





这是万物可述的第33篇原创文章
Teradata数据库介绍
什么是Teradata?
Teradada是用于世界上最大的商用数据库的关系数据库管理系统。
目前的技术允许数据库有数百Terabyte 字节的容量,这就使Teradata成为一个大型数据仓库应用的正确选择。而Teradata数据库系统也可以只有10G字节那么小。
由于并行性能和可扩展能力,Teradata可以使一个系统通过线性扩展从一个单一的节点开始扩展为多个节点的系统。
Teradata的特色:
关系数据库
海量处理能力
数亿行的数据
Teradata字节的数据
高性能的并行处理
多客户端的单一数据库服务器
网络和主机连接
工业标准访问语言(SQL)
通过模块化扩展的易管理性
不同级别硬件和软件的容错能力
数据完整性和可靠性
规划存储模型:
Teradata数据库支持行列混合存储。行、列存储模型各有优劣,建议根据实际情况选择。
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。
行、列存储优缺点:
存储模型 | 优点 | 缺点 |
行存 | 数据被保存在一起。INSERT/ UPDATE容易。 | 选择(Selection)时即使只涉及某几列, 所有数据也都会被读取。 |
列存 | 1) 查询时只有涉及到的列会被读取。 2) 投影(Projection)很高效。 3) 任何列都能作为索引。 | 1) 选择完成时,被选择的列要重新组装。 2) INSERT/UPDATE比较麻烦。 |
一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不多的情况下,适合列存储。
如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
存储类型 | 适用场景 |
行存 | 1) 点查询(返回记录少,基于索引的简单查询)。 2) 增、删、改操作较多的场景。 |
列存 | 1) 统计分析类查询 (关联、分组操作较多的场景)。 2) 即席查询(查询条件不确定,行存表扫描难以使用索引)。 |
行存表
默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常更新的场景。
CREATE TABLE customer_t1(state_ID CHAR(2),state_NAME VARCHAR2(40),area_ID NUMBER);
--删除表
DROP TABLE customer_t1;
列存表
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。
CREATE TABLE customer_t2(state_ID CHAR(2),state_NAME VARCHAR2(40),area_ID NUMBER)WITH (ORIENTATION = COLUMN);
--删除表
DROP TABLE customer_t2;
Teradata语法
数据类型
类型 | 名字 | 字节长度 | 说明 |
数值型 | DATE | 4 | YYMMDD,特殊的INTEGER类型 |
DECIMAL(n,m) | 1,2,4,8 | n: 1~18, m: 0~n,可缩写成DEC。 如256.78可表示为DEC(5,2) | |
NUMERIC(n,m) | 1,2,4,8 | 同上 | |
BYTEINT | 1 | 128~+127 | |
SMALLINT | 2 | 32768~+32767 | |
INTEGER | 4 | 可缩写成INT | |
REAL | 8 |
| |
FLOAT | 8 | 同上 | |
DOUBLE PRECISION | 8 | 同上 | |
字符型 | CHAR(n) | n | n: 1~64000,也可写成CHARACTER |
VARCHAR(n) | n+2 | n: 1~64000,变长,最前面两字节表示字符串 长度。也可写成CHAR VARYING(n) | |
LONG VARCHAR | 32002 | 相当于VARCHAR(64000) | |
二进制 | BYTE(n) | n | n: 1~64000,无符号二进制整数 |
VARBYTE(n) | n+2 | n: 1~64000,变长,最前面两字节表示长度 | |
其它 | GRAPHIC(n) | n | n: 1~32000,这三种数据类型可支持双字节日 本字符和汉字 |
VARGRAPHIC | n+2 | n: 1~32000,变长,最前面两字节表示长度 | |
LONG VARGRAPHIC | 相当于VARGRAPHIC(32000) |
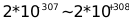
算术运算符
Teradata提供以下ANSI标准规定的算术运算符:
* 乘
/ 除
+ 加
- 减
+ 正号
- 负号
除此以外,Teradata还扩展了下面两个算术运算符:
** (求幂)
MOD(取模)
**表示方法:
例:
4**3 = 4 * 4 * 4 = 64
MOD是取模运算符,表示除运算的余数。
例:
60 MOD 7 = 4
即:60除以7等于8,余数是4。
Teradata 算术函数
在ANSI标准中没有算术函数,Teradata作了扩充,它支持的算术函数如表所示。
函数 | 意义 |
ABS (arg) | 求绝对值 |
EXP (arg) | 增加幂 |
LOG (arg) | 10的对数 |
LN (arg) | 自然对数 |
SQRT (arg) | 平方根 |
注:arg代表任意常数或变量。
例:
SQRT(16) = 4
创建表
CREATE TABLE语句创建新表,定义新表的列、索引和其他属性。新表创建后,表结构定义存放在Teradata的数据字典中。CREATE TABLE语句的语法如下:
CREATE
其中:
Create Table Options 表选项 | 定义表的物理属性 Fallback Journaling Freespace Datablocksize |
Column Definitions字段定义 | 定义表的各个字段 |
Table-level Constraints 表级约束 | 定义约束 Primary key Unique CHECK条件 Foreign key |
Index Definitions索引定义 | 定义表索引 |
创建表的可选项
Teradata DDL允许在创建表时指定表的物理属性,包括:
1)是否允许重复记录
❍ SET 不允许记录重复
CREATE SET TABLE table1 ...
❍ MULTISET 允许记录重复
CREATE MULTISET TABLE table1 ...
2)数据保护
数据保护要结合FALLBACK和JOURNAL (流水或日志)。
FALLBACK是Teradata的一种数据保护机制,数据表的每一条记录都同时存放两份,而且位于不同的AMP所控制的存储单元中;当数据发生问题或者AMP失败时,可以利用存放在其他AMP上的数据保证对数据表的访问。
- FALLBACK 使用FALLBACK保护机制
- NO FALLBACK 不使用FALLBACK保护机制
日志有BEFORE和AFTER两种,分别保存了一条记录变化前后的状态。当系统出错时,可以利用日志进行恢复。
存储空间选项
DATABLOCKSIZE用来指定数据块大小,最小的数据块为6144字节,最大的数据块是32256字节。
FREESPACE用来定义在每个磁盘柱面上保留的空间(0-75%)。
例:
CREATE MULTISET TABLE table_1, FALLBACK, NO JOURNAL, FREESPACE = 10 PERCENT, DATABLOCKSIZE = 16384 BYTES(field1 INTEGER);
Teradata新增命令
在Teradata中,主要增加了以下命令:
命令 | 功能 |
HELP | 帮助用户了解数据库中各种对象的结构 |
SHOW | 帮助用户了解某种对象的定义,即返回其DDL语句 |
EXPLAIN | 返回一个SQL语句经优化处理后的执行步骤,注意并未真正执行 |
FALLBACK | 对数据加以保护的一种方式,是冗余的备份 |
RENAME | 对表重命名 |
NULLIFZERO | 对数据作累计处理时,忽略零值 |
ZEROIFNULL | 对数据作累计处理时,将空值作零处理 |
WITH...BY | 对详细数据记录作分类统计(Sub-Total)时有用 |
MODIFY USER /DATABASE | 对用户/数据库对象作动态修改而无需数据库重组 |
HELP命令
HELP命令可以用来显示数据库中各个目标的相关信息、当前对话连接的特性,并能提供SQL语法的联机帮助。
数据库中的对象包括表、视图、宏、触发器和存储过程,HELP命令可以提供有关数据库和用户以及这些对象的信息。
HELP命令 | 参数 |
HELP DATABASE | databasename; |
HELP USER | username; |
HELP TABLE | tablename ; |
HELP VIEW | viewname; |
HELP MACRO | macroname; |
HELP COLUMN | table or viewname.*; |
HELP COLUMN | table or viewname.colname . . ., colname; |
HELP INDEX | tablename; |
HELP STATISTICS | tablename; |
HELP CONSTRAINT | table or viewname.constraintname; |
HELP JOIN INDEX | join_indexname; |
HELP TRIGGER | triggername; |
HELP PROCEDURE | procedurename; |
HELP PROCEDURE | procedurename ATTRIBUTES; |
例:
HELP DATABASE/USER 的使用
HELP DATABASE可以显示一个指定数据库所包含的所有对象,如表、视图、宏等。如要显示数据库customer_service中的对象,可以使用下面的命令:
HELP DATABASE customer_service;
系统返回信息如下:
Table/View/Macro name | Kind | Comment |
contact | T | ? |
customer | T | ? |
department | T | ? |
employee | T | ? |
employee_phone | T | ? |
job | T | ? |
location | T | ? |
location_employee | T | ? |
这里返回了三列信息。第一列是表、视图或宏的名字,第二列则是类型,T表示表(Table),V表示视图(View),M则表示宏(Macro)。第三列表示注释,?表示没有注释。
同理,如果要显示某个用户中所包含对象的信息,则可以使用HELP USER命令。如下面的命令将显示DBC用户下所包含的所有对象:
HELP USER DBC;
SHOW命令
查看数据库对象是用什么样的DDL命令创建。
针对数据库对象的HELP命令:
SHOW命令 | 参数 |
SHOW TABLE | Tablename ; |
SHOW VIEW | Viewname; |
SHOW MACRO | Macroname; |
SHOW INDEX | Tablename; |
SHOW JOIN INDEX | join_indexname; |
SHOW TRIGGER | Triggername; |
SHOW PROCEDURE | Procedurename; |
BTEQ还有一个SHOW命令,SHOW CONTROL,这是一个附加的SQL SHOW命令。它能够格式化显示当前BTEQ会话的信息。
SHOW TABLE/VIEW/MACRO 的使用
如果要显示EMPLOYEE表的结构,可使用下面的命令:
SHOW TABLE customer_service.employee;
系统返回信息如下:
CREATE SET TABLE customer_service.employee ,FALLBACK ,NO BEFORE JOURNAL,NO AFTER JOURNAL(employee_number INTEGER,manager_employee_number INTEGER,department_number INTEGER,job_code INTEGER,last_name CHAR(20) NOT CASESPECIFIC NOT NULL,first_name VARCHAR(30) NOT CASESPECIFIC NOT NULL,hire_date DATE NOT NULL,birthdate DATE NOT NULL,salary_amount DECIMAL(10,2) NOT NULL)UNIQUE PRIMARY INDEX ( employee_number );
由此可知,SHOW TABLE的命令返回了指定表的DDL语句。
EXPLAIN 命令
利用EXPLAIN命令,可以了解Teradata执行一个SQL交易请求的详细过程和计划,这对于更进一步地理解Teradata的查询处理机制有很大的帮助。另一方面,对于复杂SQL交易的调试来说,这也是不可缺少的一个工具。
利用EXPLAIN解释一个SQL交易的方法很简单,就是在原来SQL语句的前面加上EXPLAIN即可,其它完全不变。系统返回的信息包括:
1) 提供完整的由分解器对 SQL语句进行分解和优化后的 AMP执行步。
2) 这种执行计划是基于当前的数据分布情况而作出的,因此当数据分布发生变化时,同样 SQL语句产生的执行步可能不相同。
3) EXPLAIN 还会产生执行每个 SQL步骤大致所需要的时间,但需要注意的是,这个时间由于是根据早期版本的 CPU 处理时间来计算,因此往往和实际情况相差很多,仅能作参考而已。
下面让我们来举个例子进行说明。
假设一个如下的SQL语句:
SELECT * FROM department;
该语句非常简单,从DEPARTMENT表中将所有的记录选择并显示出来。如果要看一下它的执行过程,而不需要实际的结果,可以在前面加上EXPLAIN,如下:
EXPLAIN SELECT * FROM department;
系统返回信息如下:
Explanation1) First, we lock CUSTOMER_SERVICE.department for read.2) Next, we do an all-AMPs RETRIEVE step from CUSTOMER_SERVICE.department by way of an all-rows scan with no residual conditions into Spool1, which is built locally on the AMPs. The size of Spool 1 is estimated to be 4 rows. Theestimated time for this step is 0.08 seconds.3) Finally, we send out an END TRANSACTION step to all AMPs involved inprocessing the request.-> The contents of Spool 1 are sent back to the user as the result of statement 1.The total estimated time 0.08 seconds.
从系统返回的信息可以看到,该SQL请求是一个牵涉到所有AMP的操作(All-AMP Operation)。对于一个复杂的SQL交易请求,如果执行出错(如空间溢出等)或返回结果与所预料的相差很远,则有可能是SQL语句本身存在问题。这时可以利用EXPLAIN机制来了解一下Teradata的处理过程,从而发现和解决问题。
宏
宏(Macro)是Teradata扩展的性能,ANSI标准不支持宏。
宏(Macro)的基本特征是:
1) 可以包含一条或多条 SQL语句
2) 可以包含多个 BTEQ语句
3) 可以包含注解
4) 存储在数据字典中
Teradata中用于宏的命令:
CREATE MACRO macroname AS ( . . . ); | 定义宏 |
EXECUTE macroname; | 执行宏语句 |
SHOW MACRO macroname; | 显示宏定义 |
REPLACE MACRO macroname AS (. . . ); | 改变宏定义 |
DROP MACRO macroname; | 从字典中删除宏定义 |
EXPLAIN EXEC macroname; | 显示宏执行的解释 |
宏的定义
宏是用CREATE MACRO命令来定义的,如下例所示:
CREATE MACRO birthday_list AS
(SELECT last_name
,first_name
,birthdate
FROM employee
WHERE department_number = 201
ORDER BY birthdate; );
宏的执行
宏的执行很简单,使用EXEC命令就可以。例如,为了执行上面定义的宏,可以使用下面的语句:
EXEC birthday_list;
宏的删除
使用DROP命令可以删除宏,如下所示:
DROP MACRO birthday_list;
宏的显示和改变
使用SHOW命令可以显示一个宏的定义,如下所示:
SHOW MACRO birthday_list;
使用REPLACE MACRO命令可以改变宏的定义,如:
REPLACE MACRO birthday_list AS
(SELECT last_name
,first_name
,birthdate
FROM employee
WHERE department_number = 201
ORDER BY birthdate, last_name; ) ;
参数宏
所谓参数宏,是指在宏中包含可以替代值的变量。下面是一个简单的参数宏定义:
CREATE MACRO dept_list(dept INTEGER)
AS
( SELECT last_name
FROM employee
WHERE department_number = :detpt );
该宏的功能是在雇员表中选取某个部门全部雇员的姓,宏dept_list定义了一个参数dept,类型是整数。作为部门代码参数。
运行宏dept_list的语句为:
EXEC dept_list(301);
其结果是返回部门编号为301的所有雇员的姓。
如同这个简单的例子,参数在宏中的引用是通过冒号(:) +参数名而实现的。
FORMAT 短语
FORMAT用于数据在输出时的格式化处理,但它并不影响数据的内部存储格式。它主要有如下面例子所示的两种表示方式。
例:
SELECT salary_amount (FORMAT ''$$$,$$9.99'');
例:
SELECT CAST (salary_amount AS FORMAT ''$$$,$$9.99'');
注意,在第二个例子中CAST的使用方法是Teradata的扩展,因为这里CAST处理的是一个数据的属性,而在ANSI标准中,CAST只能用于处理一种数据类型。
FORMAT短语中可以使用的格式化字符主要为:
1) $ 美元标识符
2) 9 数字位
3) Z 将数字中的前缀零去除
4) , 在指定位置插入逗号
5) . 指定小数点位置
6) - 在指定位置插入连字号
7) 在指定位置插入斜线
8) % 在指定位置插入百分号
9) X 字符数据,每个 X代表一个字符
10) G 图形数据.一个 G代表一个逻辑字符(双字节)
11) B 在指定位置插入空格
对日期的格式化处理
在Teradata中,日期数据的缺省输出格式是:YY/MM/DD,这和ANSI标准是一样的。而ANSI标准建议的日期显示格式是:YYYY-MM-DD。
其它一些常用的日期显示格式列举如下,其中的B表示空格。
YYYY/MM/DD'
YYYY-MM-DD'
YYYY.DDD'
DBMMMBYYYY'
MMBDD,BYYYY'
YYYYBMMMBDD'
YY/MM/DD'
D-MM-YY'
YBDDD
MM'
注意:由于2000年问题,ANSI推荐使用日期格式为YYYY-MM-DD,或者其它采用四位年的格式。
下面是一些对日期进行格式化的例子。
句法 结果
FORMAT 'YYYY/MM/DD' 1996/03/27FORMAT 'DDbMMMbYYYY' 27 Mar 1996FORMAT 'mmmBdd,Byyyy' Mar 27, 1996FORMAT 'DD.MM.YYYY' 27.03.1996FORMAT 'MM/DD/YY' 03/27/96FORMAT 'MMM.DD.YY' Mar.27.96FORMAT 'yy -- mm -- dd' 96 -- 03 -- 27FORMAT 'DDDYY' 08696
下面再看一下在SELECT语句中对日期进行格式化的例子。
SELECT last_name,first_name,hire_date (FORMAT 'mmmBdd,Byyyy')FROM employeeORDER BY last_name;last_name first_name hire_dateJohnson Darlene Oct 15, 1976Kanieski Carol Feb 01, 1977Ryan Loretta Oct 15, 1976
总计与小计
利用WITH BY 进行数据小计
WITH BY的主要特点包括:
1) 它为明细数据表创建分类小计。
2) 跟 GROUP BY不同的是,WITH BY没有剔除明细记录,而是在明细记录后面按照分类增加小计行。
3) 可以允许多于一个字段进行小计,即小计当中可以嵌套小计。
4) 输出结果将根据 BY 后面的所有字段自动进行排序。
5) 它是 Teradata的一个扩展特性。
请看下面的一些例子。为了说明方便,在下面的诸例子中均利用了雇员表。
1.利用WITH BY产生基本报表。
例如在Employee表中,欲显示所有雇员姓和工资并要求按部门进行小计。其语句如下:
SELECT last_name AS NAME,salary_amount AS SALARY,department_number AS DEPTFROM employeeWITH SUM (salary) BY DEPT;
返回的报表如下所示:
NAME SALARY DEPTStein 29450.00 301Kanieski 29250.00 301--------------Sum(SALARY)58700.00Johnson 36300.00 401Trader 37850.00 401--------------Sum(SALARY)74150.00Villegas 49700.00 403Ryan 31200.00 403--------------Sum(SALARY) 80900.00
利用WITH语句产生最后的总计
如果在WITH语句中不带BY则只产生总计。如下面的例子:
列出部门301所有的雇员编号和其工资数,并对该部门的工资作统计,语句如下:
SELECT employee_number,salary_amountFROM employeeWHERE department_number = 301WITH SUM(salary_amount) (TITLE 'GRAND TOTAL')ORDER BY employee_number;
返回结果如下:
employee_number salary_amount1006 29450.001008 29250.001019 57700.00-------------GRAND TOTAL 116400.00
SUBSTRING 函数
SUBSTRING函数用来从字符串中析取一个子字符串,其格式为:
SUBSTRING (<字符串表达式> FROM <开始位置> [ FOR <长度> ])
如:
SELECT SUBSTRING('catalog' FROM 5 FOR 3);
结果为log。
字符串合并
字符串合并的符号是"||",它把两个字符串串联成一个字符串。其基本格式为:
<字符串1> || <字符串2>
NULLIF 表达式
NULLIF实际上用来作为CASE语句在某种情况下的缩写,其格式为:
NULLIF (
规则是:
a. 如果表达式 1等于表达式 2,则返回 NULL
b. 如果表达式 1不等于表达式 2,则返回表达式 1的值
例:
SELECT call_number,labor_hours (TITLE 'ACTUAL HOURS'),NULLIF (labor_hours, 0) (TITLE 'NULLIF ZERO HOURS')FROM call_employeeORDER BY labor_hours;
NULLIF等价于:
CASE
WHEN
ELSE
END
OLAP 函数
OLAP即联机分析处理(On-Line Analytical Process)。Teradata数据库本身提供了一些OLAP函数,包括:
RANK - 排队(Rankings)
QUANTILE - 分位数(Quantiles)
CSUM - 累计(Cumulation)
MAVG - 移动平均(Moving Averages)
MSUM - 移动合计(Moving Sums)
MDIFF - 移动差分(Moving Differences)
MLINREG - 移动线性回归(Moving Linear Regression)
OLAP函数与聚合函数有类似的地方:
1) 对数据进行分组操作 (类似于 GROUP BY 子句)
2) 能够使用 QUALIFY 子句过滤组 (类似于 HAVING 子句)
OLAP函数又与 聚合函数不同,因为:
1) 返回满足条件的每行的数据值,而不是组的值
2) 不能在子查询内使用
下面列举一些常用的OLAP函数。
累计函数
累计函数(CSUM) 计算一列的连续的累计的值。语法为:
CSUM(colname, sort list)
问题
创建item 10从1998年1月和2月的连续的日汇总报表。
解答
SELECT salesdate, sales, csum(sales, salesdate)
FROM daily_sales
WHERE salesdate BETWEEN 980101 AND 980301
AND itemid = 10;
结果
salesdate sales Csum98/01/01 150.00 150.0098/01/02 200.00 350.0098/01/03 250.00 600.0098/01/05 350.00 950.0098/01/10 550.00 1500.0098/01/21 150.00 1650.0098/01/25 200.00 1850.0098/01/31 100.00 1950.0098/02/01 150.00 2100.0098/02/03 250.00 2350.00......
如果想每月重新累计,该怎么办?
累计汇总可以使用GROUP BY子句在特殊的点复位,即重新开始累计。注意,OLAP函数和标准聚合函数(SUM, COUNT,AVG, MIN, MAX) 是不能在同一查询中兼容的。因此,对这类查询使用GROUP BY,将会起分隔的作用。
问题:
创建item 10从1998年1月和2月的连续的日汇总报表,并且每月重新开始累计。
解答:
SELECT salesdate, sales, csum(sales, salesdate)FROM daily_sales ds, sys_calendar.calendar scWHERE ds.salesdate = sc.calendar_dateAND sc.year_of_calendar = 1998AND sc.month_of_year in (1,2)AND ds.itemid = 10GROUP BY sc.month_of_year;
结果:
salesdate sales Csum98/01/01 150.00 150.0098/01/02 200.00 350.0098/01/03 250.00 600.0098/01/05 350.00 950.0098/01/10 550.00 1500.0098/01/21 150.00 1650.0098/01/25 200.00 1850.0098/01/31 100.00 1950.0098/02/01 150.00 150.00 重新累计98/02/03 250.00 400.0098/02/06 350.00 750.0098/02/17 550.00 1300.0098/02/20 450.00 1750.0098/02/27 350.00 2100.00
排队函数
排队函数对一列进行排队,可以按照升序或者降序排队。缺省,输出结果按照降序排队,对应的排队名次是升序。换句话说,如果一个销售代表在某季度的销售额最高,其排名为1,这是一个最小的值。
排队函数(RANK)的语法是:
RANK(colname)
显示商店1001的产品销售额排队。
解答:
SELECT storeid, prodid, sales, RANK(sales)FROM salestblWHERE storeid = 1001;
结果:
storeid prodid sales Rank1001 F 150000.00 11001 A 100000.00 21001 C 60000.00 31001 D 35000.00 4
使用排队函数的规则包括:
1) WHERE 子句限定参与排队的记录。
2) 应用排队函数时,缺省最大的数名次最低。
3) 缺省顺序是按排队列的降序。
带限定的排队
QUALIFY子句限制排队输出的最终结果。QUALIFY子句与HAVING子句类似,使输出限制在一定范围内。
问题
按商店得到销售前3名的产品。
解答
SELECT storeid, prodid, sales, rank(sales)FROM salestblGROUP BY storeidQUALIFY rank(sales) <= 3;
结果
storeid prodid sales Rank1001 A 100000.00 11001 C 60000.00 21001 D 35000.00 31002 A 40000.00 11002 C 35000.00 21002 D 25000.00 31003 B 65000.00 11003 D 50000.00 21003 A 30000.00 3
上面的例子中,GROUP BY子句不是做聚合,它实际上是改变查询的范围,也引起排序。
使用排队函数的规则包括:
1) 对某列的每行都应用了排队
2) GROUP BY 子句控制范围,如商店内的销售额排队(注意- 查询中并没有聚合)
3) QUALIFY 子句限制显示,如仅显示销售额的前 3名
4) 缺省的顺序是按照排队的列的降序
5) 因为 GROUP BY 子句,排序将限制在组内,如商店内。
临时表
Teradata中有3类临时表:
1)全局临时表(Global Temporay Table)
2)可变临时表(Volatile Temporay Table)
3)导出表(Derived Table)
为什么使用临时表?
临时表是一种辅助工具,能够提高SQL操作的性能。特别是针对下列情况的SQL操作:
1)不能使用规范化的表;
2)要求多条 SQL语句完成。
临时表对于非规范化非常有用,如:
1)汇总表
2)重复分组
临时表对于频繁产生的中间结果或作为后续工作基础的中间结果也非常有用。
可变临时表(Volatile Temporary Tables)
可变临时表在Teradata V2R3中实现,与导出表相比,它有许多优点。其特点包括:
1)对会话(session)是本地的 - 存在于整个会话期间,而不是单个查询。
2)使用 CREATE VOLATILE TABLE语法创建。
3)会话(session)结束时,自动丢掉。
4)不使用数据字典。
全局临时表(Global Temporary Tables)
全局临时表在Teradata V2R3中实现,与可变临时表的主要区别是,全局临时表在数据字典中有定义,可以被多个用户共享。每个用户会话能够物化自己本地的表的实例。其特点包括:
1)对会话(session)是本地的,但是每个用户会话可以有自己的实例。
2)使用 CREATE GLOBAL TEMPORARY TABLE 语法。
3)会话(session)结束时,物化的表的实例被丢掉。
4)在数据字典中创建并保持表的定义。
全局临时表与可变临时表有不同的地方:
1)基础定义是永久的,保存在数据字典中。
2)要物化表,要有相应 SQL的权限。
3)空间要占用用户的“临时空间(temporary space)”。
4)每个会话最多可以物化 32个全局临时表。
5)系统重启动后,还存在。
全局临时表与可变临时表有相似的地方:
1)对会话而言,每个实例是本地的。
2)会话结束后,物化的表被自动删除。(但基础定义仍然存储在数据字典中)
3)都有 LOG 和 ON COMMIT PRESERVE/DELETE 选项。
4)物化表中内容与其他会话不共享。
5)在会话开始时,表被清空。
索引
索引是物理模型中的一个概念,利用索引,可以直接存取表中的某一条记录而不需要搜索整个表。因此,索引提供了一条更快速访问数据记录的途径。
当在数据库中针对某个表创建一个索引时,系统将根据此索引建立一个相应的子表。相对原来的表(主表)而言,子表要小得多。它将存储索引的值以及一个与此索引对应的数据记录在主表中的存储位置,这好比一个指向数据记录物理位置的指针。显然,建立索引需要占用额外的存储空间;另外,索引子表是由系统自动维护的,当主表的数据记录发生变化时,系统要自动更新索引子表的相应记录,从而占用系统资源。这就是使用索引的代价。
索引则存在于物理模型中。Teradata中又把索引分为主索引和次索引,主索引不一定就对应主键。
选择主索引的基本原则是:尽量选择那些访问频率高的属性作为主索引。
主索引与主键的区别可以总结下表
主键 | 主索引 |
逻辑模型中的一个概念 | 物理模型中用于数据分配与存取的一种物 理机制 |
没有属性数目的限制 | 最多由16个属性组成 |
在逻辑模型中定义 | 在创建表时定义 |
取值必须唯一 | 可以唯一也可以不唯一 |
用来区分数据记录 | 用来进行数据分配 |
其值不发生改变 | 其值可以发生变化 |
不可以取空值 | 可以取空值 |
Teradata的每个表都必须有主索引。除主索引是必须的外,也可以建立次索引来提高表的存取性能和实现约束。相关的术语如下:
PK | Primary Key 主键 |
PI | Primary Index 主索引 |
UPI | Unique Primary Index唯一性主索引 |
NUPI | Non Unique Primary Index 非唯一性主索引 |
USI | Unique Secondary Index 唯一性次索引 |
索引可以在CREATE TABLE时就加以定义,同时还可以定义主键。如果创建表时不定义主索引,Teradata就按照下面的规则缺省来建立主索引,因为没有主索
引的话,Teradata就无法进行数据的分配。
1.没有在 CREATE TABLE时指定 PI
IF 定义了PK,THEN PK = UPI
ELSE IF 存在定义为UNIQUE的字段,
THEN 第一个NIQUE的字段为UPI
ELSE 表中定义的第一个字段作为NUPI
2. CREATE TABLE 时指定了 PI
IF 定义了PK,THEN PK作为USI
AND为每一个定义为UNIQUE的字段建立一个USI
创建表时就应定义主索引,同时也可以定义次索引。事实上,次索引也可以使用单独的CREATE INDEX语句来定义。换言之,主索引只能在CREATE TABLE时定义,而次索引既可以在创建表时定义,也可以使用CREATE INDEX来定义。
例:为雇员表创建下面两个次索引。
为雇员名字建立命名的唯一次索引USI
CREATE UNIQUE INDEX fullname (last_name, first_name)
ON emp_data;
为工作代码建立非唯一性次索引NUSI,不命名NUSI
CREATE INDEX (job_code) ON emp_data;
从这个例子可以看到,次索引可以命名,如第一个USI的名字为
FULLNAME;也可以不命名,如第二个NUSI就没有取名。
定义好索引或次索引后,可以利用HELP INDEX <表名>来显示指定表的所有
索引定义,如果索引是未命名的,索引名称显示为NULL。
优化思路及方法
□ 选择目标
√ 执行时间长的ETL作业
√ 执行时间长的SQL操作
√ I/O倾斜率高的SQL
√ Spool使用多的SQL
□ 收集信息
√ 目标SQL
√ 相关表的定义(特别是PI,PPI)
√ 相关表的大小
□ Explain分析-1 EXPLAIN常用名称
数据扫描:
√ All-AMPs retrieve step --全表扫描
√ by way of all-row scan --全表扫描
√ by way of the primary index --单PI查询
√ Single-AMP retrieve step --单个AMP检索
√ all-Partions retrieve --全分区检索
数据JOIN前数据处理策略
√ redistribution --重分布
√ duplicated on all AMPs --全表复制
数据关联方式
√ using a product join
√ using a single partion hash join
√ using a merge join
□ Explain分析-2 执行计划判断依据
√ 大表不应该发生all-AMPs Duplicated --全表复制
√ 大表应尽量避免all-AMPs Redistributed ----全表重分布
√ 小表应尽量all-AMPs Duplicated或all-AMPs Redistributed
√ 在多表进行关联的时候,应避免大表与大表先发生关联。
√ 分区表首先进行分区筛选,尽可能避免all-Partitions retrieve(全分区索引)
□ 过程优化
√ PDM模型
●调整PI
●使用PPI
●其他设计(multiset)
√ SQL技术调整
●增加统计信息,改善执行计划
●减少不必要的数据排重
●复用和减少临时表
●大表预处理,减少结果集
●代码共用
√ SQL逻辑调整
●减少大表的访问,直接引用其他结果
●简化业务规则,避免和大表关联
优化总结:
√ 保持良好的SQL书写习惯,格式对齐,关键字突出
√ 越简单越美丽,不要追求高大上的复杂SQL
√ 尽可能减少I/O和SPOOL
●数据的全表扫描使用PI或PPI
●大表的数据分布(使用PI)
●大表的数据复制(两张表数据量级相差较大时,小表进行数据复制)
●不必要的比较和不必要的中间结果(先筛选数据后进行比较)
√ 减少导出目标列的数量(按需选择)
√ 优化不能更改业务逻辑
作者:谢光琨
编辑:徐菲

据说中国有句古语叫「金无足赤,人无完人」,但是,如果谁真的想打起灯笼来到市面上寻找完人,最终令他感到的可能不是一种失望,而是一种意外:完人可能就是那些终日为「善」而奔走,而又在不知不觉中实现了「美」的「真」实不虚的普通人。
追求完美是正常而有缺憾的人性。
--尼采

