




Kafka Consumer参数enable.auto.commit,它可能被你忽略?
涉及Kafka是2.2.1版本,并且消费方式是subscribe
enable.auto.commit介绍
关键字
1. enable.auto.commit:是否开启自动提交Offset 默认 true
2. auto.commit.interval.ms:自动提交Offset的时间间隔 默认 5000ms
示例
public static void main(String[] args) {Properties properties = new Properties();properties.put("enable.auto.commit", "true");properties.put("auto.commit.interval.ms", "1000");// 省略其他配置项 ......KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<String, String>(properties);kafkaConsumer.subscribe(Arrays.asList("test01"));while(true) {ConsumerRecords<String,String> records = kafkaConsumer.poll(Duration.ofSeconds(10));for(ConsumerRecord<String,String> record : records){System.out.println(record.value());}}}
Kafka中默认的消费位移的提交方式是自动提交,这个由"enable.auto.commit"参数决定,默认值:true。自动提交不是每次poll到消息就提交,而是周期性提交,周期时间由"auto.commit.interval.ms"参数决定,默认值:5000ms。
以下是 autoCommitEnabled的调用逻辑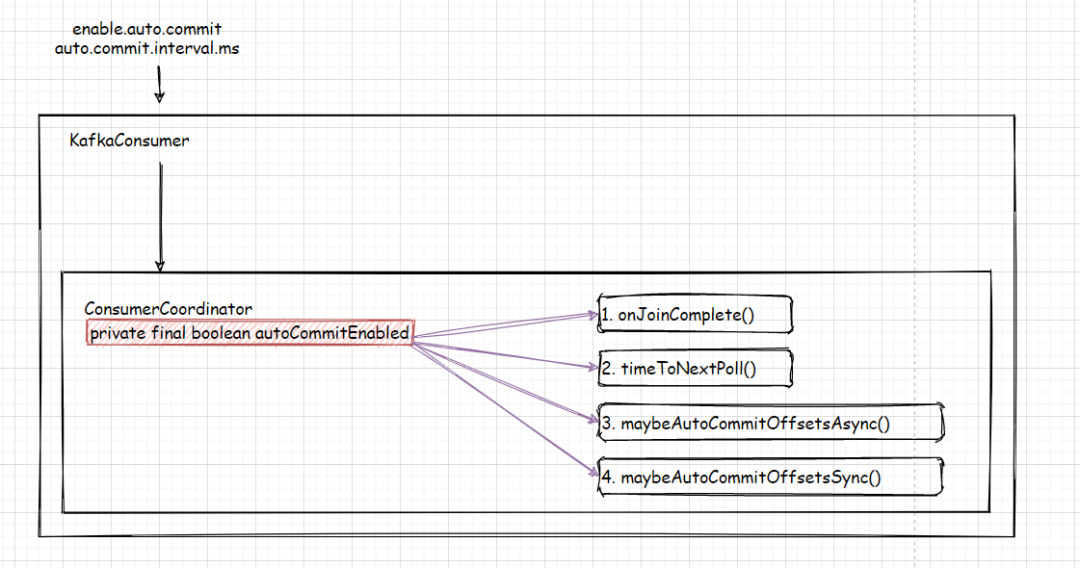
1. 当ConsumerCoordinate完成加入消费组后,根据Timer 重置下次提交Offsets的时间
// reschedule the auto commit starting from nowif (autoCommitEnabled) onJoinCompletethis.nextAutoCommitTimer.updateAndReset(autoCommitIntervalMs)
2. 计算KafkaConsumer poll的超时时间。在new KafkaConsumer的构造函数中有 this.time = Time.SYSTEM;
, 请注意Timer与Time的关系及 poll执行过程中将Timer参数的引用传递, 它会用来比较:心跳,poll,autocommit几个时间的最小值,来作为poll的超时时间。
/*** Return the time to the next needed invocation of {@link #poll(Timer)}.* @param now current time in milliseconds* @return the maximum time in milliseconds the caller should wait before the next invocation of poll()*/public long timeToNextPoll(long now) {if (!autoCommitEnabled) //timeToNextPollreturn timeToNextHeartbeat(now);return Math.min(nextAutoCommitTimer.remainingMs(), timeToNextHeartbeat(now));}
3. 当kafkaConsumer调用poll(), 都会调用updateAssignmentMetadataIfNeeded()
确保当前的coordinate是否初始化ok并且是否已经加入消费组,若开启自动提交Commit,它会周期性提交Offsets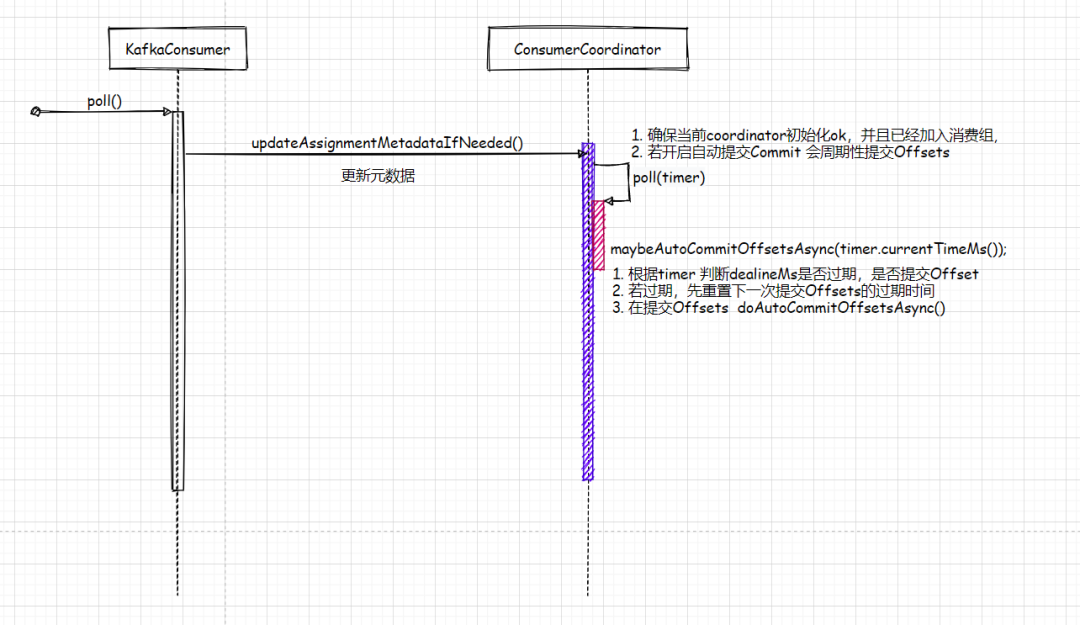
4. 当ConsumerCoordinate准备加入消费组,会同步提交当前消费的偏移量
自动提交消费偏移量的优缺点
无知不是说的初生牛犊不怕虎,而是你给自己埋了太多的坑,希望API场景使用得当。
优点:
1. 简单,省去了偏移量提交逻辑
2. 编码简洁,简化了偏移量的判断节点逻辑,比如 if(A条件) 处理后再提交commitAsync(),else(B条件) 处理后再提交commitAsync();
缺点:
1. 自动提交=延迟提交, 在延迟提交的过程中,会存在重复消费和消息丢失的情况
1.1 重复消费 当consumer拉取100条消息,处理第50条消息时候,程序挂掉,但是没有提交Offsets, 所以重新启动程序,又会重新拉取上次重复的消息, 所以会造成50条消息重复消费
1.2 丢失消息 当consumer拉取100条信息,并不是同步处理,而是存储在本地List,传输给其他线程来处理List消息, 当其他线程还没有来得及处理完List消息的时候,主线程poll,判断自动提交时间过期,需要提交Offsets。状态是:Offsets提交了,其他线程还没有处理完消息。这个时候程序挂了,所以重新启动程序,会拉取新数据,不会再拉取程序异常之前还未处理完的消息,这样就造成了消息丢失
enable.auto.commit=true的优化方法
1. 业务数据场景评估是不是适合自动提交,例如针对服务端日志统计,点击流pv,uv数据统计等等 可以设置为true,不过我司现在使用Flink框架来提供流式计算服务,Flink的State及CheckPoint机制来帮助确保EOS(Exactly-Once Semantics), 若比如订单,验证码发送建议手动提交,业务要求较高的数据,建议手动提交
2. 缩减auto.commit.interval.ms
值,减少重复或者丢失数据的占比
3. 根据consumer处理消息能力,适当设置max.poll.records
参数值,尽量避免拉取数据过多,处理不及时会影响Coordinate的存活状态,频繁加入退出消费组
