




Cassandra赠书 | Cassandra SASI Index 技术解密
本文根据10月24日在群里直播的内容整理,方便习惯看文字的同学。如果更习惯看视频,可以点击观看直播回放:
https://developer.aliyun.com/live/1590?spm=a2c4e.11153940.0.0.7ccd7cadgXL6cA
为何选择Cassandra
作为全球范围内最流行的宽表数据库,Apache Cassandra具备诸多优点:海量数据存储;简洁易上手的类SQL语法;总是在线;扩容灵活等。除了服务端的各种优点之外,Cassandra对各种语言客户端(driver)的高性能支持也是其实现易用性和良好性能的重要环节。Cassandra支持几乎所有流行语言的原生客户端:Java/Python/C++/C#/NodeJS/PHP/Ruby/Go/Perl/Scala...(详细列表参见Cassandra文档) 。下图列出了Cassandra支持的开发语言:

同时,Cassandra客户端良好的架构设计保证了在易于使用的同时能够从服务端获取最大的性能。下图是Cassandra和一些其他引擎的性能对比(出自https://www.datastax.com/nosql-databases/benchmarks-cassandra-vs-mongodb-vs-hbase)
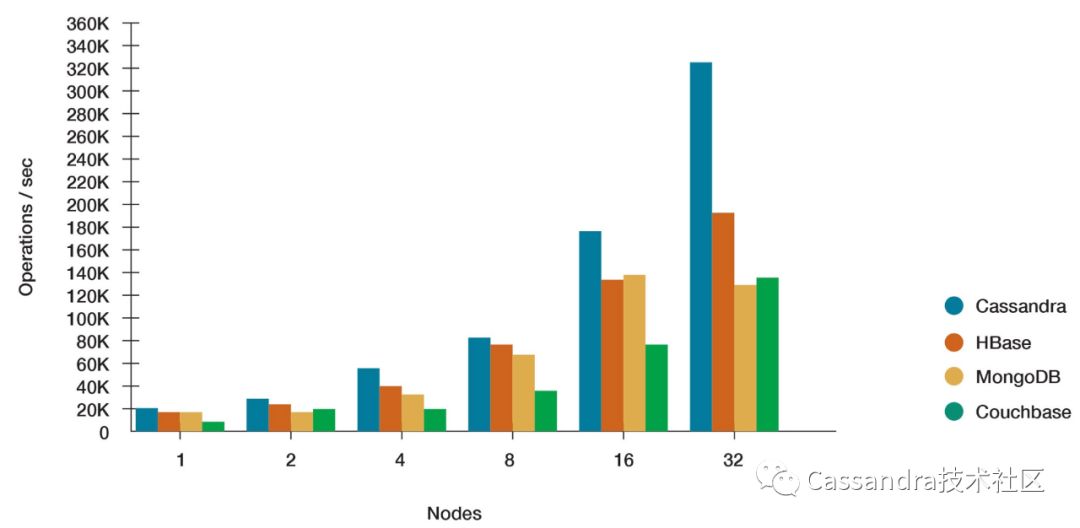
接下来的内容中,我们会从分布式数据库客户端要解决的一般问题出发,分析和比较几种常见的客户端实现方案,理解Cassandra高性能客户端背后的实现原理和架构,并以java driver为例,介绍Cassandra高性能客户端的异步接口、连接池、负载均衡、重试策略等重要特性的原理和配置参数。
分布式数据库客户端常见方案
要为分布式数据库设计一个客户端,可以简化为如下模型:
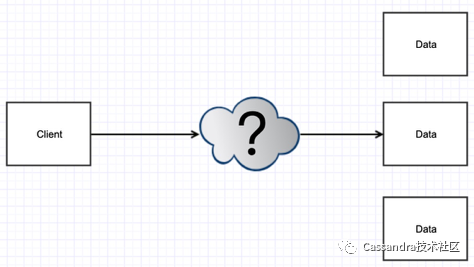
数据分布在不同的服务器节点上面,要如何设计客户端和服务器的交互方式?一般来说,这包含了如下问题:
•客户端如何知道数据在哪个节点?这涉及meta数据如何存储、交互的问题。•如何减少不必要的网络通信?一般要用到一些数据本地化的设计。•负载均衡:包括proxy之间、多个副本之间的均衡。•重客户端 vs 轻客户端,需要做一些取舍。•如何实现多语言的支持?有些引擎会为每种语言实现一个Native的客户端,也有一些引擎(例如HBase)会使用IDL的方式来定义跨语言的接口。•其他设计上的考虑,如连接池/线程调度/异步…
Mongodb方案
Mongodb Sharding集群的架构参见下图
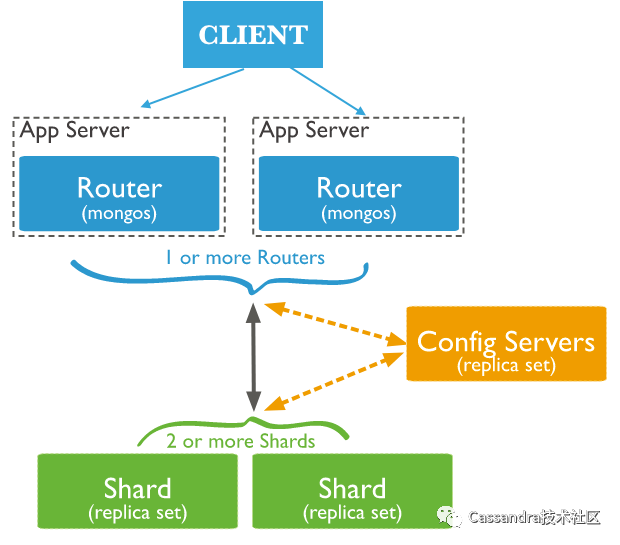
这是一个比较典型的proxy方式实现分布式数据库客户端的方案。在这种方案里面,meta数据单独存储在config server里面,前端通过一个proxy(mongos)来将客户端的请求路由到实际的数据节点(Shard)。
HBase方案
下图同时画出了HBase通过Java和其他语言访问的架构:
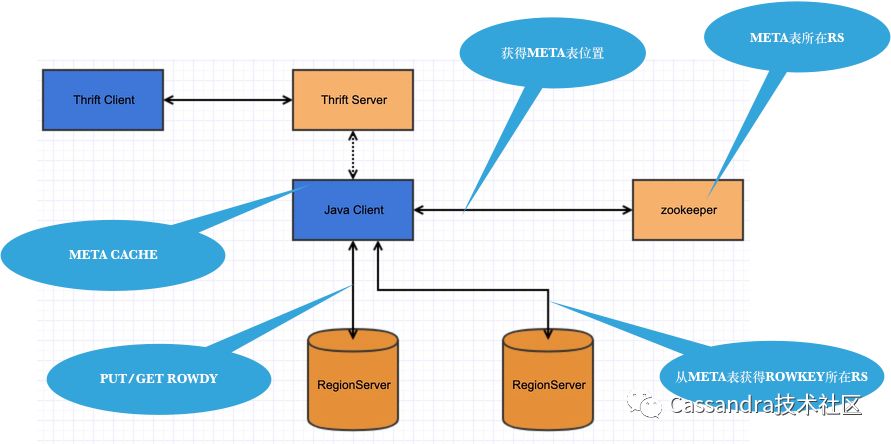
HBase的Thrift Server也是类似proxy的工作方式。
Cassandra方案
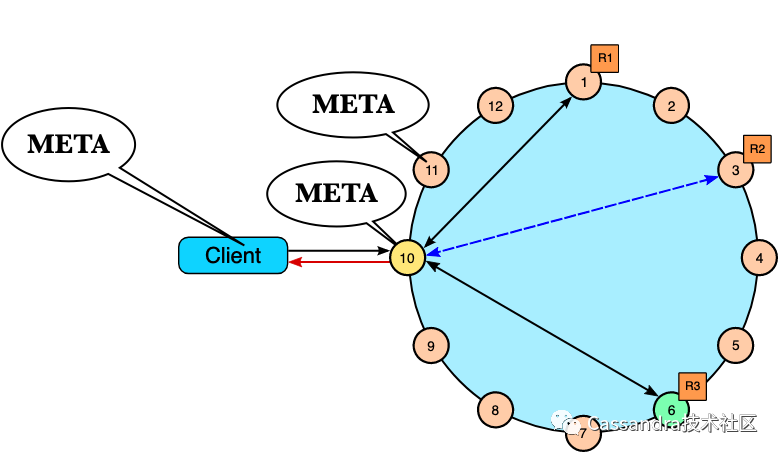
Cassandra与其他引擎不同的地方首先体现在每个服务端节点上都有meta信息,同时客户端也会在启动时拉取meta。这意味着:
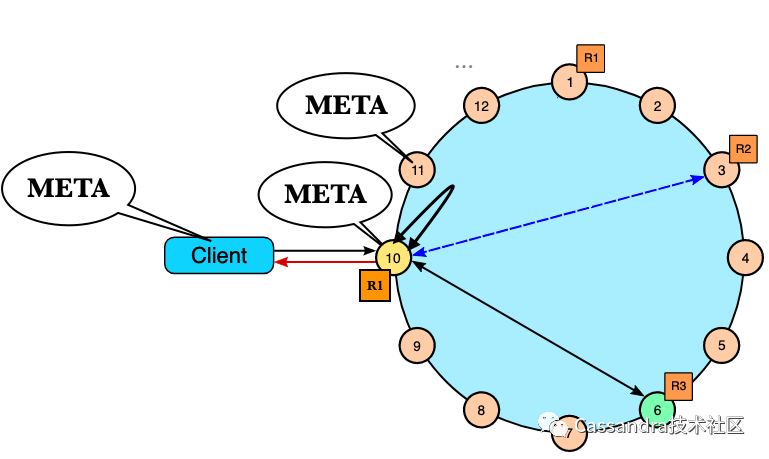
1.Cassandra在把客户端请求路由到数据节点时不需要从远端节点查找meta。2.Cassandra客户端的策略可以很灵活,既可以把任意一个节点作为proxy来发送请求,也可以像重客户端一样把请求发到数据所在的节点减少网络转发的请求,如下图:
比较
了解了这几种架构之后,我们可以再回到这一小节前面提到的问题,见下表:
| 比较内容 | MongoDB | HBase | Cassandra |
| meta存储 | 中心化 | 中心化 | 分布式 |
| 数据本地化 | 无 | 有 | 有 |
| proxy负载均衡 | 有 | 无 | 有 |
| 副本负载均衡 | 无 | 有 | 有 |
| 重客户端? | 轻客户端 | 重客户端 | 策略灵活,介于二者之间 |
| 多语言支持 | Native | Thrift | Native |
可见,Cassandra客户端的设计在每个点上几乎都做了最有利于性能的选择。
Cassandra客户端深入
了解了Cassandra客户端和服务端交互的方式之后,我们再来深入看一下Cassandra客户端的内部结构(以DataStax Java Driver为例):
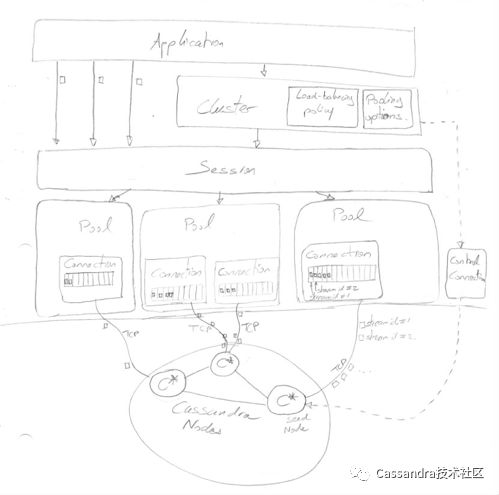
关于这个图的进一步描述可以参考https://beyondthelines.net/databases/the-cassandra-java-driver ,中文版本是https://yq.aliyun.com/articles/719645 ,这里只做简单的解读:
1.应用通过session对象和driver交互,session对象中管理着一系列连接池(pool)。2.客户端会针对服务器的每个节点创建一个连接池,每个连接池中有若干到节点的网络连接(Connection)。3.请求都是异步发送的,这也意味着每个连接可以并行发送若干请求。
各种对象之间的关系如下图:

Quick Start
一个简单的Java客户端示例代码如下:
public class Demo {public static void main(String[] args) {此处填写数据库连接点地址(公网或者内网的),控制台有几个就填几个。实际上SDK最终只会连上第一个可连接的连接点并建立控制连接,填写多个是为了防止单个节点挂掉导致无法连接数据库。此处无需关心连接点的顺序,因为SDK内部会先打乱连接点顺序避免不同客户端的控制连接总是连一个点。千万不要把公网和内网的地址一起填入。String[] contactPoints = new String[]{"$host1","$host2"};Cluster cluster = Cluster.builder().addContactPoints(contactPoints)填写账户名密码(如果忘记可以在 帐号管理 处重置).withAuthProvider(new PlainTextAuthProvider("$username", "$Password"))如果进行的是公网访问,需要在帐号名后面带上 @public 以切换至完全的公网链路。否则无法在公网连上所有内部节点,会看到异常或者卡顿,影响本地开发调试。/ 后续会支持网络链路自动识别(即无需手动添加@public)具体可以关注官网Changelog。//.withAuthProvider(new PlainTextAuthProvider("cassandra@public", "123456")).build();// 初始化集群,此时会建立控制连接(这步可忽略,建立Session时候会自动调用)cluster.init();// 连接集群,会对每个Cassandra节点建立长连接池。// 所以这个操作非常重,不能每个请求创建一个Session。合理的应该是每个进程预先创建若干个。// 通常来说一个够用了,你也可以根据自己业务测试情况适当调整,比如把读写的Session分开管理等。Session session = cluster.connect();//查询ResultSet res = session.execute("SELECT release_version FROM system.local");// ResultSet 实现了 Iterable 接口,我们直接将每行信息打印到控制台res.forEach(System.out::println);// 关闭Sessionsession.close();// 关闭Clustercluster.close();}}
更多例子可以参加阿里云帮助文档、直播演示的Demo及各种语言Driver的文档。
主要特性
Statements
这里主要介绍如下三种statement
(1). SimpleStatement
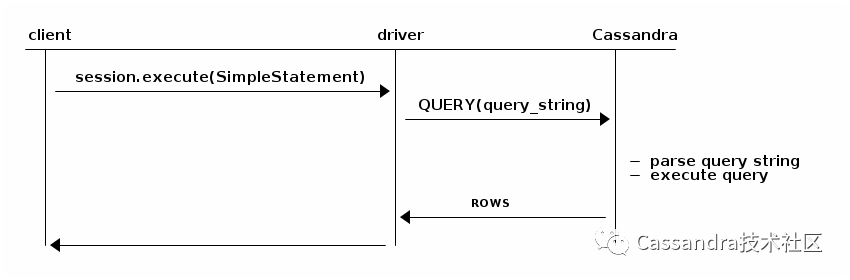
如下代码创建了一个SimpleStatement并执行:
session.execute("SELECT value FROM application_params WHERE name = 'greeting_message'");
这个语句执行过程中与服务端的交互过程如下图:
(2). PreparedStatement
PreparedStatement prepared = session.prepare("insert into product (sku, description) values (?, ?)");BoundStatement bound = prepared.bind("234827", "Mouse");session.execute(bound);session.execute(prepared.bind("987274", "Keyboard"));
PreparedStatement的执行过程分为两个步骤,prepare阶段服务器会解析CQL语句并缓存:
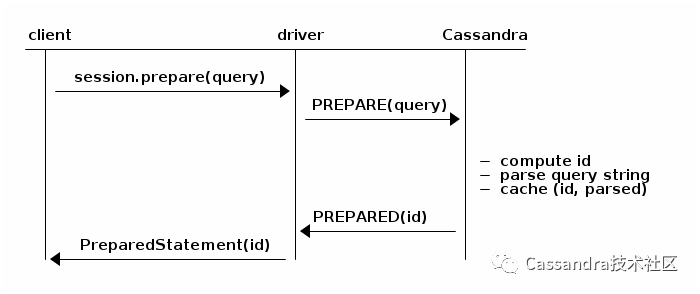
之后每次调用execute,服务器并不需要重新解析语句,而是从缓存中取出解析的结果来执行,因此减少了解析的时间:
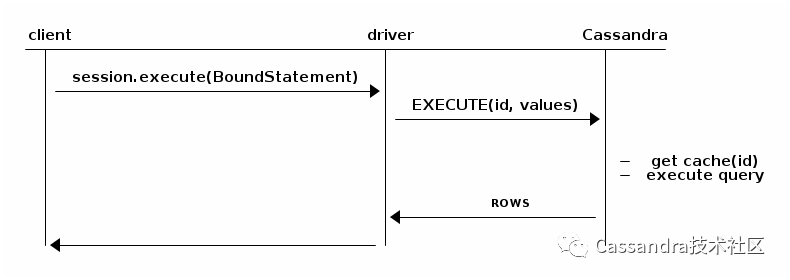
(3)BatchStatement
PreparedStatement preparedInsertExpense =session.prepare("INSERT INTO cyclist_expenses (cyclist_name, expense_id, amount, description, paid) "+ "VALUES (:name, :id, :amount, :description, :paid)");SimpleStatement simpleInsertBalance =new SimpleStatement("INSERT INTO cyclist_expenses (cyclist_name, balance) VALUES (?, 0) IF NOT EXISTS","Vera ADRIAN");BatchStatement batch = new BatchStatement(BatchStatement.Type.UNLOGGED).add(simpleInsertBalance).add(preparedInsertExpense.bind("Vera ADRIAN", 1, 7.95f, "Breakfast", false));session.execute(batch);
关于BatchStatement的原理和注意事项参见简析Cassandra的BATCH操作一文。
总结
•SimpleStatement适用于只执行一次(或几次)的语句•PreparedStatement适用于经常执行的语句,可以节省parse的时间•BatchStatement适用于有原子性要求的批量语句;或者对同一个partition key的批量操作。
异步API
异步API的示例如下:
import com.google.common.util.concurrent.*;ListenableFuture<Session> session = cluster.connectAsync();// Use transform with an AsyncFunction to chain an async operation after another:ListenableFuture<ResultSet> resultSet = Futures.transform(session,new AsyncFunction<Session, ResultSet>() {public ListenableFuture<ResultSet> apply(Session session) throws Exception {return session.executeAsync("select release_version from system.local");}});// Use transform with a simple Function to apply a synchronous computation on the result:ListenableFuture<String> version = Futures.transform(resultSet,new Function<ResultSet, String>() {public String apply(ResultSet rs) {return rs.one().getString("release_version");}});// Use a callback to perform an action once the future is complete:Futures.addCallback(version, new FutureCallback<String>() {public void onSuccess(String version) {System.out.printf("Cassandra version: %s%n", version);}public void onFailure(Throwable t) {System.out.printf("Failed to retrieve the version: %s%n",t.getMessage());}});
由于异步API不会阻塞应用执行,因此可以提高效率。异步API+TokenAwarePolicy配合使用可以实现很好的写入性能。
连接池
如下代码示例了如何配置连接池相关参数:
PoolingOptions poolingOptions = new PoolingOptions();poolingOptions.setConnectionsPerHost(HostDistance.LOCAL, 4, 10).setConnectionsPerHost(HostDistance.REMOTE, 2, 4);.setMaxRequestsPerConnection(HostDistance.LOCAL, 32768).setMaxRequestsPerConnection(HostDistance.REMOTE, 2000);Cluster cluster = Cluster.builder().withContactPoints("127.0.0.1").withPoolingOptions(poolingOptions).build();
和连接池有关的配置内容主要有以下这几个方面:
pool大小
pool大小的配置决定了和服务端每个host建立多少个连接。默认值为LOCAL hosts: core = max = 1,REMOTE hosts: core = max = 1。如果core != max,cassandra会根据负载情况动态调整连接数,具体的策略如下:
•若连接数n < max 且 并发请求数 > (n - 1) * maxRequestsPerConnection + NewConnectionThreshold,则新建连接•每10s执行一次清理。若n > core 且 需要的连接数 < n,则清理连接。需要的连接数由 实际请求数,maxRequestsPerConnection,NewConnectionThreshold三者共同决定。
可根据应用的实际负载情况适当调大CoreConnections/MaxConnections的值。NewConnectionThreshold一般情况下不需要配置。
maxRequestsPerConnection
这个配置项的含义是in flight(已发到服务器但还没收到响应)的最大请求数。超出这个配置的请求会排队或报错(取决于排队配置)。默认值为LOCAL hosts:1024,REMOTE hosts:256,还是比较小的,可以根据应用实际情况适当调大。
排队配置
主要包括MaxQueueSize和PoolTimeoutMillis。如果所有连接都在忙(超过maxRequestsPerConnection个请求),则新的请求会排队一段时间以等待连接可用,队列最大长度为MaxQueueSize,等待的最长时间为PoolTimeoutMillis。
另外,在生产环境上面如果需要监测连接池的使用情况,Driver里面也提供了Session.getState这个方法。
负载均衡策略
如下代码示例了如何配置负载均衡策略:
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").withLoadBalancingPolicy(new RoundRobinPolicy()).build();
负载均衡策略决定新的请求发往哪个coordinator,以及failover时选择哪个coordinator。默认的策略是new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build());
,表示会把请求尽量发到LOCAL节点,并切会根据token分布把请求发到数据对应的节点上面去。除默认策略外,其他策略还包括:
•RoundRobinPolicy•DCAwareRoundRobinPolicy•TokenAwarePolicy•LatencyAwarePolicy•WhiteListPolicy•HostFilterPolicy
重试策略
如下代码示例了如何配置重试策略:
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").withRetryPolicy(new MyCustomPolicy()).build();
如下这些重试行为是hard-code的,应用无法配置(实际上也没有理由要去配置……):
•网络实际写入发生前,有任何错误都会在另一个host上重试•prepared statement未编译,在同一个host上编译并重试•若节点处于bootstrapping状态,在另一个节点重试请求
默认策略:
•OnReadTimeout:如果收到足够多副本数的响应但没有读到数据,则在同一个host重试一次;其他情况直接抛异常。•onWriteTimeout:只在写batchlog失败时重试一次;其他情况抛异常。•onUnavailable:在其他host重试一次。•onRequestError:WriteFailure/ReadFailure不重试,客户端超时等请求错误会在其他host重试一次。
如果默认策略不满足需求,也可以通过实现RetryPolicy接口来自定义重试策略。
总结
可以看到,Cassandra不仅支持多种开发语言访问,而且客户端的设计兼顾了易用性和高性能,灵活而且高效,还提供了很多有用的特性可以根据应用的实际场景从服务端获取最大的性能。
写在最后
微信群邀约

公众号邀约

