




最近为了配合Odoo这个开源ERP搞事情,需要使用PostgreSQL来支撑Odoo的后端数据存储(没得选,只能用PG)作为一套ERP,业务实时性不是非常高,但绝不接受数据丢失,出于预算(qiong)考虑,决定自建PG数据同步集群用于该项目。由此记下相关集群的配置操作记录。
集群拓扑
工程目标:实现PG数据库的高可用,具备快速主备切换的能力,且预留一个自读节点用于数据分析。
以下为三节点集群的简单拓扑图:
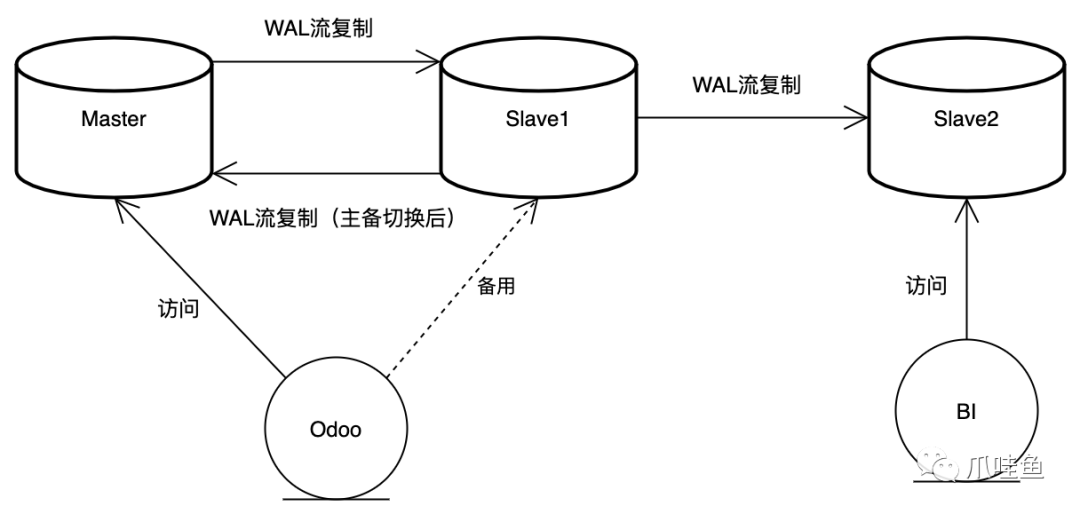
主节点与第一备节点互为主备,当主节点挂了,备节点可以接管业务,而第二备节点用于给BI部门用于数据分析。
基本原理
PostgreSQL的数据同步机制,有两种:
9.0版本开始的WAL(Write-Ahead Log)流复制(参考文档)
10.0版本开始的逻辑复制(参考文档)
根据项目的需要,每次只需要一个节点处于可读写状态即可,用WAL流复制即可实现需求,简单快捷又干净。
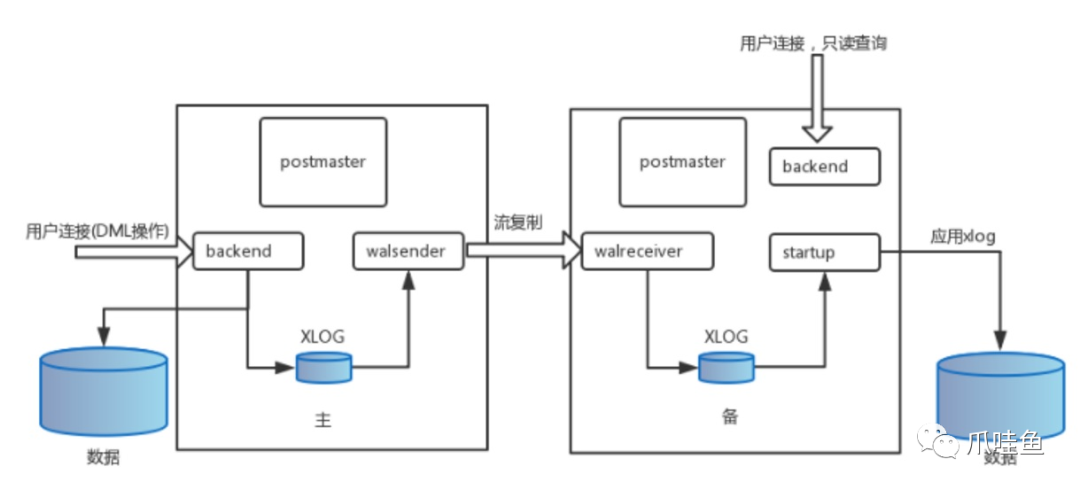
PG的WAL流复制机制源于9.0版本,在此之前做数据库同步都是使用日志文件传送复制,这样备节点上的数据版本会落后主节点一个日志文件。而流式复制的方式,是备库不断的从主库以WAL日志的record为单位同步相应的数据,并在备库apply每个WAL record。
下面是网上清晰描述WAL流复制拓扑图:
部署环境
节点网络环境:
主机名 | 角色 | IP |
PostgreSQL1 | 主节点 | 172.16.3.114 |
PostgreSQL2 | 备节点1 | 172.16.3.115 |
PostgreSQL3 | 备节点2 | 172.16.3.116 |
由于工程涉及的三个节点在未来将分布在不同网络区域,因此通过主机名的方式进行网络配置,在没有公开域名的情况下,需要将主机名配置在各节点的/etc/hosts文件中。
公共参数:
系统 | Debian 10 |
数据库用户 | postgres |
PG版本 | 11.12 |
数据目录($DATA_PATH) | /var/lib/postgresql/11/main |
配置目录($CONFIG_PATH) | /etc/postgresql/11/main/ |
关键配置文件
文件名 | 用途 |
$CONFIG_PATH/postgresql.conf | 数据库核心配置 |
$CONFIG_PATH/pg_hba.conf | 受信客户端配置(参考文档) |
$DATA_PATH/recovery.done | 主节点切换配置 |
$DATA_PATH/recovery.conf | 备节点切换配置(作为备机的时候,从哪个主节点获取数据) |
~/.pgpass | 备库访问主节点的密码文件 |
实施步骤
01
创建数据同步用的用户
在主节点数据库上新建用户(之后都是整体同步到备节点),用户名/密码:replica/replica:
CREATE ROLE replica login replication encrypted password 'replica'
02
配置pg_hba.conf
主节点(主要给1号备节点访问):
host replication replica PostgreSQL2 md5
1号备节点(既要在主节点恢复后给主节点访问,同时要给2号备节点访问):
host replication replica PostgreSQL1 md5
host replication replica PostgreSQL3 md5
2号备节点一直作为接收者,不需要新增pg_hba.conf配置
03
配置postgresql.conf
三个节点都实施:
listen_addresses = '*' //监听所有主机请求
max_connections = 100 //最大连接数,大家都懂
wal_level = replica //默认值是minimal,不够用,最低也需要replica
max_wal_senders = 10 //最大的wal传输进程数
wal_keep_segments = 64 //设置流复制保留的最多的xlog数目,设置大一点,否则备节点重连后发现xlog被覆盖了,就只能从归档恢复了
archive_mode = on //开启归档
archive_command = 'cp %p /var/lib/pgsql/pg_archive/%f' //归档命令,将数据复制到指定目录
full_page_writes = on //物理复制的时候全页复制,增加数据健壮性
wal_log_hints = on //同上,但不开也行
hot_standby = on //备机可读,如果不开,就没法做级联备份
#wal_receiver_timeout = 60s # time that receiver waits for
# communication from master
# in milliseconds; 0 disables
//用于网络断开超时时间,默认60秒
#wal_retrieve_retry_interval = 5s # time to wait before retrying to
# retrieve WAL after a failed attempt
//断开后重试间隔,默认5秒
//最后两个参数可以默认不动,反正PG的同步会自动重连就是了
04
创建归档目录(三节点都实施)
在配置中开启了归档,务必配置相关归档目录
mkdir -p /var/lib/pgsql/pg_archive
chown -R postgres:postgres /var/lib/pgsql/pg_archive
05
配置.pgpass(三节点都实施)
主要用于节点之间登录认证
su - postgres
vim ~/.pgpass
PostgreSQL1:5432:replication:replica:replica
PostgreSQL2:5432:replication:replica:replica
PostgreSQL3:5432:replication:replica:replica
06
配置recovery.done文件(主节点)
配置成为备机的后,Primary(主节点)的连接方式:
vim /var/lib/postgresql/11/main/recovery.done
standby_mode = on
primary_conninfo = 'host=PostgreSQL2 port=5432 user=replica password=replica'
recovery_target_timeline = 'latest'
07
数据目录权限确认
将数据目录的属主改成数据库用户postgres
chown -R postgres:postgres /var/lib/postgresql/11/main/
08
重启主节点服务
service postgresql restart
重启主节点数据库服务后,主节点配置完成。
09
备机基础数据同步与配置
在两台备机上停止PostgresSQL服务
service postgresql stop
在两台备机上清除所有数据目录下的数据
cd /var/lib/postgresql/11/main/
rm -fr *
从上游节点全量复制数据*(2号节点可以选择在1号节点配置完成后再从这个步骤开始配置)
pg_basebackup -h PostgreSQL1 -p 5432 -U replica -F p -P -D /var/lib/postgresql/11/main/
数据目录权限修改()
chown -R postgres:postgres /var/lib/postgresql/11/main/
1号备节点修改recovery.conf(基于主节点的recovery.done),与主节点互为主备
cd /var/lib/postgresql/11/main/
mv recovery.done recovery.conf //基于主节点配置修改
vim recovery.conf
standby_mode = on
primary_conninfo = 'host= PostgreSQL1 port=5432 user=replica password=replica'
recovery_target_timeline = 'latest'
启动1号备节点PostgresSQL服务
service postgresql start
2号备节点修改recovery.conf,以1号备节点为数据源
pg_basebackup -h PostgreSQL2 -p 5432 -U replica -F p -P -D /var/lib/postgresql/11/main/
启动2号备节点PostgresSQL服务
service postgresql start
10
验证同步进程
如无意外,三个节点可以看见对应的同步进程(ps -ef |grep postgres命令), walsender命令还会跟着备机的IP参数。
即使在pg_hba.conf是用主机名进行节点配置,备机在发起连接时,PG也会通过逆向DNS确认IP与主机名/域名的关系,最终通过相关IP与向备机发送WAL流。
主节点,在传出数据:
postgres 7452 249 0 Jun25 ? 00:01:48 postgres: 11/main: walsender replica 172.16.3.115(57272) streaming 0/F183A98
1号备节点,既输入,也传出数据:
postgres 5272 5142 0 Jun25 ? 00:06:01 postgres: 11/main: walreceiver streaming 0/F1853F8
postgres 5273 5142 0 Jun25 ? 00:01:46 postgres: 11/main: walsender replica 172.16.3.116(52920) streaming 0/F1853F8
2号备节点,只输入数据:
postgres 5331 251 0 Jun25 ? 00:06:01 postgres: 11/main: walreceiver streaming 0/F1870F0
各节点数据库可以用pg_is_in_recovery函数确认主备关系:
postgres=# select pg_is_in_recovery();pg_is_in_recovery-------------------f(1 row)
f代表主节点,t代表备节点
11
主备切换
模拟主节点挂掉(pg_ctl stop -m fast):
postgres@PostgreSQL-1:~$pg_ctl stop -m fast
waiting for server to shut down...... done
server stopped
主动用命令(pg_ctl promote)将备节点切换成主节点:
postgres@PostgreSQL-2:~$pg_ctl promote
waiting for server to promote..... done
server promoted
切换完成后,数据目录下的recovery.conf会变成recovery.done
将老的主节点配置成备节点并恢复:
将数据目录下的recovery.done改成recovery.conf
cd /var/lib/postgresql/11/main/
mv recovery.done recovery.conf
拉起旧的主节点(作为备机)
service postgresql start
按步骤10的方法验证一下同步进程,以及各节点库的主备关系。若要回切节点,就将步骤11在新的主备节点上操作一次即可。
PG在拉起数据库节点的时候,会根据数据目录下的recovery文件的后缀判断启动的节点身份,因此这个文件命名非常重要,要么是作为主节点的.done要么是作为备节点的.conf,可以有多台备机,但主节点只有一个,在将原备节点拉起的时候,务必确认文件名已经修改,避免数据脑裂。
