





这是万物可述的第36篇文章
Greenplum简介
Greenplum 数据库(GPDB)是一个无共享的大规模并行处理数据库,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能(OLAP)和数据挖掘等。
GPDB 专为海量数据分析而生,使用最先进的基于成本的查询优化器,是目前最为先进的开源数据库之一,能对 PB 级数据进行快速高效的查询、分析。
Greenplum的架构采用了MPP(大规模并行处理)。
在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。
换言之,每个节点内的 CPU 不能访问另一个节点的内存。
节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution) 。
与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为 MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。
这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。
Greenplum的架构
1.Greenplum总体架构如下:
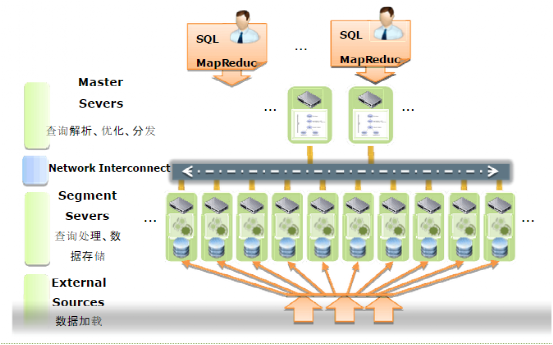
图示:Greenplum架构
数据库由Master Severs和Segment Severs通过Interconnect互联组成。
Master节点:是整个系统的控制中心和对外的服务接入点,它负责接收用户SQL请求,将SQL生成查询计划并进行并行处理优化,然后将查询计划分配(dispatch)到所有的Segment节点进行并行处理,协调组织各个Segment节点按照查询计划一步一步地进行并行处理,最后获取到Segment的计算结果,再返回给客户端。
从用户的角度看Greenplum集群,看到的只是Master节点,无需关心集群内部的机制,所有的并行处理都是在Master控制下自动完成的。Master节点一般只有一个或两个(互为备份)。
Segment节点:是Greenplum执行并行任务的并行运算节点,它接收Master的指令进行MPP并行计算,因此所有Segment节点的计算性能总和就是整个集群的性能,通过增加Segment节点,可以线性化得增加集群的处理性能和存储容量,Segment节点可以是1~10000个节点。
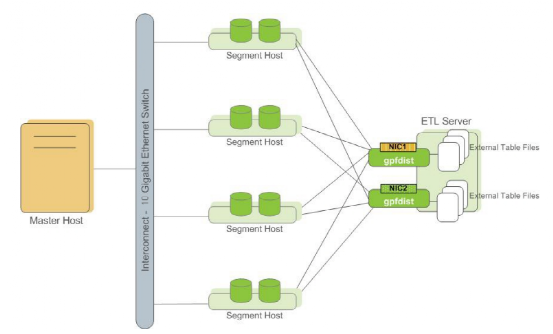
Interconnect:是Master节点与Segment节点、Segment节点与Segment节点之间的数据传输组件,它基于千兆交换机或万兆交换机实现数据在节点间的高速传输。
外部数据加载到Greenplum时,采用并行数据流进行加载,直接加载到Segment节点,这项独特的技术是Greenplum的专有技术,以此保证外部数据在最短时间内加载到数据库中。
2.基本体系架构
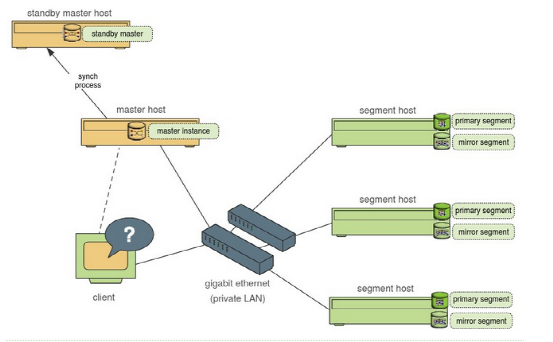
Master host 与standby master host通过同步进程保持与master host的数据一致,当master host出现故障时,standby master host 担任它的全部工作。
Segment host节点:每个segment(段)存放一部分用户数据,一个系统可以建立多个segment;用户不能直接存取访问;所有对segment的访问都要经过master节点;数据库监听进程(postgres)监听来自Master的连接。
Greenplum的数据分布及并行加载与卸载介绍
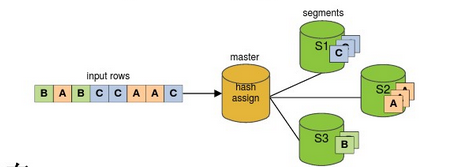
1、Greenplum的数据分布,Greenplum中建表必须制定分布键,如不指定就默认首字段为分布键。数据分布的形式有两种:
HASH分布:create table....distributed by (column,...)
同样哈希值的内容被分配到同一个Segment上
随机分布:create table.... distributed by randomly
数据被均匀地分布到所有的Segment上
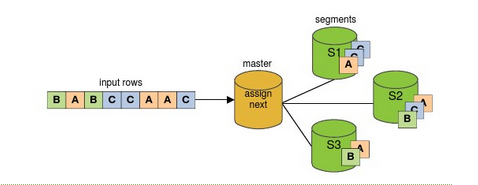
如果因为分布键的设置不合理,会极大影响Greenplum集群的性能,因为分布键的设置不合理,会导致数据倾斜,而集群的响应速度取决于最慢的segment的。
2、Greenplum的并行加载与卸载,需要用到并行文件服务gpfdist组件模块,能够实现最大并行度、加载带宽,默认greenplum集群已经有了已经安装了gpfdist,但是如果在单独的服务器上,还是需要再次安装的单独的组件,需要下载一个loaders的组件安装包进行安装。
然后通过使用gpfdist服务,创建可读外部表读取文件进行加载数据,创建可写外部表直接从库表中把数据插入到可写外部表从而实现数据的卸载。
操作步骤如下:
 启动gpfdist服务:
启动gpfdist服务:
gpfdist -d data/ -p 8081 -l data/log/gpfdist.log -m 102400000 &
-d:制定gpfdist服务数据目录
-p:指定端口号
-l :指定gpfdist日志路径
-m:指定gpfdist服务一行数据可读取或写入大小
 对普通用户赋创建外部表和执行外部表权限
对普通用户赋创建外部表和执行外部表权限
gpconfig -c gp_external_grant_privileges -v on
gpconfig -c gp_external_enable_exec -v on
 创建外部表,进行加载和卸载
创建外部表,进行加载和卸载
create external table table_name(.......);
Gpfdist服务的架构如下图所示:
Greenplum的启动与停止
1、Greenplum数据库的启动
master节点上执行gpstart 命令启动GPDB,gpstart -m 启动维护模式(不影响segment 数据,不要轻易使用)
2、Greenplum数据库的停止
gpstop --停止数据库
gpstop -u --仅重新加载配置文件不停库
gpstop -M fast --快速停库,常用
gpstop -r --重新数据库
pg_cancel_backend(pid) --取消数据库进程
pg_terminate_backend(pid) --终止数据库进程
Greenplum客户端认证配置
客户端认证配置是由pg_hba.conf配置文件控制可访问的ip,此配置文件一般存储在/data/master/gpseg-1.
配置步骤:
一、在pg_hba.conf文件中添加要访问数据的ip及数据库名
二、在master上执行gpstop -u 使配置文件生效
pg_hba.conf 文件结构:
#host database user ip option
#例如:
host edwdb gpadmin 10.134.85.14/32 trust
host all gpadmin 10.134.84.0/24 md5
Host all reader 10.134.0.0/16 md5
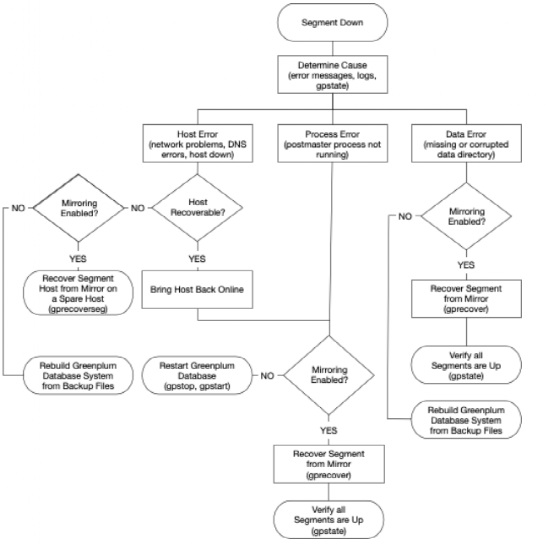
Segment节点down掉处理流程
一般处理流程见下图:
作者:娄陈
编辑:徐菲

据说中国有句古语叫「金无足赤,人无完人」,但是,如果谁真的想打起灯笼来到市面上寻找完人,最终令他感到的可能不是一种失望,而是一种意外:完人可能就是那些终日为「善」而奔走,而又在不知不觉中实现了「美」的「真」实不虚的普通人。
追求完美是正常而有缺憾的人性。
--尼采

