





这是万物可述的第35篇文章
OLAP数据库概述
OLTP,联机事务处理
它是传统的关系型数据库的主要应用,是用来基本的、日常的事务处理的;
主要强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
主要的数据库有oracle,DB2,GaussDB T等。
OLAP,联机分析处理
数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且可以提供直观易懂的查询结果;
主要强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等;
主要有teradata,GaussDB A,Greenplum等。
GaussDB A概述
GaussDB A是企业级的大规模并行处理关系型数据库。其采用MPP架构,支持行存储与列存储,提供PB级别数据量的处理能力。
GaussDB A在核心技术上跟传统数据库相比有巨大优势,可以解决很多行业用户的数据处理性能问题,可以为超大规模数据管理提供高性价比的通用计算平台,并且可以用于支撑各类数据仓库系统、BI系统和决策支持系统,统一为上层应用的决策分析等提供服务。
产品介绍 - 应用场景
GaussDB A面向行业大数据应用,适用于以下场景:
详单查询
具备PB级数据负载能力,通过内存分析技术满足海量数据边入库边查询要求,适用于安全、电信、金融、物联网等行业的详单查询业务。
数据仓库
具备百TB级数据支撑能力,可以高效处理百亿行多表连接查询,适用于操作数据存储ODS、企业数据仓库EDW、数据集市DM。
混合负载
基于海量数据查询统计分析能力与事务处理能力,行列混存技术同时满足联机事务处理OLTP与联机分析处理OLAP混合负载场景。
大数据分析
具备结构化数据PB级分析能力。分布式并行数据库集群满足PB级结构化大数据的分析能力。
产品介绍 - 技术特点
GaussDB A具有低成本、高性能、高可靠和支持海量数据存储的特点。
低成本
基于分布式x86架构,客户硬件投资成本低。
支持标准的SQL92规范,支持客户应用系统平滑迁移。
高性能
行列混合存储引擎,数据按照最优负载模型选择存储方式,性能更优。
支持基于服务等级协议SLA策略的负载管理,保障并发任务的服务质量。
支持基于代价的查询优化模型,提升复杂查询性能。
分布式、并行化的查询处理模型,充分利用系统计算资源和IO资源。
支持并行数据导出和导入。
高可靠
硬件级高可靠:磁盘Raid、交换机堆叠及网卡bond、不间断电源UPS。
软件级高可靠:集群CM、CN、GTM、DN实例全方位HA。
数据存储安全可靠:在安全认证的基础上,支持数据在数据库内的加密存储,防止第三方人员绕过数据库认证机制直接读取数据文件中的数据。
支持海量数据
集群最大可扩展至2048个节点,支撑PB级数据管理能力。
集群规模按用户需求弹性伸缩,扩展业务不中断,减少用户投资成本
数据库对象设计
Database和Schema设计
推荐使用Schema进行业务隔离,避免发生意外
建议系统管理员创建Schema和Database,再赋予相关用户对应的权限
表设计
将表的扫描压力均匀分散在各个DN上。避免扫描压力集中在部分DN上,从而导致性能瓶颈
减少需要扫描的数据量。通过分区表的剪枝机制可以大幅减少数据的扫描量,对于全表扫描而言,分区表查询效率较快
字段设计
尽量使用高效数据类型
当多个表存在逻辑关系时,表示同一含义的字段应该使用相同的数据类型。
约束设计
给明确不存在NULL值的字段加上NOT NULL约束
视图和关联表设计
视图定义中尽量避免排序操作
表之间的关联字段应该尽量少
关联字段的数据类型应该保持一致
数据库逻辑结构图
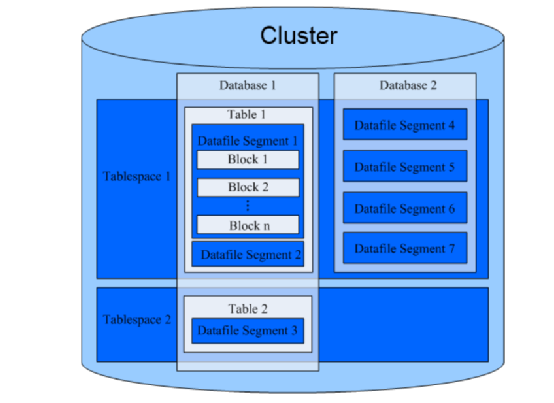
物理文件。每个表空间可以对应多个数据库。
Database,就是数据库,主要用于管理各类数据对象,各个数据库之间相互隔离。数据库管理的对象可分布在多个表空间。
Datafile Segment,就是数据文件,通常每张表只对应一个数据文件。比如哪一张张表的数据大于1GB,那么就会分为多个数据文件进行存储。
Table,就是表,每张表只能属于一个数据库,也只能对应到一个表空间,不可能存在多个数据库或者多个表空间。每张表对应的数据文件必须在同一个表空间中。
Block,就是数据块,它是数据库管理的基本单位,一般默认大小为8KB。数据在不同的DN上有三种分布方式,可以在建表的时候指定:REPLICATION、ROUNDROBIN 、HASH。
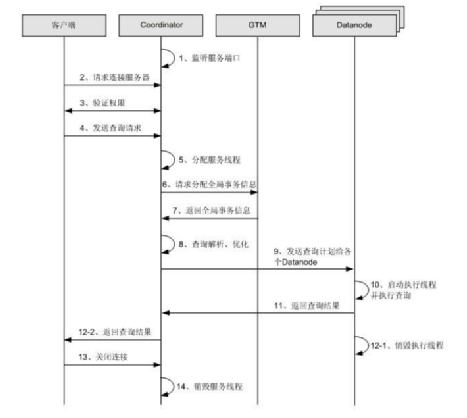
数据查询请求处理过程
性能调优流程
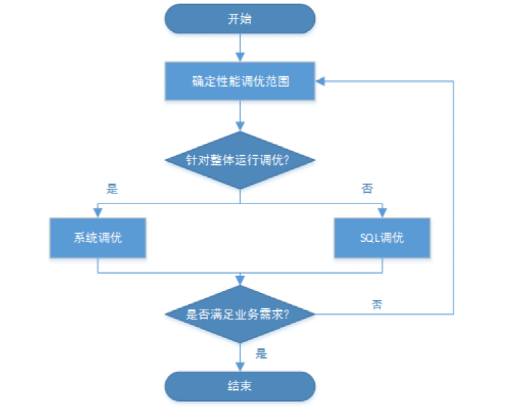
确定性能调优范围:
获取集群各节点的CPU、内存、I/O和网络资源使用情况,确认这些资源是否已被充分利用,是否存在瓶颈点。
系统调优指南:
进行操作系统级以及数据库系统级的调优,更充分地利用机器的CPU、内存、I/O和网络资源,避免资源冲突,提升整个系统查询的吞吐量。
SQL 调优指南:
审视业务所用SQL语句是否存在可优化空间,包括:
通过ANALYZE语句生成表统计信息:ANALYZE语句可收集与数据库中表内容相关的统计信息,统计结果存储在系统表PG_STATISTIC中。执行计划生成器会使用这些统计数据,以确定最有效的执行计划。
分析执行计划:EXPLAIN语句可显示SQL语句的执行计划,EXPLAIN PERFORMANCE语句可显示SQL语句中各算子的执行时间。
查找问题根因并进行调优:通过分析执行计划,找到可能存在的原因,进行针对性的调优,通常为调整数据库级SQL调优参数。
编写更优的SQL:介绍一些复杂查询中的中间临时数据缓存、结果集缓存、结果集合并等场景中的更优SQL语法。
SQL 引擎执行查询类 SQL 语句的流程
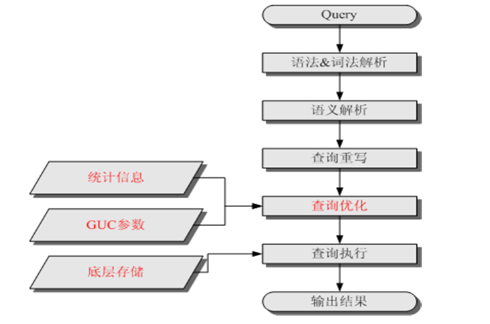
SQL执行计划
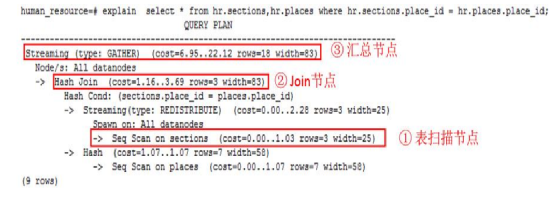
调优步骤
首先需要收集运行SQL语句中涉及到的所有表的统计信息。因为在数据库中,统计信息是规划器生成计划的源数据。如果没有收集统计信息或者统计信息比较旧的话,就会造成执行计划严重偏移,进而导致运行性能问题。
然后通过查看执行计划来查找运行慢的原因。如果SQL语句长时间运行不出结果,那么就可以EXPLAIN命令来查看执行计划,从而进行初步定位。如果SQL语句可以运行出来结果集,就可以推荐使用EXPLAIN ANALYZE语句或EXPLAIN PERFORMANCE语句来查看执行计划及实际运行情况,从而以便更加精准地来定位问题之所在。
审视和修改表定义。
针对EXPLAIN或EXPLAIN PERFORMANCE信息,定位SQL慢的具体原因以及改进措施。
通常情况下,有些SQL语句可以通过查询重写转换成等价的,或特定场景下等价的语句。重写后的语句比原语句更简单,且可以简化某些执行步骤达到提升性能的目的。
审视和修改表定义
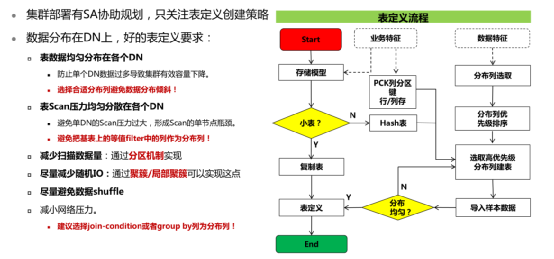
选择分布方式
复制表就是将表中的所有的数据在集群的每一个DN实例上保留一份。主要适用于那么记录数比较小的表。这种存储方式的优点是每个DN节点上都有此表的全量数据,在join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan segment;缺点是每个DN都保留了表的完整数据,这样就会造成数据的冗余,浪费磁盘空间。一般情况下只有记录数比较小的表才会定义为复制表。
哈希表将表中某一个或几个字段进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置。对于哈希分布表,在读、写数据时可以利用各个节点的IO资源,大大提升表的读、写速度,因为从多个节点获取资源比从单节点速度极大的提升。一般情况下大表定义为哈希表。
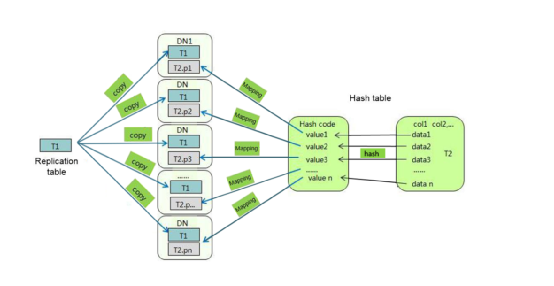
选择分布列
分布列的列值如果比较离散,那么数据就能够均匀分布到各个DN。比如考虑选择表的主键为分布列,如在客户基本信息表中选择客户号来做分布列。
选择查询中的连接条件为分布列,在进行JOIN时能够下推到多数DN中执行,减少DN之间的通信数据量,进而提升SQL运行速度。
使用分区表
分区表是把逻辑上的一张表根据某一种方案分成几张物理块进行存储。这张逻辑上的表称之为分区表,物理块称之为分区。
分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。分区表和普通表相比具有以下优点:
1.改善SQL查询性能:对分区对象的查询只需要在需要数据分区查找,进而可以提高数据检索的效率。
2.增强可用性:分区表的某个分区出现故障,表在其他分区的数据仍然可用。
3.方便维护:分区表的某个分区出现故障,需要修复数据,只修复这个分区。
选择数据类型
尽量去用一些执行效率比较高的数据类型,一般来说整型数据运算的效率比字符串、浮点数要高,底层数据存储的原因。
尽量使用短字段的数据类型长度较短的数据类型,不仅可以减小数据文件的大小,提升IO性能;同时也可以减小相关计算时的内存消耗,提升计算性能。比如对于整型数据,如果可以用smallint就尽量不用int,如果可以用int就尽量不用bigint。
使用一致的数据类型表关联列尽量使用相同的数据类型。如果表关联列数据类型不同,数据库必须动态地转化为相同的数据类型进行比较,这种转换会带来一定的性能开销。
SQL改写规则
根据数据库的SQL语句执行机制以及大量的实践,总结得出:通过相应的规则调整SQL语句,前提是必须在保证结果正确的基础上,并且能够提高SQL执行效率。如果遵守这些规则,常常能够大幅度提升SQL语句查询的效率。
使用union all 代替union ,因为union在合并两个集合时会对数据进行去重处理,,而union all是直接将两个结果集合并,不对数据去重。对数据的去重会消耗大量的时间。
关联列增加非空过滤条件, 如果关联列上的空值较多,那么可以加上is not null的过滤条件,用来实现数据的提前过滤,提高join效率,简单来说就是:先过滤后关联。
not in 转not exists not in语句需要使用嵌套循环来实现,而not exists则可以通过哈希关联来实现。在join列不存在null值的情况下,not exists和not in等价。如果在确保没有null值时,那么就可以将not in转换为not exists,通过生成哈希关联来提升SQL查询效率。
尝试将函数替换为case 语句。
避免对索引使用函数或表达式运算。因为对索引使用函数或表达式运算,会停止使用索引转而执行全表扫描,降低SQL执行效率。
尽量避免在where 子句中使用!= 或<> 操作符、null 值判断、or 连接、参数隐式转换。
参考文献:GaussDB 200 6.5.1 开发者指南 01

据说中国有句古语叫「金无足赤,人无完人」,但是,如果谁真的想打起灯笼来到市面上寻找完人,最终令他感到的可能不是一种失望,而是一种意外:完人可能就是那些终日为「善」而奔走,而又在不知不觉中实现了「美」的「真」实不虚的普通人。
追求完美是正常而有缺憾的人性。
--尼采

