




前几天网友来信说帮忙实现这样一个架构:只有两台机器,需要实现其中一台死机之后另一台能接管这台机器的服务,并且在两台机器正常服务时,两台机器都能用上。于是设计了如下的架构。
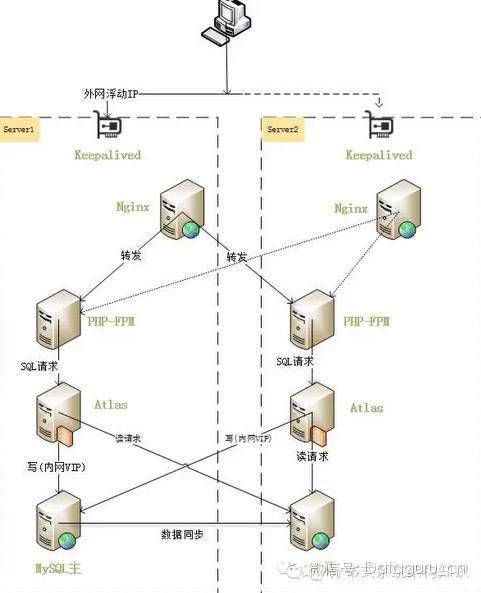
架构简介
此架构主要是由keepalived实现双机高可用,维护了一个外网VIP,一个内网VIP。正常情况时,外网VIP和内网VIP都绑定在server1服务器,web请求发送到server1的Nginx,nginx对于静态资源请求就直接在本机检索并返回,对于PHP的动态请求,则负载均衡到server1和server2。对于SQL请求,会将此类请求发送到Atlasmysql中间件,Atlas接收到请求之后,把涉及写操作的请求发送到内网VIP,读请求操作发送到server2,这样就实现了读写分离。
当主服务器server1宕机时,keepalived检测到后,立即把外网VIP和内网VIP绑定到server2,并把server2的mysql切换成主库。此时由于外网VIP已经转移到了server2,web请求将发送给server2的nginx。nginx检测到server1宕机,不再把请求转发到server1的php-fpm。之后的sql请求照常发送给本地的atlas,atlas把写操作发送给内网VIP,读操作发送给server2 mysql,由于内网VIP已经绑定到server2了,server2的mysql同时接受写操作和读操作。
当主服务器server1恢复后,keepalived不抢占server2的VIP,继续正常服务。我们可以把server1的mysql切换成主,也可以切换成从。
架构要求
要实现此架构,需要三个条件:
服务器可以设置内网ip,并且设置的内网IP互通;
服务器可以随意绑定IDC分配给我们使用的外网IP,即外网IP没有绑定MAC地址;
MySQL服务器支持GTID,即MySQL-5.6.5以上版本。
环境说明
server1
eth0: 10.96.153.110(对外IP)
eth1: 192.168.3.100(对内IP)
server2
eth0: 10.96.153.114(对外IP)
eth1: 192.168.3.101(对内IP)
系统都是CentOS-6。
对外VIP: 10.96.153.239
对内VIP: 192.168.3.150
hosts设置
/etc/hosts:
192.168.3.100 server1
192.168.3.101 server2
Nginx PHP MySQL安装
这几个软件的安装推荐使用EZHTTP来完成。
Nginx配置
Server1配置
http {
[...]
upstream php-server {
server 192.168.3.101:9000;
server 127.0.0.1:9000;
keepalive 100;
}
[...]
server {
[...]
location ~ \.php$ {
fastcgi_pass php-server;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
[...]
}
[...]
}
Server2配置
http {
[...]
upstream php-server {
server 192.168.3.100:9000;
server 127.0.0.1:9000;
keepalive 100;
}
[...]
server {
[...]
location ~ \.php$ {
fastcgi_pass php-server;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
[...]
}
[...]
}
这两个配置主要的作用是设置php请求的负载均衡。
MySQL配置
mysql util安装
我们需要安装mysql util里的主从配置工具来实现主从切换。
cd tmpwget http://dev.mysql.com/get/Downloads/MySQLGUITools/mysql-utilities-1.5.3.tar.gz
tar xzf mysql-utilities-1.5.3.tar.gz
cd mysql-utilities-1.5.3
python setup.py build
python setup.py install
mysql my.cnf配置
server1:
[mysql]
[...]
protocol=tcp
[...]
[...]
[mysqld]
[...]
# BINARY LOGGING #
log-bin = usr/local/mysql/data/mysql-bin
expire-logs-days = 14sync-binlog = 1
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency =true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
server-id=1
report-host=server1
report-port=3306
[...]
server2:
[mysql]
[...]
protocol=tcp
[...]
[mysqld]
[...]
# BINARY LOGGING #
log-bin = usr/local/mysql/data/mysql-bin
expire-logs-days = 14
sync-binlog = 1
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency =true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
server-id=2
report-host=server2
report-port=3306
[...]
这两个配置主要是设置了binlog和启用gtid-mode,并且需要设置不同的server-id和report-host。
开放root帐号远程权限:
我们需要在两台mysql服务器设置root帐号远程访问权限。
mysql> grant all on *.* to 'root'@'192.168.3.%' identified by 'Xp29at5F37' with grant option;
mysql> grant all on *.* to 'root'@'server1' identified by 'Xp29at5F37' with grant option;
mysql> grant all on *.* to 'root'@'server2' identified by 'Xp29at5F37' with grant option;
mysql> flush privileges;
设置mysql主从
在任意一台执行如下命令:
mysqlreplicate --master=root:Xp29at5F37@server1:3306 --slave=root:Xp29at5F37@server2:3306 --rpl-user=rpl:o67DhtaW
# master on server1: ... connected.
# slave on server2: ... connected.
# Checking for binary logging on master...
# Setting up replication...
# ...done.
显示主从关系
mysqlrplshow --master=root:Xp29at5F37@server1 --discover-slaves-login=root:Xp29at5F37
# master on server1: ... connected.
# Finding slaves for master: server1:3306
# Replication Topology Graph
server1:3306 (MASTER)
|
+--- server2:3306 - (SLAVE)
检查主从状态
mysqlrplcheck --master=root:Xp29at5F37@server1 --slave=root:Xp29at5F37@server2
# master on server1: ... connected.
# slave on server2: ... connected.test Description Status
---------------------------------------------------------------------------
Checking for binary logging on master [pass]
Are there binlog exceptions? [pass]
Replication user exists? [pass]
Checking server_id values [pass]
Checking server_uuid values [pass]
Is slave connected to master? [pass]
Check master information file [pass]
Checking InnoDB compatibility [pass]
Checking storage engines compatibility [pass]
Checking lower_case_table_names settings [pass]
Checking slave delay (seconds behind master) [pass]
# ...done.
在server2建立主从切换脚本
vi data/sh/mysqlfailover.sh
#!/bin/bash
mysqlrpladmin --slave=root:Xp29at5F37@server2:3306 failoverchmod +x data/sh/mysqlfailover.sh
Keepalived配置
keepalived安装(两台都装)
yum -y install keepalivedchkconfig keepalived on
keepalived配置(server1)
vi etc/keepalived/keepalived.conf
vrrp_sync_group VG_1 {
group {
inside_network
outside_network
}
}
vrrp_instance inside_network {
state BACKUP
interface eth1
virtual_router_id 51
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass 3489
}
virtual_ipaddress {
192.168.3.150/24
}
nopreempt
}
vrrp_instance outside_network {
state BACKUP
interface eth0
virtual_router_id 50
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass 3489
}
virtual_ipaddress {
10.96.153.239/24
}
nopreempt
}
keepalived配置(server2)
vrrp_sync_group VG_1 {
group {
inside_network
outside_network
}
}
vrrp_instance inside_network {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 3489
}
virtual_ipaddress {
192.168.3.150
}
notify_master data/sh/mysqlfailover.sh
}
vrrp_instance outside_network {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 3489
}
virtual_ipaddress {
10.96.153.239/24
}
}
此keepalived配置需要注意的是:
两台server的state都设置为backup,server1增加nopreempt配置,并且server1 priority比server2高,这样用来实现当server1从宕机恢复时,不抢占VIP;
server2设置notify_master data/sh/mysqlfailover.sh,意味着server2接管server1后,执行这个脚本,以把server2的mysql提升为主。
Atlas设置
atlas安装
到这里下载最新版本,https://github.com/Qihoo360/Atlas/releases
cd tmp
wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpmrpm -i Atlas-2.2.1.el6.x86_64.rpm
atlas配置
cd usr/local/mysql-proxy/confcp test.cnf my.cnf
vi my.cnf
调整如下参数,
proxy-backend-addresses = 192.168.3.150:3306
proxy-read-only-backend-addresses = 192.168.3.101:3306
pwds = root:qtyU1btXOo074Itvx0UR9Q==
event-threads = 8
注意:
proxy-backend-addresse设置为内网VIP
proxy-read-only-backend-addresses设置为server2的IP
root:qtyU1btXOo074Itvx0UR9Q==设置数据库的用户和密码,密码是通过/usr/local/mysql-proxy/bin/encrypt Xp29at5F37生成。更详细参数解释请查看,Atlas配置详解。
启动atlas
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/my.cnf
之后程序里配置mysql就配置127.0.0.1:1234就好。
server1主宕机测试
测试keepalived是否工作正常,我们来模拟server1宕机。在server1上执行shutdown关机命令。此时我们登录server2,执行ip addr命令,输出如下:
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:81:9d:42 brd ff:ff:ff:ff:ff:ff
inet 10.96.153.114/24 brd 10.96.153.255 scope global eth0
inet 10.96.153.239/24 scope global secondary eth0
inet6 fe80::20c:29ff:fe81:9d42/64 scope link
valid_lft forever preferred_lft forever
3: eth1: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:81:9d:4c brd ff:ff:ff:ff:ff:ff
inet 192.168.3.101/24 brd 192.168.3.255 scope global eth1
inet 192.168.3.150/32 scope global eth1
inet6 fe80::20c:29ff:fe81:9d4c/64 scope link
valid_lft forever preferred_lft forever
我们看到对外VIP 10.96.153.239和对内IP 192.168.3.150已经转移到server2了,证明keepalived运行正常。
测试是否自动切换了主从,登录server2的mysql服务器,执行show status;命令,如下:
mysql> show slave statusG
Empty set (0.00 sec)
我们发现从状态已经为空,证明已经切换为主了。
测试server1是否抢占VIP,为什么要测试这个呢?如果server1恢复之后抢占了VIP,而我们的Atlas里后端设置的是VIP,这样server1启动之后,sql的写操作就会向server1的mysql发送,而server1的mysql数据是旧于server2的,所以这样会造成数据不一致,这个是非常重要的测试。
我们先来启动server1,之后执行ip addr,输出如下:
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:f1:4f:4e brd ff:ff:ff:ff:ff:ff
inet 10.96.153.110/24 brd 10.96.153.255 scope global eth0
inet6 fe80::20c:29ff:fef1:4f4e/64 scope link
valid_lft forever preferred_lft forever
3: eth1: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:f1:4f:58 brd ff:ff:ff:ff:ff:ff
inet 192.168.3.100/24 brd 192.168.3.255 scope global eth1
inet6 fe80::20c:29ff:fef1:4f58/64 scope link
valid_lft forever preferred_lft forever
我们看到,server1并没有抢占VIP,测试正常。不过另人郁闷的是,在虚拟机的环境并没有测试成功,不知道为什么。
如何恢复server1
设置server1 mysql为从,server1从宕机中恢复之后,mysql的数据已经旧于server2的数据了,这时我们先设置server1 mysql为从。
mysqlreplicate --master=root:Xp29at5F37@server2:3306 --slave=root:Xp29at5F37@server1:3306 --rpl-user=rpl:o67DhtaW
# master on server2: ... connected.
# slave on server1: ... connected.
# Checking for binary logging on master...
# Setting up replication...
# ...done.
看到提示是设置成功了。
获取server1 mysql数据数据同步情况,server1 mysql刚从宕机恢复,有可能数据远远落后于server2 mysql,所以我们先查看它们之间的数据同步情况。登录server1 mysql,执行如下sql:
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: server2
Master_User: rpl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 2894
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 408
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: yesSlave_SQL_Running: Yes
我们记下Read_Master_Log_Pos的值为2894,登录server2 mysql,执行如下sql:
mysql> show master statusG
*************************** 1. row ***************************
File: mysql-bin.000004
Position: 2894
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 9347e042-9044-11e4-b4f0-000c29f14f4e:1-7,
f5bbfc15-904a-11e4-b519-000c29819d42:1-6
1 row in set (0.00 sec)
记下Position的值,并与Read_Master_Log_Pos比较,如果这两个值非常相近或相等,说明数据已经同步得差不多了,可以进行切换操作;如果差得很远,需要等待它们同步完成。
屏蔽mysql写操作
我们需要在切换时先禁止sql的写操作,如果不这样做,就会在切换时造成数据不一致的问题。屏蔽写操作我们在Atlas上操作。在server2执行登录Atlas命令:
mysql -h127.0.0.1 -P2345 -uuser -ppwd
mysql> SELECT * FROM backends;
+-------------+--------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+--------------------+-------+------+
| 1 | 192.168.3.150:3306 | up | rw |
| 2 | 192.168.3.101:3306 | up | ro |
+-------------+--------------------+-------+------+
2 rows in set (0.00 sec)
执行SELECT * FROM backends;后我们看到backend id为1,所以我们执行SET OFFLINE 1;设置此后端下线。
mysql> SET OFFLINE 1;
+-------------+--------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+--------------------+---------+------+
| 1 | 192.168.3.150:3306 | offline | rw |
+-------------+--------------------+---------+------+
1 row in set (0.00 sec)
mysql> SELECT * FROM backends;
+-------------+--------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+--------------------+---------+------+
| 1 | 192.168.3.150:3306 | offline | rw |
| 2 | 192.168.3.101:3306 | up | ro |
+-------------+--------------------+---------+------+
2 rows in set (0.00 sec)
这时客户端就无法写入数据了。
恢复server1 mysql为主
mysqlrpladmin --master=root:Xp29at5F37@server2:3306 --new-master=root:Xp29at5F37@server1:3306 --demote-master --discover-slaves-login=root:Xp29at5F37 switchover
# Discovering slaves for master at server2:3306
# Discovering slave at server1:3306
# Found slave: server1:3306
# Checking privileges.
# Performing switchover from master at server2:3306 to slave at server1:3306.
# Checking candidate slave prerequisites.
# Checking slaves configuration to master.
# Waiting for slaves to catch up to old master.
# Stopping slaves.
# Performing STOP on all slaves.
# Demoting old master to be a slave to the new master.
# Switching slaves to new master.
# Starting all slaves.
# Performing START on all slaves.
# Checking slaves for errors.
# Switchover complete.
再次检查是否恢复成功.
mysqlrplcheck --master=root:Xp29at5F37@server1 --slave=root:Xp29at5F37@server2
# master on server1: ... connected.
# slave on server2: ... connected.
Test Description Status
---------------------------------------------------------------------------
Checking for binary logging on master [pass]
Are there binlog exceptions? [pass]
Replication user exists? [pass]
Checking server_id values [pass]
Checking server_uuid values [pass]
Is slave connected to master? [pass]
Check master information file [pass]
Checking InnoDB compatibility [pass]
Checking storage engines compatibility [pass]
Checking lower_case_table_names settings [pass]
Checking slave delay (seconds behind master) [pass]
# ...done.
设置VIP回到server1,在server2机器上执行:
/etc/init.d/keepalived restart
然后在两台机器分别执行ip addr查看ip绑定状态。
设置server2 atlas后端上线
server2上执行mysql -h127.0.0.1 -P2345 -uuser -ppwd登录,然后执行SET ONLINE 1;设置上线(这里1是后端的id,可以使用SELECT * FROM backends;查看)
mysql> SET ONLINE 1;
+-------------+--------------------+---------+------+
| backend_ndx | address | state | type |
+-------------+--------------------+---------+------+
| 1 | 192.168.3.150:3306 | unknown | rw |
+-------------+--------------------+---------+------+
1 row in set (0.00 sec)
mysql> SELECT * FROM backends;
+-------------+--------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+--------------------+-------+------+
| 1 | 192.168.3.150:3306 | up | rw |
| 2 | 192.168.3.101:3306 | up | ro |
+-------------+--------------------+-------+------+
2 rows in set (0.00 sec)
到这里server1就恢复为主了。
