





文章转载自公众号:PostgreSQL学徒
作者:熊灿灿
前言
SQL优化是一个任重而道远的活,有时线上可能仅仅是一条小小的不起眼SQL突然跑慢了,便可能引发业务系统雪崩,所以SQL优化的重要性不言而喻,但是,不少DBA或者开发都认为SQL优化很简单,加索引。
遗憾的是,SQL优化是一项十分复杂的技术栈,不仅仅是:
analyze简单地收集一下统计信息
根据where列、order by列等创建索引
使用pg_hint_plan或者pg_plan_advsr建议一下优化器
使用prepareStatements绑定一下执行计划减少解析时间
无脑让开发降低并发,无脑scale out或者scale up,减少连接表的个数等
核心还要学会SQL的等价改写,但是这需要经历一个漫长的经验累积的过程,以我目前的功力还远远达不到去对SQL等价改写这个复杂的技术栈去评头论足,不过既然高级一点的不会,那我们就旁路,迂回战术,使用一些现有的工具,如pgMustard — review Postgres query plans quickly,pganalyze自动化性能诊断和优化产品等,助力我们优化SQL,达到事半功倍的效果。
今天分享的是PostgreSQL中,协助我们分析SQL的工具。

Depesz’ EXPLAIN ANALYZE visualizer
这个工具是Hubert Lubaczewski大师的杰作,地址在:https://explain.depesz.com/,使用很简单,先造个数据,模拟一下多表join
postgres=# create table t1( postgres(# id int primary key, postgres(# info text default 'tessssssssssssssssssssssssssssssssssssst', postgres(# state int default 0, postgres(# crt_time timestamp default now(), postgres(# mod_time timestamp default now() postgres(# );CREATE TABLEpostgres=# create table t2 (like t1 including all); CREATE TABLEpostgres=# create table t3 (like t1 including all);CREATE TABLEpostgres=# insert into t1 select generate_series(1,1000000); INSERT 0 1000000postgres=# insert into t2 select * from t1; INSERT 0 1000000postgres=# insert into t3 select * from t1;INSERT 0 1000000postgres=# explain select * from t1 join t2 using (id) join t3 using (id) where t1.id= random(); QUERY PLAN ----------------------------------------------------------------------------Nested Loop (cost=29908.93..57468.83 rows=5000 width=178) Join Filter: (t1.id = t3.id) -> Hash Join (cost=29908.50..54879.51 rows=5000 width=130) Hash Cond: (t2.id = t1.id) -> Seq Scan on t2 (cost=0.00..22346.00 rows=1000000 width=65) -> Hash (cost=29846.00..29846.00 rows=5000 width=65) -> Seq Scan on t1 (cost=0.00..29846.00 rows=5000 width=65) Filter: ((id)::double precision = random()) -> Index Scan using t3_pkey on t3 (cost=0.43..0.51 rows=1 width=56) Index Cond: (id = t2.id)(10 rows)
使用很简单,分别上传explain analyze + SQL的真实执行计划情况和对应的SQL
然后submit提交即可,就会基于当前的执行计划生成一份HTML的报告
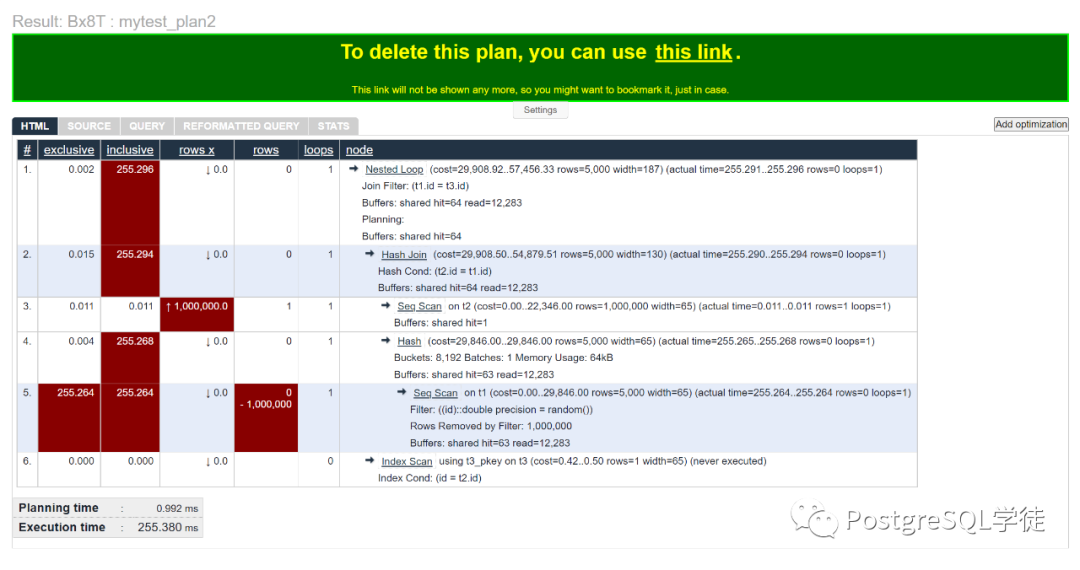
当然,还可以加上一些附加的explain选项,如buffers查看缓冲区的使用情况,这样会更加方便我们分析
postgres=# explain (analyze,buffers) select * from t1 join t2 using (id) join t3 using (id) where t1.id= random();
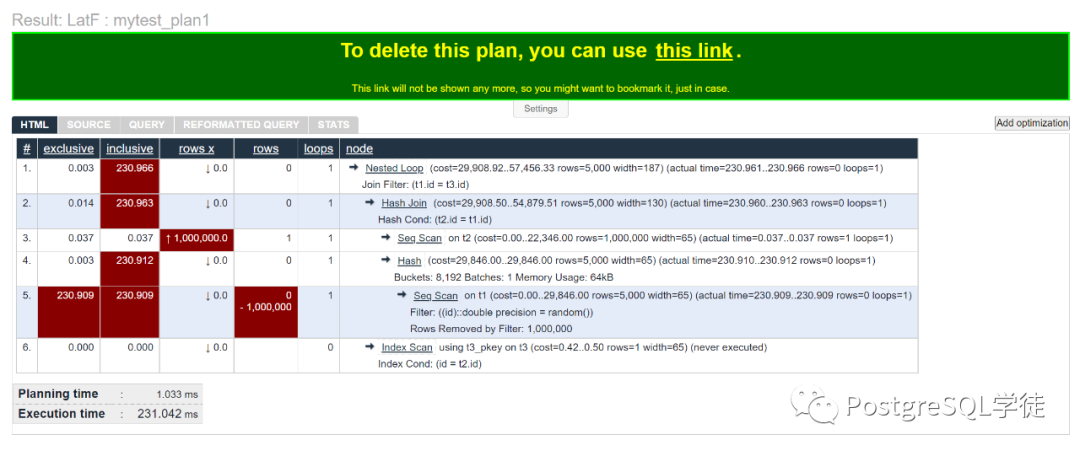
这里简单回顾一下执行计划:
explain命令的输出结果中每个cost就是该执行节点的代价估计。它的格式是xxx..xxx,在...之前的是预估的启动代价,即找到符合该节点条件的第一个结果预估所需要的代价,在...之后的是预估的总代价。而父节点的启动代价包含子节点的总代价。
actual time执行时间,格式为xxx...xxx,在...之前的是该节点实际的启动时间,即找到符合该节点条件的第一个结果实际需要的时间,在...之后的是该节点实际的执行时间
rows指的是该节点实际的返回行数
loops指的是该节点实际的重启次数。如果一个计划节点在运行过程中,它的相关参数值(如绑定变量)发生了变化,就需要重新运行这个计划节点。
执行计划看起来与原有的执行计划有点相似,但从外观上看起来更加清晰。还有一些有用的附加特性:
每个节点的总执行时间和净执行时间,耗时最高的节点用红色背景高亮显示,是我们的重点观察对象
inclusive:包含启动的总执行时间,会以由浅到深的颜色标识,对于特别大的会高亮显示,提醒我们这一块是优化重点
exclusive:较下层Node增长了多少时间,会以由浅到深的颜色标识,对于增长特别多的会高亮显示,提醒我们这一块是优化重点
rows x:这一列可以帮我们协助分析是什么因素让PostgreSQL错误地高估或低估了返回的行数。错误的估算会用红色背景高亮,此例中我们可以看到实际返回了1行,但是预估的行数是1000000,100万,可以看到,此时优化器严重估算错误 (实际原因是因为等于条件为random())
rows:就是实际的返回行数,以及通过过滤条件过滤了多少行,比如第5行,过滤了- 1000000行,实际返回了0行,说明选择率极高,可以考虑建合适的索引,比如万能Btree,适用于数组、多列的倒排Gin、时序数据Brin等
loops:就是实际的循环重启次数
当然还有一些其他有趣的特性,我将鼠标放至顶层Node节点,会将子节点用⭐标记出来,这会很方便我们看下层Node节点
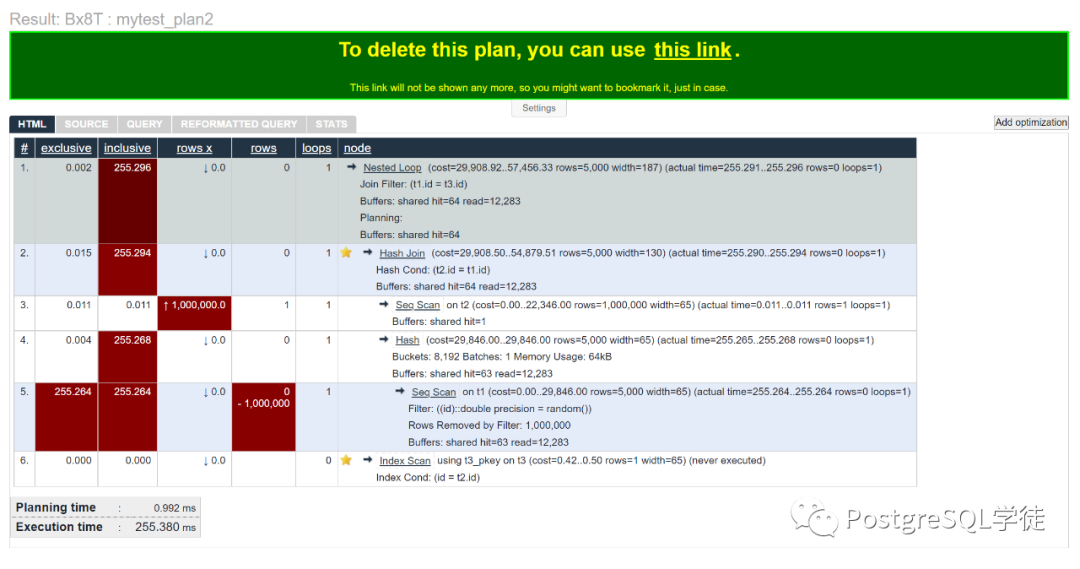
点击一下上层Node节点,会将子节点隐藏起来,对于特别长特别复杂的执行计划,会很方便我们分析SQL
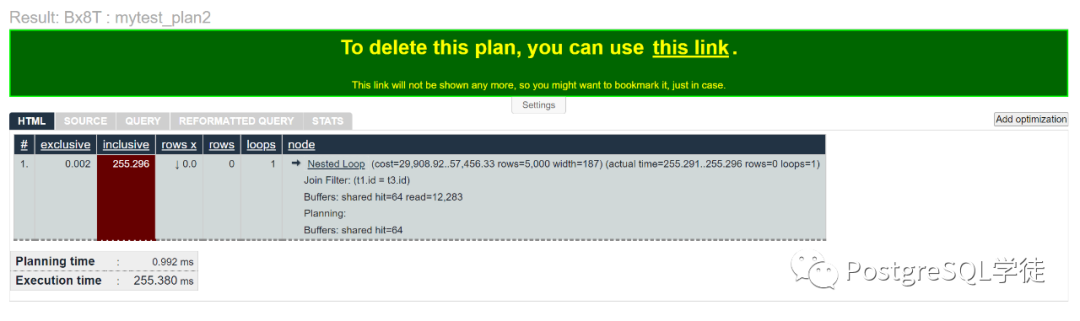
最后一个stats列则是SQL的总览信息
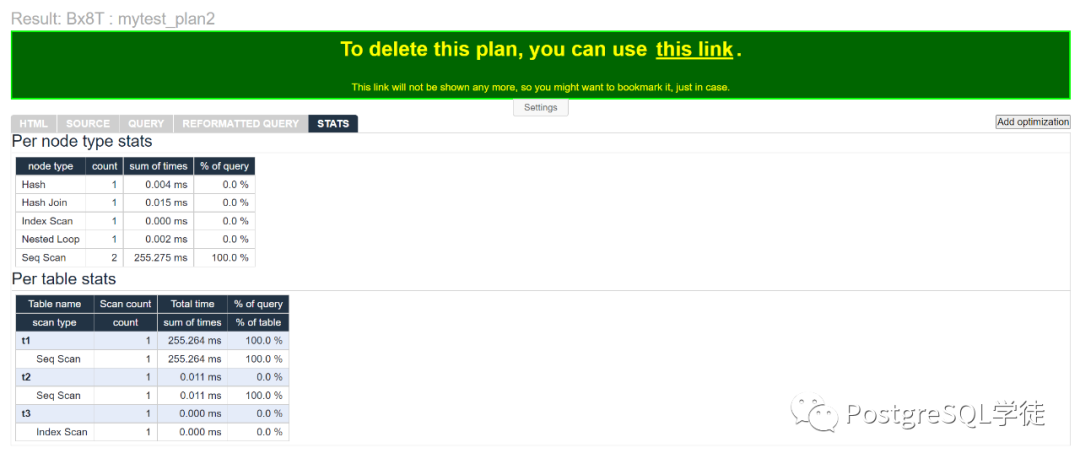
这里我们可以看到,我们的SQL实际跑起来,和统计信息的差距相差很多,因为我们的条件是等于random(),换成一个具体的值再看一下:
postgres=# explain (analyze,buffers) select * from t1 join t2 using (id) join t3 using (id) where t1.id= 5; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------Nested Loop (cost=1.27..25.35 rows=1 width=187) (actual time=0.656..0.661 rows=1 loops=1) Buffers: shared hit=11 read=1 -> Nested Loop (cost=0.85..16.90 rows=1 width=126) (actual time=0.641..0.643 rows=1 loops=1) Buffers: shared hit=7 read=1 -> Index Scan using t1_pkey on t1 (cost=0.42..8.44 rows=1 width=65) (actual time=0.613..0.614 rows=1 loops=1) Index Cond: (id = 5) Buffers: shared hit=3 read=1 -> Index Scan using t2_pkey on t2 (cost=0.42..8.44 rows=1 width=65) (actual time=0.021..0.022 rows=1 loops=1) Index Cond: (id = 5) Buffers: shared hit=4 -> Index Scan using t3_pkey on t3 (cost=0.42..8.44 rows=1 width=65) (actual time=0.012..0.013 rows=1 loops=1) Index Cond: (id = 5) Buffers: shared hit=4Planning Time: 0.206 msExecution Time: 0.730 ms(15 rows)
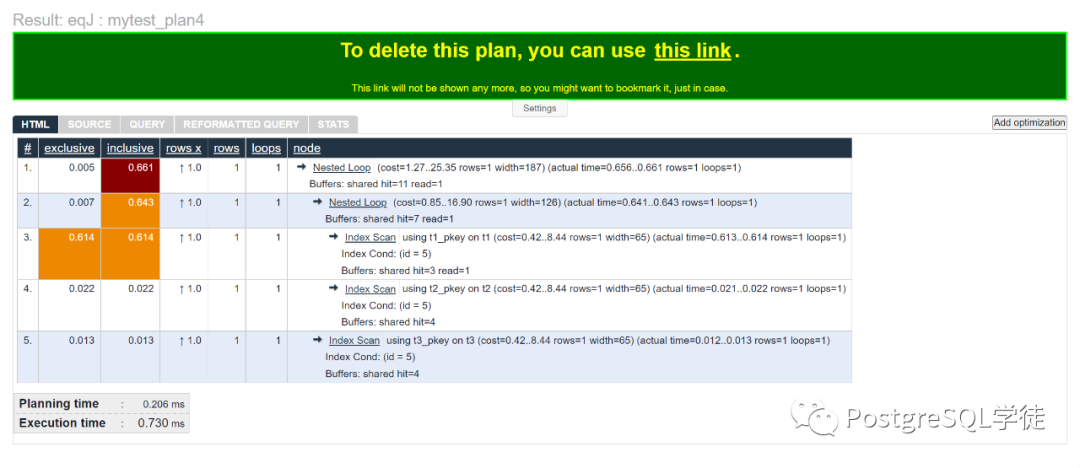
Dalibo’s EXPLAIN ANALYZE visualizer
又名大力波,网址:https://explain.dalibo.com/,大力波官方建议我们使用
For best results, use EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
我们继续用原来的SQL看一下效果,和Depesz的是两种不同风格,左边是一个总览Overview,右边是具体的细节Details
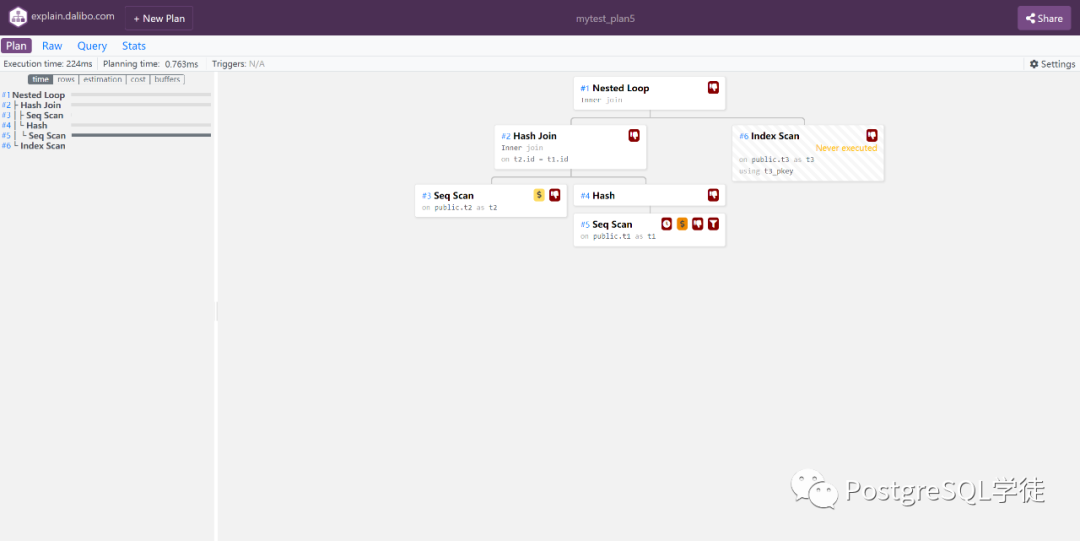
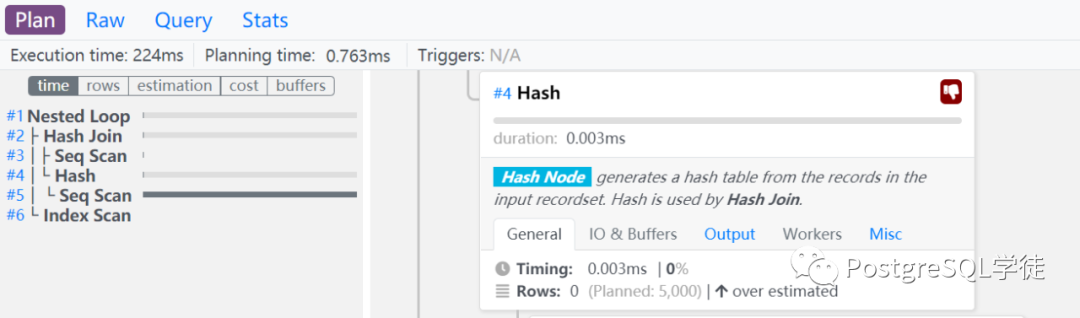
点开即可看到Details,有一个很贴心的地方在于,大力波会把Scan Node的意思告诉你,所以对于看不懂Node的,通过这里也可以看出一二
Seq Scan Node finds relevant records by sequentially scanning the input record set. When reading from a table, Seq Scans (unlike Index Scans) perform a single read operation (only the table is read).
Index Scan Node finds relevant records based on an Index. Index Scans perform 2 read operations: one to read the index and another to read the actual value from the table.
Nested Loop Node merges two record sets by looping through every record in the first set and trying to find a match in the second set. All matching records are returned.
Hash Join Node joins two record sets by hashing one of them (using a Hash Scan).
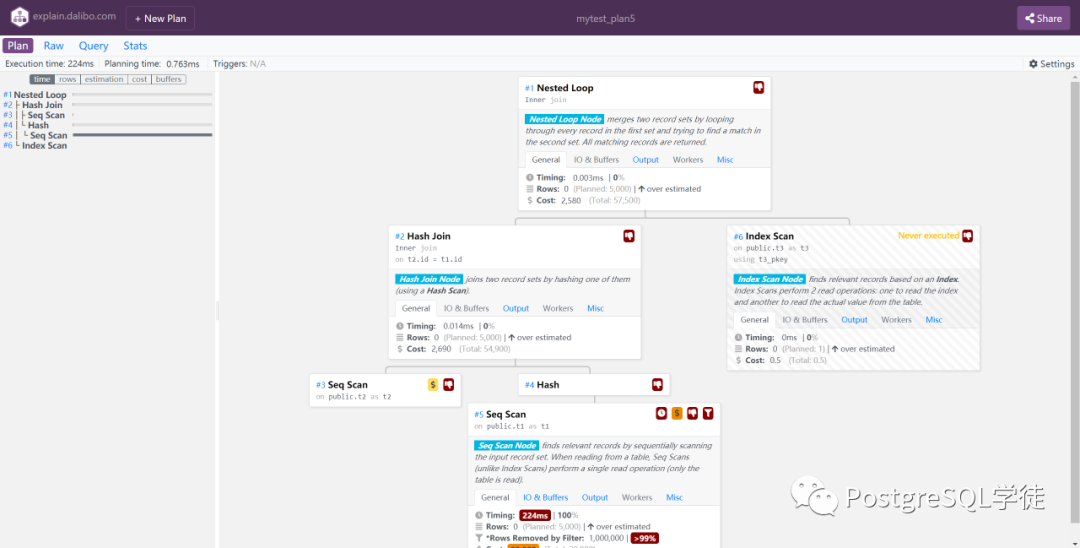
这种方式假如觉得抽象不易阅读的话,可以转化为传统风格,通过右上角的settings设置classic:

通过Node的Details,我们可以获取到如下信息,以Seq Scan为例:
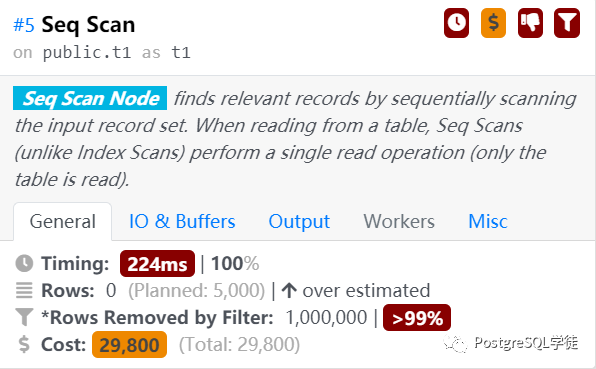
预估严重偏差,优化评估结果较真实结果多了5000行
过滤了99%的行,意味着选择率极高,可以考虑建索引
时间占用总SQL 100%的时间,也就是单条SQL基本全部耗时花在了这里,那么是我们重点观察的对象
成本较高29800,颜色是较高级别橙色
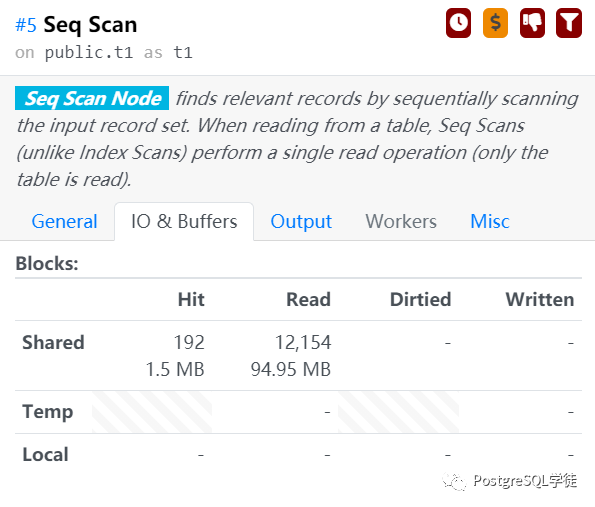
buffers命中了1.5MB,读取了95MB,另外还会显示出Dirtyed,比如shared_buffer太小了,bgwriter进程没有维护好足够多的buffer,那么backend process得自己去找合适的block,假如更不巧还是脏块的话,还得做刷脏的累活
左侧是可选的输出什么,比如输出时间还是输出cost
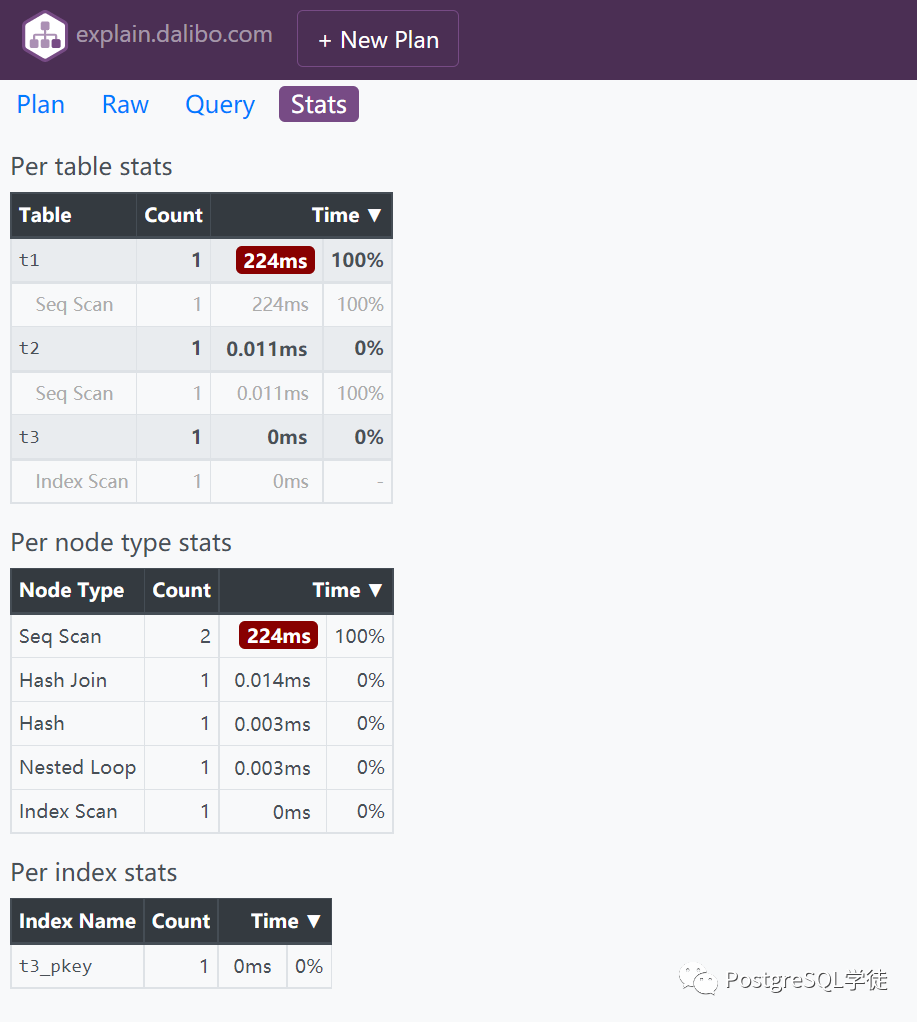
同理,还有一个总览stats
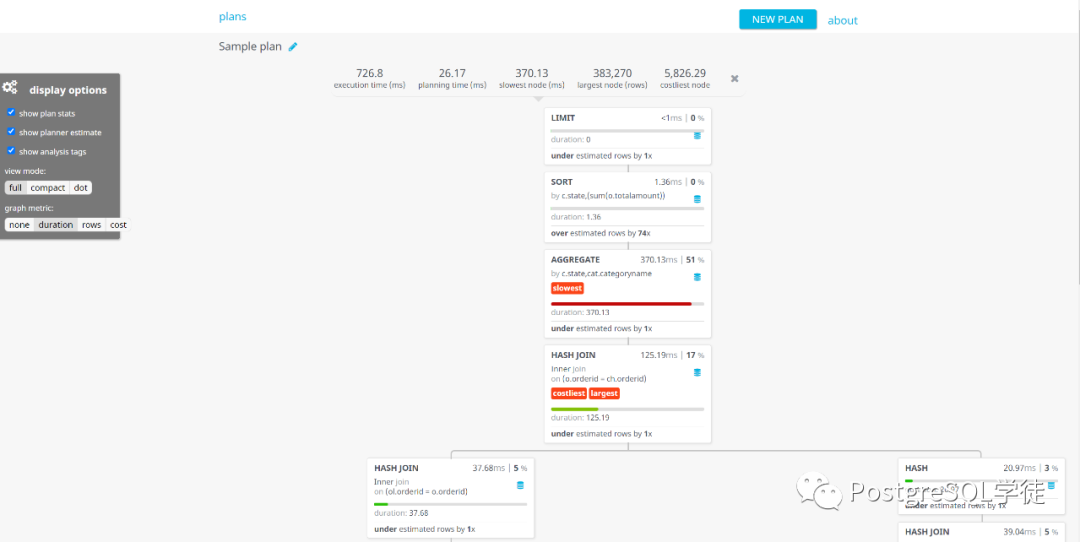
Tatiyants’s EXPLAIN ANALYZE visualizer
这个和大力波十分类似,可以看到slowest最慢的,costliest最昂贵的,返回结果集最大的largest的Node节点
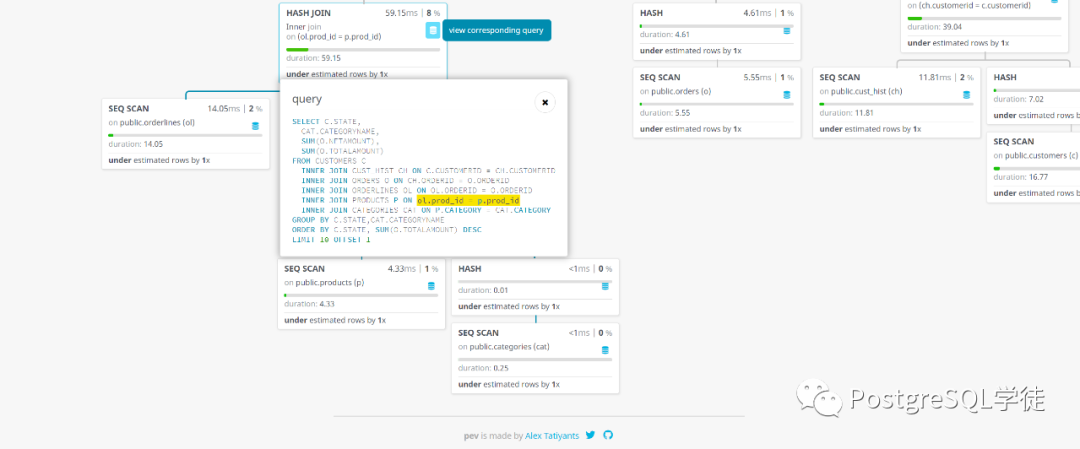
不过有一点很棒,可以看到具体Node的SQL,如下,其余就不再赘述,和大力波类似。
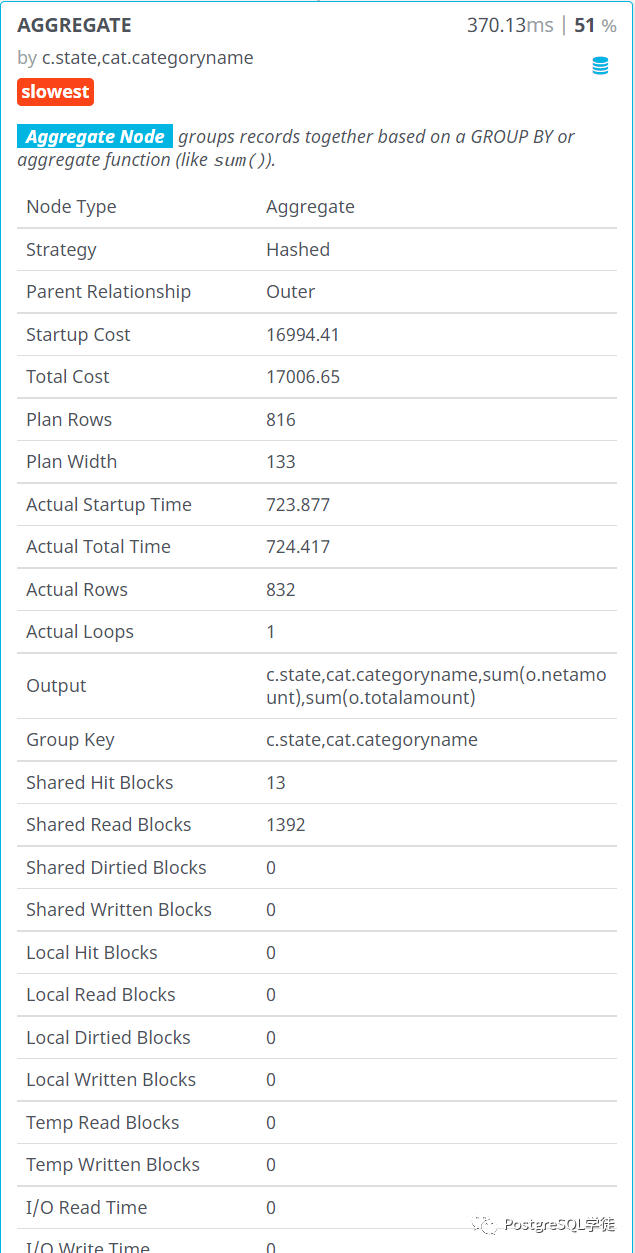
pgMustard
这个是一项收费的产品,https://www.pgmustard.com/,不过可以免费试用5次
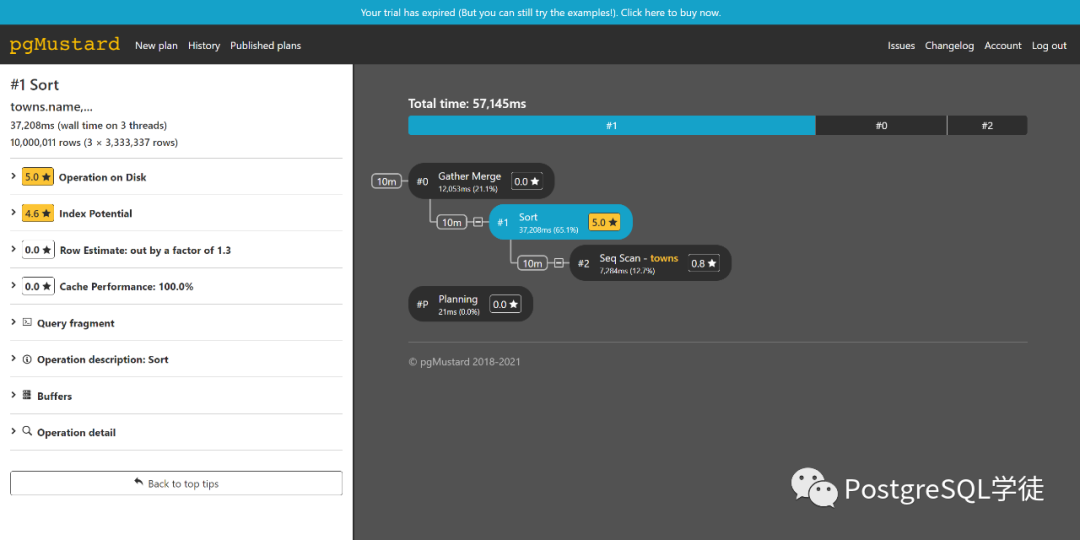
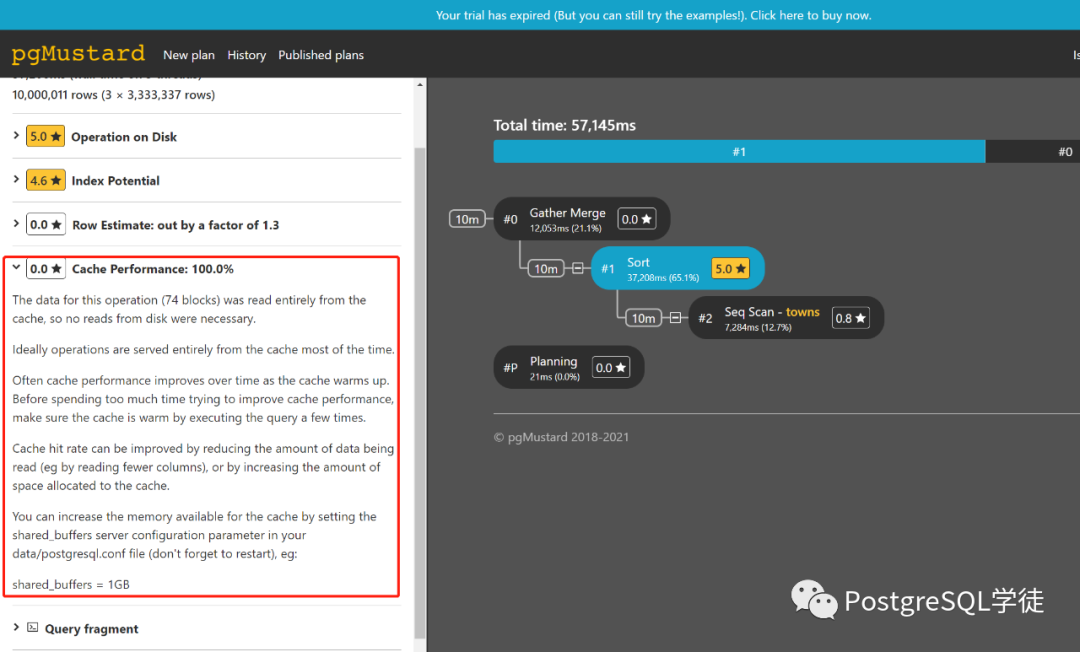
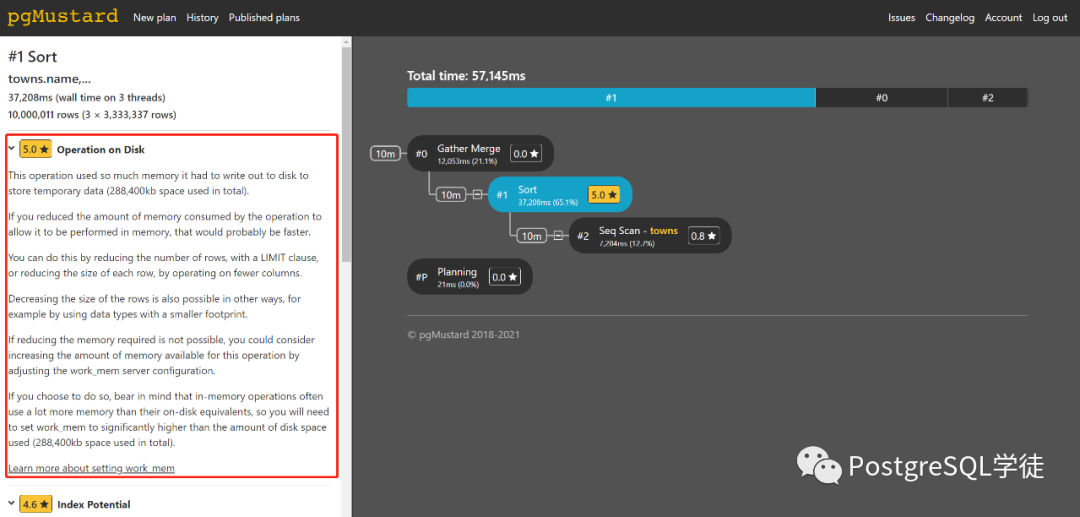
毕竟收费,功能更加高级一点,会输出相应的建议,对于新手来说,还是有点帮助的,聊胜于无
pganalyze
pganalyze应该称作是一项解决方案,监控、调优、告警等,都囊括其中了。在此就不做演示了,感兴趣的可以自行尝试,有15天的试用期。
我们可以当作是一个很好的学习案例,每个Node都会有解释:
https://pganalyze.com/docs/explain/other-nodes/set-op
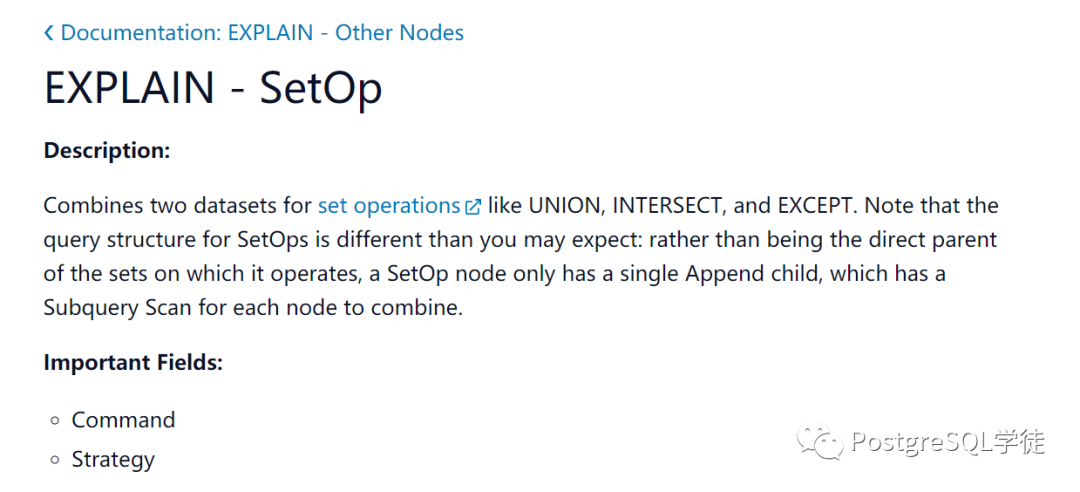
除此之外,pganalyze比较体系化,可以通过阅读文档,了解该产品的思想,以及对各种瓶颈的分析和建议。
Postgres Query Analysis & Postgres Explain Plans
Discover the root cause of critical issues, optimize slow queries, and find missing indices





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
