




/ 这是我的第215篇文章
达梦干货攻略
【Date:2021.07.01】

MY ARTICLE
在数据库的使用过程中,会用到大量的查询语句。为了节省时间和提高效率,对一些SQL进行调优是十分必要的。
在达梦数据库中,可以查看需要调整的SQL的执行计划并结合ET进行分析,来帮助寻找代价多的计划节点和操作符,指导我们进行SQL的优化。
GAN HUO
达梦的执行计划
执行计划就是一条SQL语句在数据库中的执行过程或者访问路径的描述
2、如何查看执行计划
在需要查看执行计划的SQL语句前加上EXPLAIN关键字,再执行该条SQL,即可查看它的执行计划;
在达梦的管理工具中,可以选中需要查看的SQL语句,按下F9键也可以查看它的执行计划。
3、如何解读达梦的执行计划

explain select * from E9.DOCDETAILLOG where id=37;
执行计划看起来就像一棵树,执行过程为:控制流从上向下传递,数据流从下向上传递。
(1)每个字段解读一下:
(2)解读该语句的执行计划的操作符:
(3)补充一些其他的常见操作符:
(4)解读该SQL的执行计划:
通过ID列上的二级索引,过滤符合条件的数据行,接下来二次扫描表需要查询的其他数据行,对查询结果进行投影和收集;
GAN HUO
达梦ET
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',1);SP_SET_PARA_VALUE(1,'MONITOR_TIME',1);
MONITOR_SQL_EXEC为会话级动态参数,可以设置只针对当前会话开启:
SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
执行SQL语句,我们会看到一个执行号,直接点这个执行号,即可调用ET;
在知道执行号的情况下,CALL ET(124571);也可以这样使用ET;
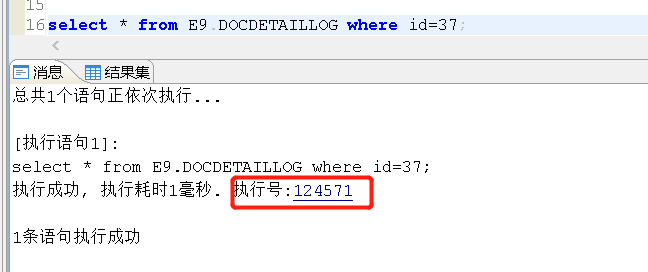
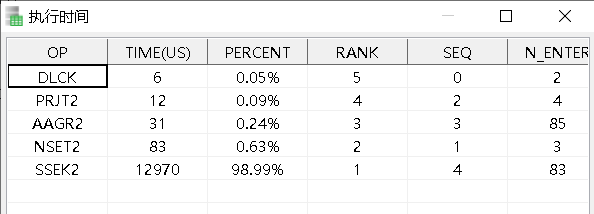
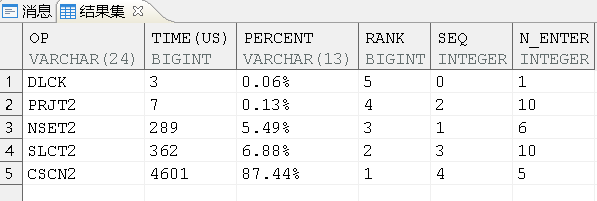
这条SQL的ET:
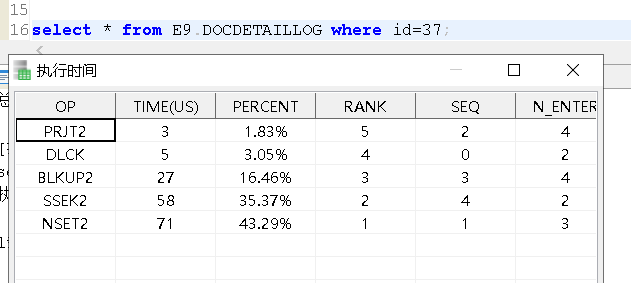
ET结果说明:
GAN HUO
1、案例一
select count(id)+1 from DocDetailLog where operatetype = 0 and docid =335;
(1)优化前的执行计划和ET
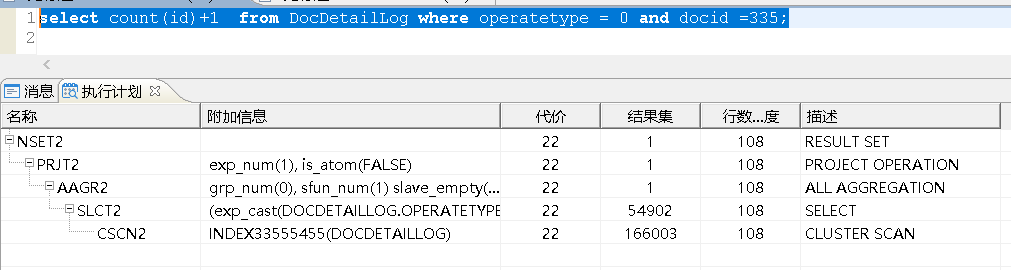
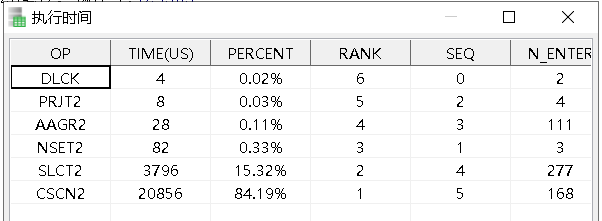
(2)优化过程:
select count(id)+1 from DocDetailLog where operatetype = 0 and docid =335;--81396select count(*) from DocDetailLog where operatetype = 0;--111823select count(*) from DocDetailLog where docid =335;--81396
create or REPLACE index idx_01 ON DocDetailLog(docid,operatetype);
创建索引后,收集统计信息:

重新查看执行计划:
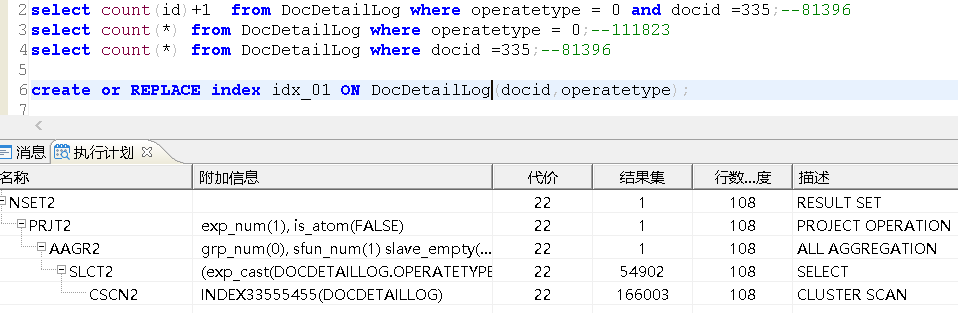
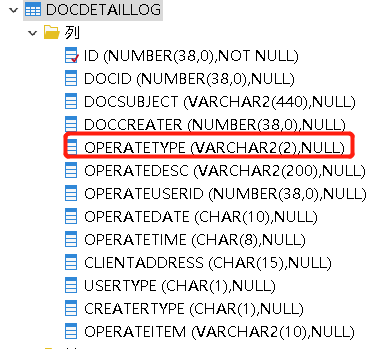
它是字符型的,在SQL中没有加单引号,发生了隐式转换,这样是不走索引的;
select count(id)+1 from DocDetailLog where operatetype = '0' and docid =335;--81396
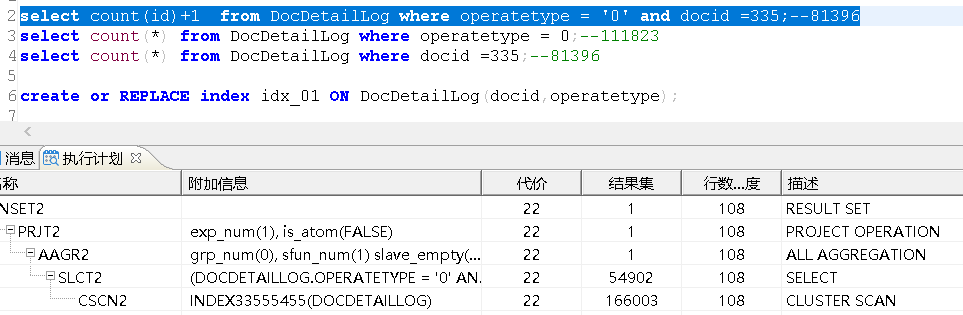
我们这里可以强制使用该索引,查看执行计划,可以看到使用索引的话,在查询ID列时,需要进行表的二次扫描,这样的代价比不使用索引更大:
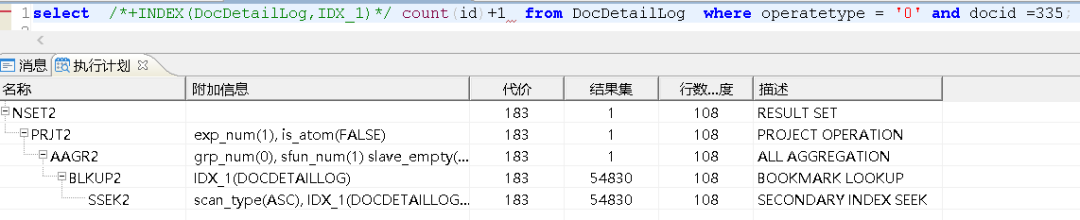
create or REPLACE index idx_01 ON DocDetailLog(docid,operatetype,id);
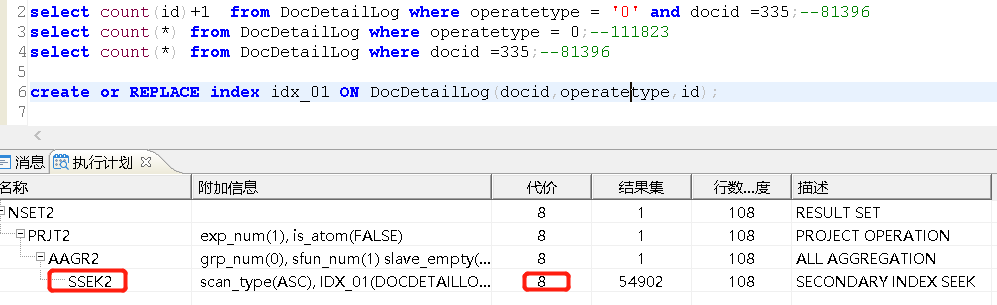
select * from "E9"."WORKFLOW_REQUESTBASE" where requestnamenew like '%zss%';
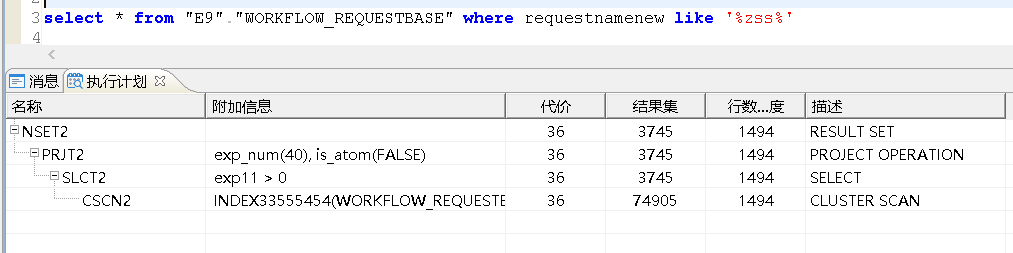
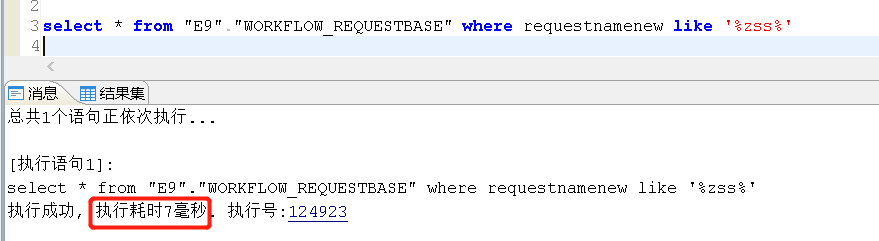
SP_SET_PARA_VALUE(1,'like_opt_flag',1);
create index idx_1 on "E9"."WORKFLOW_REQUESTBASE"(position('zss',requestnamenew));
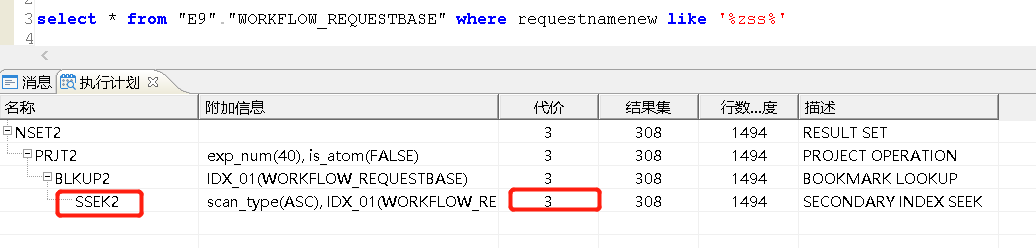
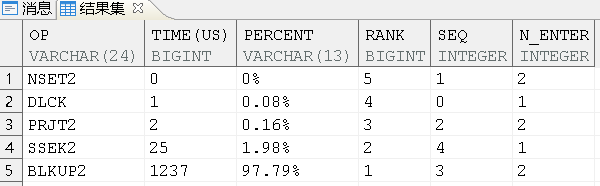
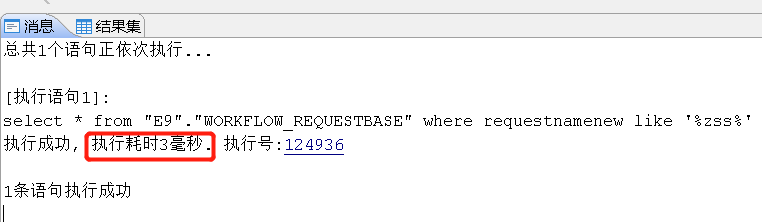
GAN HUO
1)达梦的执行计划和ET是SQL调优的高效工具;
2)创建联合索引时,要根据过滤性来选择,把过滤性好的放在前面;
等值和大于或者小于条件,要把等值条件放在前面;
往期干货回顾
【编辑】:王




