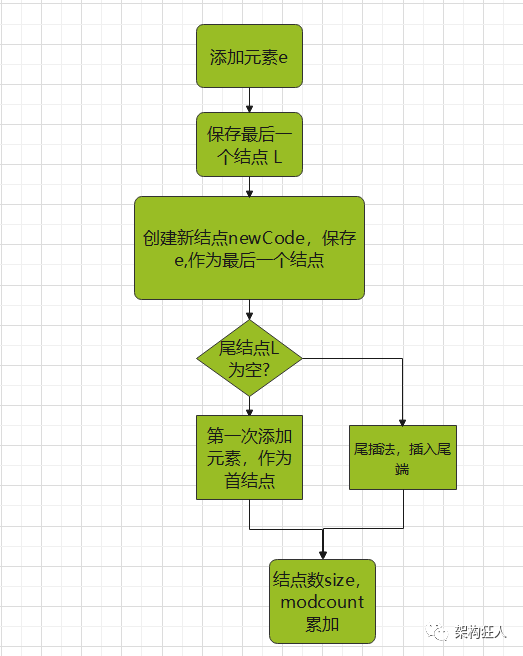
public boolean add(E e) {linkLast(e);return true;}void linkLast(E e) {//获取最后一个节点final Node<E> l = last;//这里创建出一个新的节点,它的前一个节点指向l,要保存的数据即传入进来的数据,后一个节点为nullfinal Node<E> newNode = new Node<>(l, e, null);//接着将这个新节点当做链表的最后一个节点保存起来last = newNode;//如果刚开始最后一个节点为null,说明是第一次添加if (l == null)first = newNode;else//否则将刚开始最后一个节点的下一个节点的引用指向新创建的节点l.next = newNode;size++;modCount++;}
3.2 获取元素
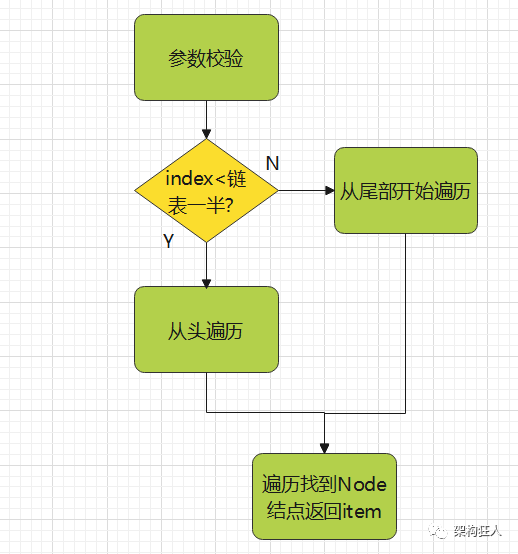
public E get(int index) {//参数合法检验checkElementIndex(index);return node(index).item;}//取该节点保存的值并返回Node<E> node(int index) {//index如果小于链表大小的一半,则从头遍历if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {//index如果大于等于链表大小的一半,则从尾部遍历Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
3.3 删除元素
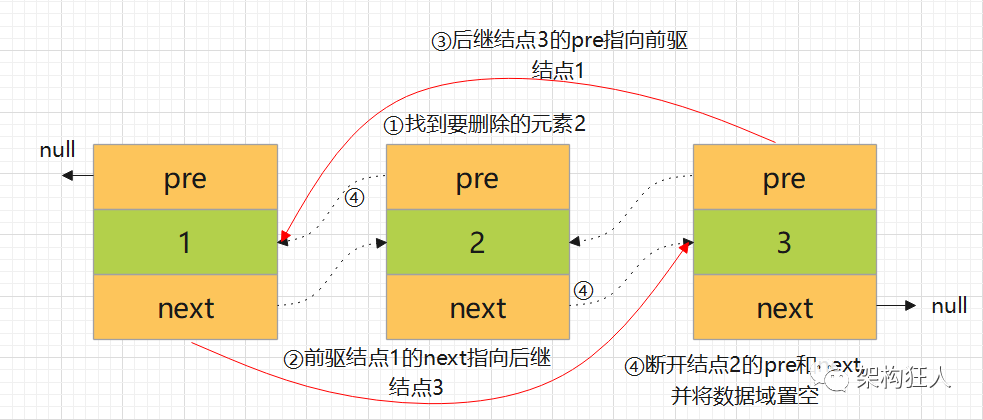
public E remove(int index) {checkElementIndex(index);return unlink(node(index));}E unlink(Node<E> x) {//分别保存当前要删除节点的值、前置节点、后置节点final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;//前置节点为null,说明当前节点为首节点if (prev == null) {first = next;} else {//前置节点不为null,将前置节点的next后移prev.next = next;x.prev = null; //(1)}//后置节点为null,说明当前节点为尾节点if (next == null) {last = prev;} else {//后置节点不为null,将后置节点的prev指向前置节点next.prev = prev;x.next = null; //(2)}x.item = null; //(3)size--;modCount++;return element;}
注意删除元素(1)、(2)、(3)处,置空避免内存占用考虑垃圾回收
4 LinkedList和ArrayList的区别
(1)内存位置比较
ArrayLst基于动态数组,所以内存上是连续的,而LinkedList基于链表,内存上不需要保持连续。
(2)插入速度比较
经常听到LinkedList插入比ArrayLst快。这种说法不准确。LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Node的引用地址,而ArrayList做插入、删除的时候,慢在数组元素的arrCopy,快在寻址。
①如果待插入的元素位置在数据结构的前半段尤其是非常靠前时,ArrayList需要拷贝大量的元素,显然LinkedList会更快
②如果带插入元素位置在数据结构后半段尤其是非常靠后,ArrayList需要拷贝的元素个数会越来越少,所以速度也会提升,甚至超过LinkedList
4 LinkedList 遍历的探索
一般遍历LinkedList时最好不要使用普通for循环,而是使用迭代器代替,这是为什么呢?
//以下是for循环遍历for(int i =0;i<list.size();i++){list.get(i);}//迭代器遍历Iterator<String> it = list.listIterator();while(it.hasNext()){System.out.print(it.next()+" ");}
从上面代码可见,iterator相比for循环少了list.get(i),调用一次get(i)时间复杂度为O(n),嵌套一次for循环就是O(n²),而在iterator中因为next的存在get当前元素不需要时间所以循环下来应该是O(n)
5 小结
(1)承自 AbstractSequentialList 接口,同时了还实现了 Deque, Queue 接口,可以用来模拟堆栈,队列,双端队列结构
(2)LinkedList从1.7开始采用不带头结点的双向链表结构,相比1.6去掉了头结点
(3)由于结点只存储数据域和前驱、后继结点的地址,和元素值无关,因而可以插入空值,同时允许重复插入
(4)LinkedList默认通过尾插法新增元素,也可以通过addFirst的头插法方式,两者都需要判断是否第一次添加元素
(5)相比基于动态数组的ArrayList,LinkedList随机访问的性能不如ArrayList,通过链表的方式换来优秀的增删效率
(6)LinkedList结构对内存要求低,不需要大块连续内存来满足扩容,能够自动动态地消耗内存,容量变小时会自动释放曾经占用的内存,ArrayList则需要手动trim
