




接上文
3.8情感分析(Sentiment Analysis)
情感分析通过研究用户的语句,将客户的情感分为正面、负面和中性。常见的情感分析方法有两种。
3.9文本分类
3.10用情感分析进行文本分类
0 很差
1 差
2 中等
3 好
4 很好
我们先来读取数据。首先引用“大熊猫”:Pandas
import pandas as pd
然后读取“电影评论的情感分析”的数据train.tsv
data=pd.read_csv('train.tsv', sep='\t')
我们来看一下数据的一部分
data.head()
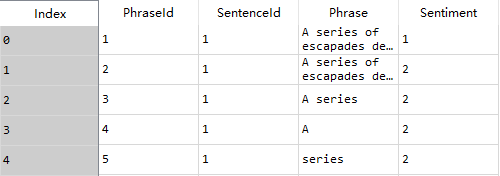
我们还可以看到更多Phrase里的内容。里面似乎还有一句谚语:what is good for the goose is good for the gander。这里goose 是雌鹅,gander是雄鹅。这句话直译就是说对雌鹅好的东西,对雄鹅也好。通常是指男人能拥有的或能做的,女人也能拥有或能做。也就是说男女平等。
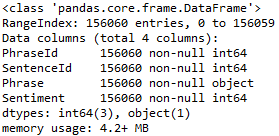
言归正传!我们来看一下数据的整体情况:
data.info()
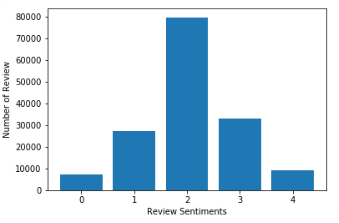
观众对这部电影评价最多的是2,也就是中等。评价为3和4的人数多于评价为1和0的人数。这说明观众对这部电影的看法是中等偏上。
data.Sentiment.value_counts()
2 79582
3 32927
1 27273
4 9206
0 7072
Name: Sentiment, dtype: int64
我们也可以通过图形来说明这个问题:
Sentiment_count=data.groupby('Sentiment').count()
plt.bar(Sentiment_count.index.values, Sentiment_count['Phrase'])
plt.xlabel('Review Sentiments')
plt.ylabel('Number of Review')
plt.show()
(未完待续)
