




HashMap可谓面试必问的问题了,采用哈希表的结构存储数据,我们知道不同的key经过哈希运算可能会出现相同的hashcode,哈希冲突是哈希表必须面对的问题,今天咱们来掰扯掰扯它是如何解决hash冲突的(本文基于Jdk1.7)
避免大家,被大量代码劝退,这里我只贴少量重要的代码,尽量浓缩精华,并结合图示讲清楚HashMap是如何扩容的。
1数据结构
数组+链表,俗称拉链法。
核心:Entry对象的数组+多个单链表,Entry对象存放实际的key和value。
1.1存储示意图
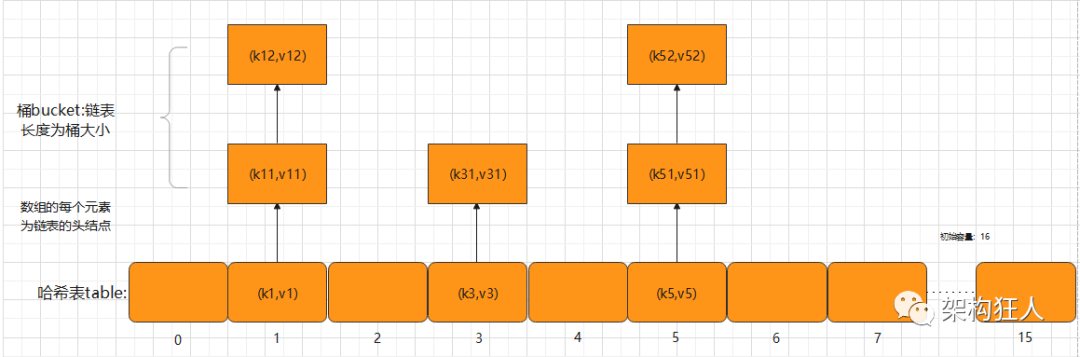
①初始默认容量capacity:16,不传容量的构造方法默认16,带容量参数的初始化方法会通过roundUpToPowerOf2方法初始到该参数的最小2幂次方数(上限为2的30次方),比如传入17,则capacity为32。
②扩容阈值threshold:容量x加载因子,当哈希表的大小 ≥ 扩容阈值时,进行双倍扩容。
③ 加载因子Load factor:0.75,空间和时间的折衷。因子过大,空间利用率大,元素多,冲突概率增大,链表变长,查找效率低;因子过小,空间利用率小,冲突小,链表短,查找效率高。
2 存储方式
2.1 初始化
注意数组table初始化是第一次调用put,作者设计采用懒加载的思想。
public HashMap(Map<? extends K, ? extends V> m) {// 设置容量大小、加载因子this(Math.max((int) (m.size() DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);// 该方法用于初始化 数组 、阈值,下面会详细说明inflateTable(threshold);// 将传入的子Map中的全部元素逐个添加到HashMap中putAllForCreate(m);}
2.2 put
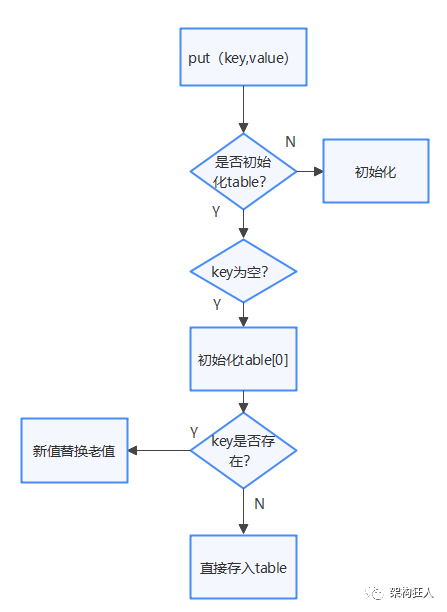
计算下标 : hashcode & (length-1)
(1)让entry分布均匀,尽量避免出现hash值冲突。
(2)使得hash码都在数组大小范围内,有的放矢。
(3)不用模运算,采用与运算更加高效
(4)由于table长度总是2的幂次方数,length-1则为奇数,所以最终位置取决于hashcode,避免哈希冲突
(5)只有当数组长度为2的幂次方数时,h&(length-1)<=>h%length
public V put(K key, V value) {//1.table为空,先初始化tableif (table == EMPTY_TABLE) {inflateTable(threshold);}//2.key为0,初始化table[0]if (key == null)return putForNullKey(value);//3.计算hash值,下标,为了使得元素更加分布更加散列,采用hashcode运算+扰动处理(4次位运算+5次异或运算)int hash = hash(key);int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;//4.key已经存在,替换新值,返回老值if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;//5.直接添加新数据addEntry(hash, key, value, i);return null;}
2.2.1 addEntry
(1)插入前,先判断容量是否足够
(2)若不够,则进行2倍扩容,重新计算Hash值、重新计算存储下标
(3)若容量足够,则创建1个新的Entry数组元素,通过createEntry
2.2.2 transfer
(1)获取新数组容量大小
(2)遍历老数组,将老数组的数据,通过头插法转移到新数组,转移后链表逆序,即转移前:1->2->3,转移后:3->2->1,若此时又有新的线程put元素,可能出现环型链构成死循环
2.3 get
(1)计算hash值
(2)计算数组下标
(3)遍历该下标的元素为头结点的链表所有节点,根据key寻找value
public V get(Object key) {// 1. 当key == null时,table第1个元素(即table[0])为头结点的链表去寻找对应 key == null的键if (key == null)return getForNullKey();// 2. 当key ≠ null时,去获得对应值Entry<K,V> entry = getEntry(key);return null == entry ? null : entry.getValue();}final Entry<K,V> getEntry(Object key) {if (size == 0) {return null;}// 1. 根据key值,通过hash()计算出对应的hash值int hash = (key == null) ? 0 : hash(key);// 2. 根据hash值计算出对应的数组下标// 3. 遍历 以该数组下标的数组元素为头结点的链表所有节点,寻找该key对应的值for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {Object k;// 若 hash值 & key 相等,则证明该Entry = 我们要的键值对// 通过equals()判断key是否相等if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;}
2.4 扩容机制
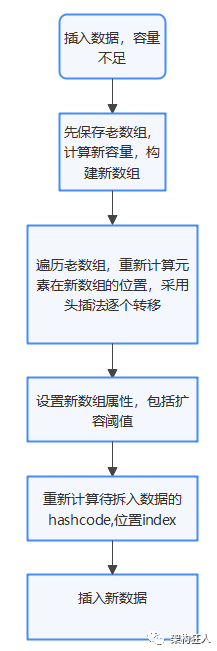
void resize(int newCapacity) {// 1. 保存旧数组Entry[] oldTable = table;// 2. 保存旧容量,即数组长度int oldCapacity = oldTable.length;// 3. 若旧容量已经是系统默认最大容量了,那么将阈值设置成整型的最大值,退出if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}// 4. 根据新容量(2倍容量)新建1个新数组,Entry[] newTable = new Entry[newCapacity];// 5. 将旧数组上的数据(键值对)转移到新table中,见下方transfer(newTable);// 6. 新数组table引用到HashMap的table属性上table = newTable;// 7. 重新设置阈值threshold = (int)(newCapacity * loadFactor);}void transfer(Entry[] newTable) {// 1. src引用了旧数组Entry[] src = table;// 2. 获取新数组的大小,设置新容量int newCapacity = newTable.length;// 3. 通过遍历 旧数组,将旧数组上的数据(entry)转移到新数组中for (int j = 0; j < src.length; j++) {// a.取得旧数组的每个元素Entry<K,V> e = src[j];if (e != null) {// b.释放旧数组的对象引用(for循环后,旧数组不再引用任何对象)src[j] = null;do {//c.遍历 以该数组元素为首 的链表// 注:转移链表时,因是单链表,故要保存下1个结点,否则转移后链表会断开Entry<K,V> next = e.next;// d.重新计算每个元素的存储位置int i = indexFor(e.hash, newCapacity);//e.将元素放在数组上:采用单链表的头插入方式 = 在链表头上存放数据 = 将数组位置的原有数据放在后1个指针、将需放入的数据放到数组位置中// 即 扩容后,可能出现逆序:按旧链表的正序遍历链表、在新链表的头部依次插入e.next = newTable[i];newTable[i] = e;// 访问下1个Entry链上的元素,如此不断循环,直到遍历完该链表上的所有节点e = next;} while (e != null);}}}
总结
1. hashmap采用hash表结构存储键值对数据,通过数组+单链表(拉链法),解决hash冲突
2. 初始容量16,大小总是为2的幂次方数,加载因子为0.75,阈值=容量x加载因子,超过此值进行2倍扩容
3. 采用多重与运算,异或运算进行扰动操作,hash & (length-1) 使得哈希表分布尽量均匀,减少hash碰撞,当出现hash碰撞,会将键值对挂在bucket形成单链表
4. 扩容后采用头插法,转移旧的元素,会出现单链表逆序,此时若有新元素插入可能形成循环链,get元素造成死循环,因而hashmap不是线程安全的数据结构
