





这是万物可述的第21篇原创文章
HBASE定义
HBase:高可靠性、高性能、面向列、可伸缩的分布式存储系统
Hbase是构建在Hadoop HDFS(Hadoop Distributed File System)上的分布式列存储系统
为Spark和Hadoop MapReduce提供海量数据实时处理能力。
利用Zookeeper做调度的能够存储半结构化与非结构化数据的数据库。
HBase使用场景有如下几个特点:
处理海量数据(TB或PB级别以上)
具有高吞吐量
在海量数据中实现高效的随机读取
具有很好的伸缩能力
能够同时处理结构化和非结构化的数据
HBase中的表具有如下特点:
容量大:
HBase对于单表存储百亿或更多的数据都没有性能问题。
面向列:
面向列(族)的存储和权限控制,列(族)独立检索
稀疏:
对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
数据多版本:每个单元中的数据可以有多个版本
HBase与传统数据库比较
分布式存储,面向列。
动态扩展列。
普通商用硬件支持,扩容成本低。
不需要完全拥有传统关系型数据库所具备的ACID特性。
HBASE架构
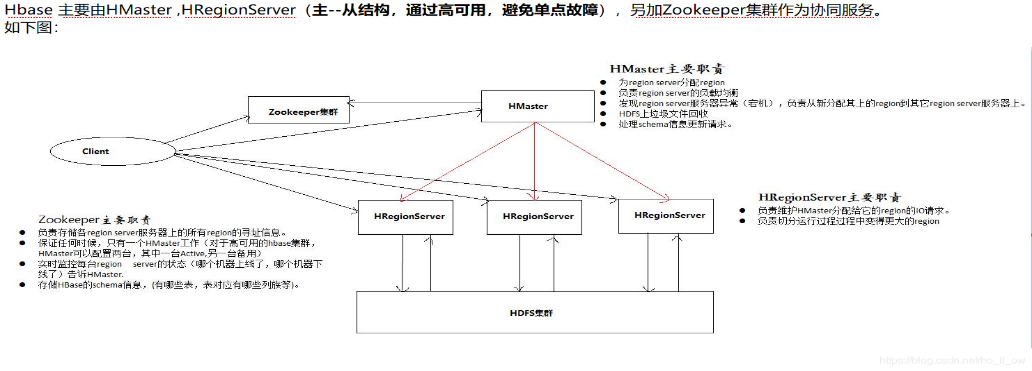
架构说明:
① Master,在HA模式下,包含主用Master和备用Master。
主用Master:负责HBase中RegionServer的管理。
② 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
③ Client:Client使用HBase的RPC机制与Master、RegionServer进行通信。
④ ZooKeeper集群:ZooKeeper为HBase集群中各进程提供分布式协作服务。
⑤ HDFS集群:HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
数据存储核心组件--HRegion
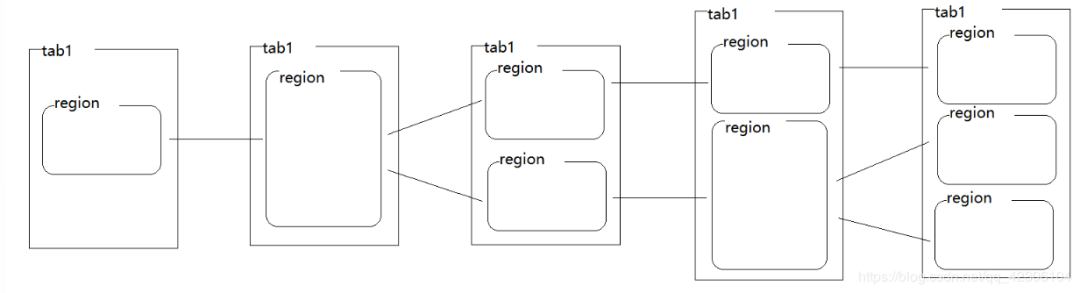
组件说明:HBase将表从逻辑上横向切分成若干个HRegion,。起初,一个表中只包含一个HRegion,所有的数据都放在一个HRegion中。随着数据量的积累,HRegion中的数据会越来越多,HRegion就会产生分裂。以此类推数据不断增大就会不断的分裂产生更多的HRegion。
HRegion的内部结构
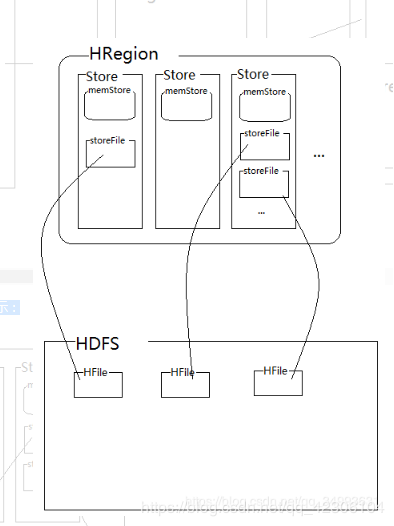
1.Store:一个Region由一个或多个Store组成,每个Store对应一个Column Family。
2.MemStore:一个Store包含一个MemStore,MemStore缓存客户端向Region插入的数据。
3.StoreFile:MemStore的数据flush到HDFS后成为StoreFile,随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置的最大值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。
4. HFile :HFile定义了StoreFile在文件系统中的存储格式。
Hbase写数据流程
①.首先通过表名与行键找到我们需要操作的HRegion(由于是横向切割所以使用的是行键来确定HRegion)
②.然后根据列族找到对应的Store。对该Store中的memStore中写数据。
③.HFile会越存越大然后产生分裂成不同的小文件。memStore的会不断的更新数据,将几个HFile合并起来,然后将最新版本的数据覆盖旧版本的数据。最后再将这个文件分裂开来。
HBase读数据流程
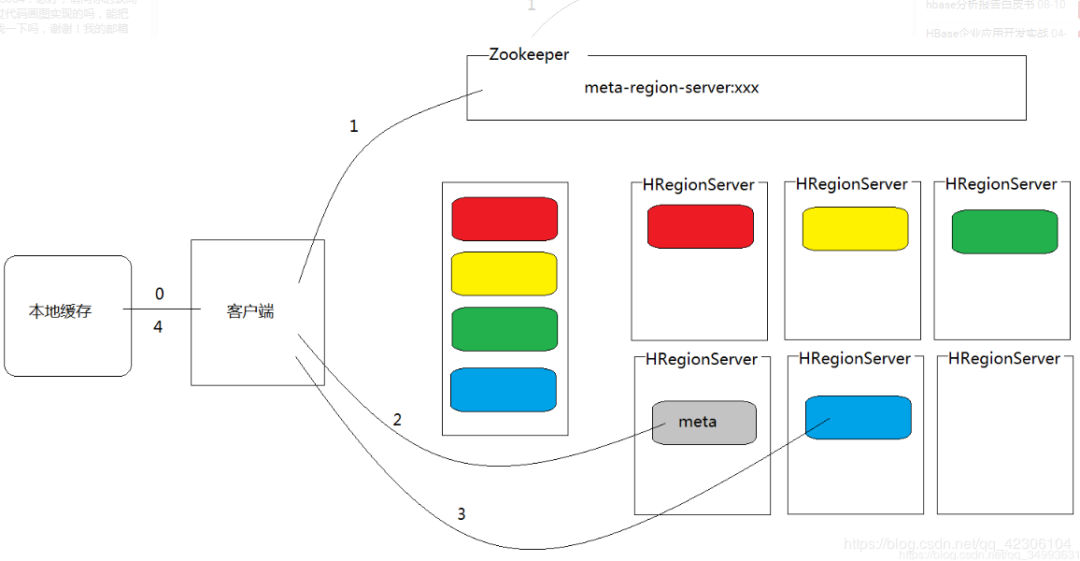
①.当客户端联系HBase标识要读取某一张表时,根据表和行键确定出HRegion,找到存有该HRegion的HRegionServer,
②.根据要查找的列族,确定出要查询的Store,首先在memStore中寻找要查询的数据,如果能查到,直接返回查询到的数据,查询结束。
③.如果在memStore中找不到要查询的数据,要查询该store对应的所有的storeFile,
HBASE数据模型
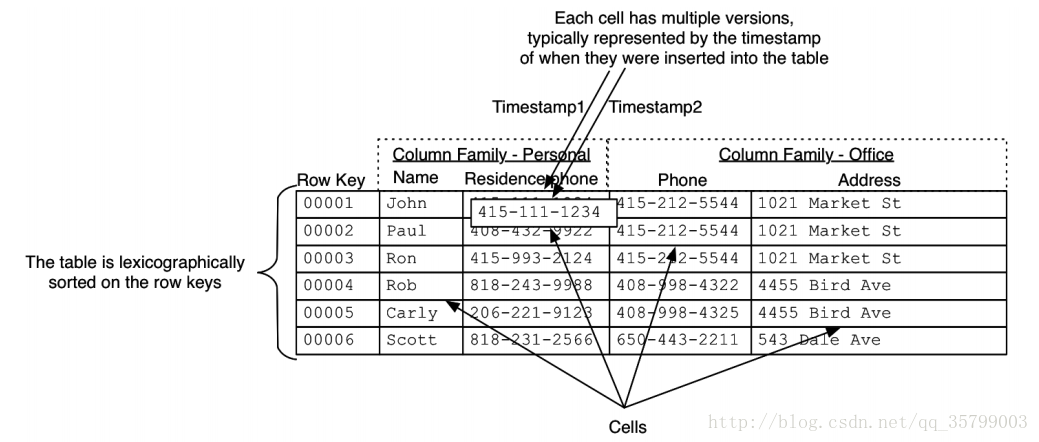
1.行(Row):由一个row key和多组数据组成;
2. 列簇(Column Family):列簇在物理存储上包含了一系列Column的集合;数据按ColumnFamily分开存储,HBase所谓的列式存储就是根据ColumnFamily分开存储(每一个ColumnFamily对应一个Store)。
3. 列修饰符(Column Qualifier):每个列簇可以有一个或多个列修饰符,用来索引列簇中的数据。
4. 列(Column):列是由列簇和列修饰符(Column Qualifier)组成,并以冒号隔开,表示一个具体的列。
5. 单元格(Cell):Cell由行键,列族,列修饰符,时间戳唯一确定,时间戳表示版本。
6. 时间戳(Timestamp):时间戳在每次写入数据时候指定。
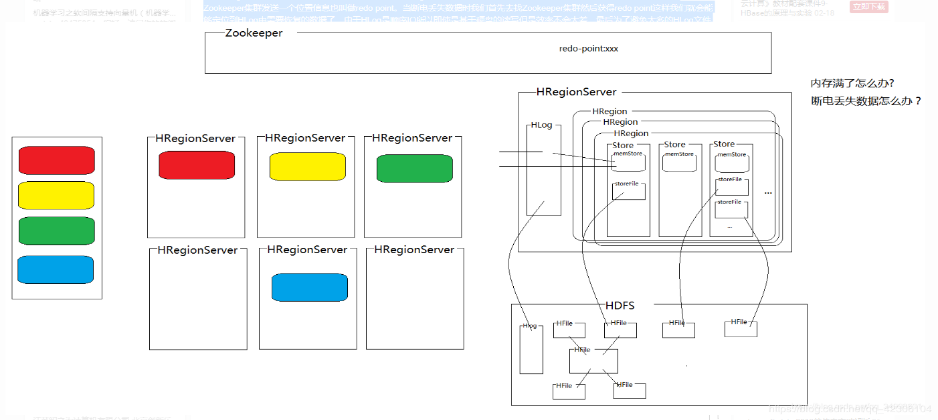
Hbase高可用原理
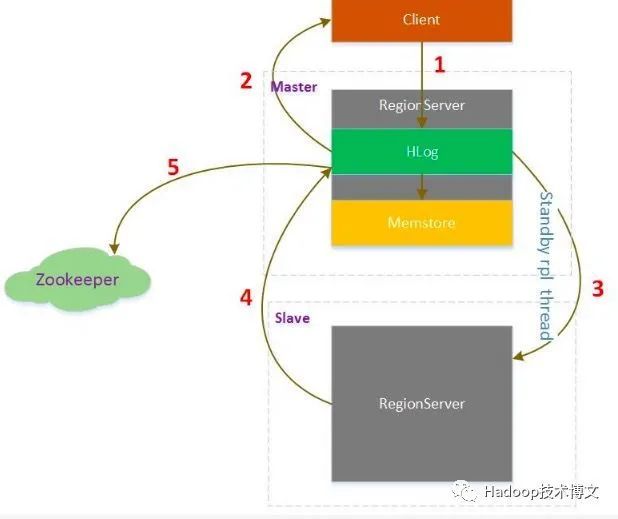
1. HBase Client向Master写入数据
2. 对应RegionServer写完HLog后返回Client请求
3. 同时replication线程轮询HLog发现有新的数据,发送给Slave
4. Slave处理完数据后返回给Master,Master收到Slave的返回信息,在Zookeeper中标记已经发送到Slave的HLog位置
HBASE SHELL数据定义语言(DDL)
1.create: 创建一个表。
eg:create ‘表名’,‘列族名1’,‘列族名2’,‘列族名N’
2.list: 列出HBase的所有表。
3.disable: 禁用表。
eg:disable ‘表名’
4.is_disabled: 验证表是否被禁用。
eg: is_disabled ‘表名’
5.enable: 启用一个表。
eg: enable ‘表名’
6.is_enabled: 验证表是否已启用。
eg: is_enabled ‘表名’
7.describe: 显示表相关的详细信息。
eg: describe‘表名’
8.Namespace:一组表的逻辑分组,类似于数据库实例database
eg:create_namespace ‘test’
9.exists: 验证表是否存在。
eg:exists ‘表名’
10.alter: 修改表。
修改表结构
#首先停用test表 disable 'test’
#添加两个列族fcol3和fcol4 alter 'test', NAME => 'fcol3',Name => 'fcol4’
#启用表 enable 'test’
删除一个列族:
alter ‘test’, NAME => ‘fcol4’, METHOD => ‘delete’
或 alter 'test', 'delete' => 'fcol4’
添加列族fcol3同时删除列族fcol4:
alter 'test', {NAME => 'fcol3'}, {NAME => 'fcol4', METHOD => 'delete’}
drop: 从HBase中删除表(drop的表必须是disable的)。
drop_all: 丢弃在命令中给出匹配“regex”的表。
数据操纵语言(DML)
put: 向hbase表中插入数据
eg:向test表中插入数据,row key为rk001,列族fcol1中添加col1列,值为val1
put 'test', 'rk001', 'fcol1:col1', 'val1’
get: 取行或单元格的内容。
eg:获取test表中row key为rk001的所有数据
get ‘test’,‘rk001’
获取test表中row key为rk001,fcol1列族的信息
get ‘test’,‘rk001’,‘fcol’
delete: 删除表中的单元格值。
delete ‘表名’, ‘行键’, ‘列族名:列名’
deleteall: 删除给定行的所有单元格。
deleteall ‘表名’, ‘行键’
hadoop层数据迁移
Hadoop层的数据迁移主要用到DistCp(Distributed Copy), DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。
简单的distcp参数形式如下:
hadoop distcp \
hdfs://src-hadoop-address:9000/table_name \
hdfs://dst-hadoop-address:9000/table_name \
HBase层数据迁移
copyTable方式:
copyTable也是属于HBase数据迁移的工具之一,以表级别进行数据迁移。copyTable的本质也是利用MapReduce进行同步的。
copyTable支持如下几个场景:
表深度拷贝:相当于一个快照,不过这个快照是包含原表实际数据的,使用方式如下:
create 'table_snapshot',{NAME=>"i"}
hbaseorg.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy table_snapshot
集群间拷贝:在集群之间以表维度同步一个表数据,使用方式如下:
create 'table_test',{NAME=>"i"} #目的集群上先创建一个与原表结构相同的表:
hbaseorg.apache.hadoop.hbase.mapreduce.CopyTable--peer.adr=zk-addr1,zk-addr2,zk-addr3:2181:/hbase table_test
部分表备份:只备份其中某几个列族数据,使用方式如下:
hbaseorg.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1,srcCf2 #copy cf1,cf2两个列族,不改变列族名字
hbaseorg.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1:dstCf1, srcCf2:dstCf2 #copy srcCf1到目标dstCf1新列族
Export/Import阶段
Export阶段:
hbaseorg.apache.hadoop.hbase.mapreduce.Export
Import阶段:
hbaseorg.apache.hadoop.hbase.mapreduce.Importsnapshot数据迁移
A.创建快照:
在原集群上,用snapshot命令创建快照,命令如下:
snapshot'src_table', 'snapshot_src_table’
B.数据迁移:在MR集群上使用如下命令:
hbaseorg.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot snapshot_src_table \
-copy-fromhdfs://src-hbase-root-dir/hbase \
-copy-to hdfs://dst-hbase-root-dir/hbase \
-mappers 20 \
-bandwidth 20
项目参考实例
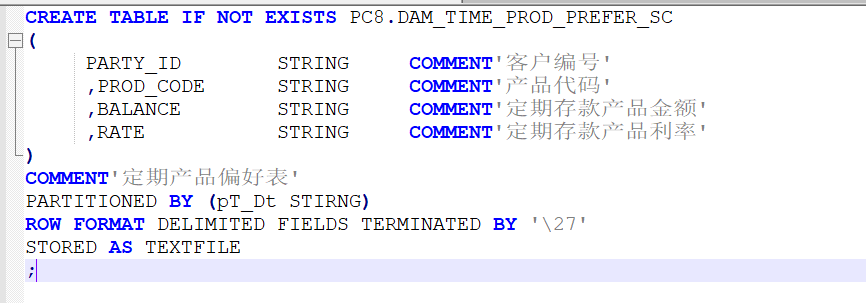
如上图中为一张hive表结构,该表为定期存款产品特征偏好表,主要做智能推荐,该表包括四个字段,其中客户编号(party_id)和产品代码(prod_code)为hive表中的主键.
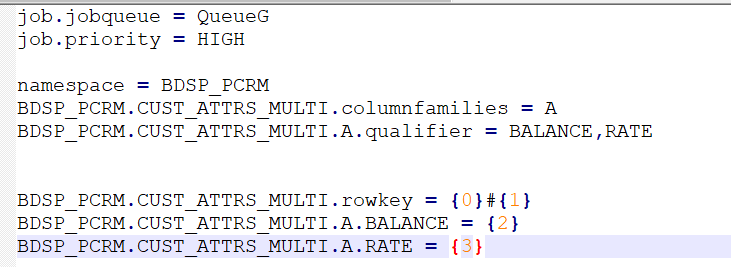
hbase表名:CUST_ATTRS_MULTI
jobqueue:指定队列,
priority:指定优先级
hbase表命名空间:BDSP_PCRM,
列族:A,
Qualifier:导入到hbase中对应的列名
Hbase配置参数表
一.存款产品特征表cp程序
Etl_job:DAM_WAP_TIME_PROD_PREFER_SC_210
该作业主要将hive的batch脚本批量数据从源集群中复制到集群中临时区
etl_system:指定该job作业所在的作业组,一般格式为 应用名_0000xx
LOAD_FREQ:1(日频)
OFFSET:999
作业对应的脚本名:
${BDSP_ROOT}/AUTOMATION/ETL-COMMON/SHELL/execute_HDFS_CP_0000.sh
脚本参数:库名 | hive表名 | 队列
依赖作业的etl_system:etl_job:库名:hivebatch作业名
二.存款产品特征表导入程序
Etl_job:PC8-DAM_WAP_TIME_PROD_PREFER_SC_CUST_ATTRS_MULTI_300
该作业主要将集群中临时区数据加载到hbase目标表中
etl_system:指定该job作业所在的作业组,一般格式为 应用名_0000xx
LOAD_FREQ:1(日频)
OFFSET:999
作业对应的脚本名:
${BDSP_ROOT}/AUTOMATION/ETL-COMMON/SHELL/execute_hbase_load_0000.sh
脚本参数:库名 | hive表名 | hbase表
依赖作业的etl_system:etl_job:cp程序作业组:cp程序作业
作者:蔡显锋,一位默默敲代码的程序员
编辑:徐菲

据说中国有句古语叫「金无足赤,人无完人」,但是,如果谁真的想打起灯笼来到市面上寻找完人,最终令他感到的可能不是一种失望,而是一种意外:完人可能就是那些终日为「善」而奔走,而又在不知不觉中实现了「美」的「真」实不虚的普通人。
追求完美是正常而有缺憾的人性。
--尼采

