




1. ROW_NUMBER()
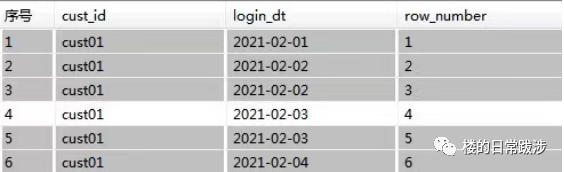
row_number会为查询出来的每一行记录生成一个序号,依次顺序排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
-- row_number() 顺序排序
select
Cust_Id,
Login_Dt,
row_number() over (partition by Cust_Id order by Login_Dt asc) as row_number
from cust_login_inf;
2. RANK()
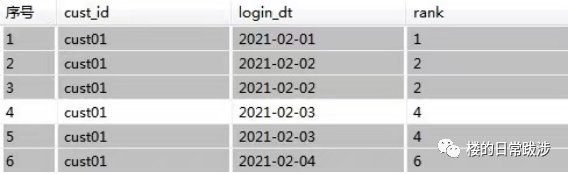
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。rank与row_number函数不同的是,rank函数考虑到over子句中排序字段值相同的情况,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
-- rank() 跳跃排序,如果有两个第二级别时,接下来是第四级别
select
Cust_Id,
Login_Dt,
rank() over (partition by Cust_Id order by Login_Dt asc) as rank
from cust_login_inf;
3. DENSE_RANK()
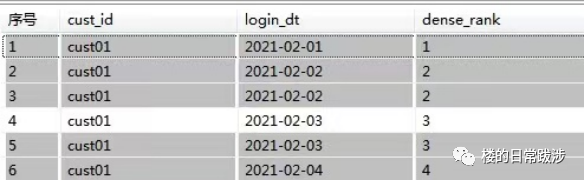
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
-- dense_rank() 跳跃排序,如果有两个第二级别时,接下来是第三级别
select
Cust_Id,
Login_Dt,
dense_rank() over (partition by Cust_Id order by Login_Dt asc) as dense_rank
from cust_login_inf;
关于Partition by:
Parttion by关键字是数据库分析性函数的一部分,用于给结果集进行分区。它和聚合函数Group by不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而Group by是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。
TIPS:
使用rank over()的时候,空值是最大的,如果排序字段为null, 可能造成null字段排在最前面,影响排序结果。
可以这样:rank() over(partition by student order by score desc nulls last)
总结:
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序。
4、rank中空值是最大的,要用 nulls last进行调整。
一、近七天中连续三天都登陆的用户
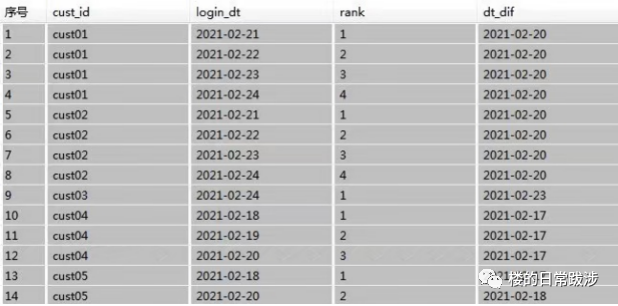
1.1 查询出近7天的登陆用户,并对用户登陆日期进行排名;
1.2 计算用户登陆日期和排名之间的差值;
-- rank() 和date_sub() 的使用
select
Cust_Id,
Login_Dt,
Rank,
date_sub(Login_Dt,Rank) as Dt_Dif --1.2
from
(
select
Cust_Id,
Login_Dt,
rank() over (partition by Cust_Id order by Login_Dt asc) as Rank --1.1
from cust_login_inf
where Login_Dt >=date_sub('2021-02-24',6) and Login_Dt<='2021-02-24'
)t1
;
2.1 对同用户及差值进行分组,统计差值个数;
2.2 取出差值个数大于等于3的数据;
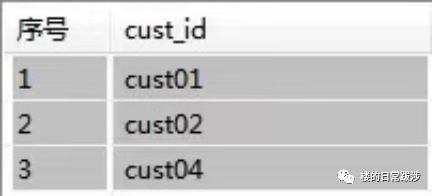
2.3 对数据去重;
-- count() 和group by 的使用
select
Cust_Id
from
(
Select
Cust_Id
from
(
select
Cust_Id,
date_sub(Login_Dt,Rank) as Dt_Dif --1.2
from
(
select
Cust_Id,
Login_Dt,
rank() over (partition by Cust_Id order by Login_Dt asc) as Rank --1.1
from cust_login_inf
where Login_Dt >=date_sub('2021-02-24',6) and Login_Dt<='2021-02-24'
)t1
)t2
group by Cust_Id,Dt_Dif --2.1
having count(*)>=3 --2.2
)t3
group by Cust_Id --2.3
;
二、部门平均薪水
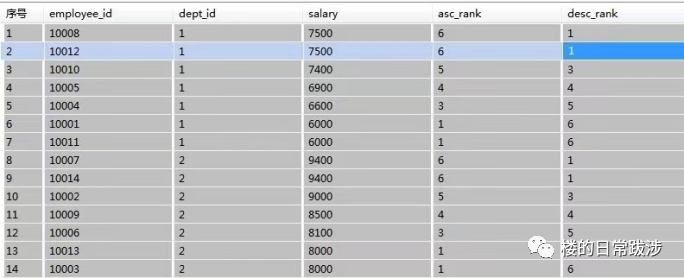
1. 剔除每个部门最高、最低薪水的雇员数据
-- rank() 和group by 的使用
select
Employee_Id,
Dept_Id,
Salary
from
(
Select
Employee_Id,
Dept_Id,
Salary,
rank() over (partition by Dept_Id order by Salary asc) as Asc_Rank,
rank() over (partition by Dept_Id order by Salary desc) as Desc_Rank
from SALARY_TABLE
)t1
where Asc_Rank > 1 and Desc_Rank > 1
;
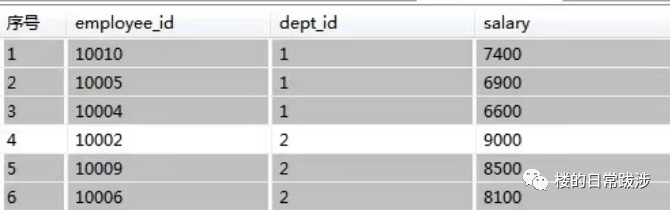
2. 求每个部门雇员的平均薪水,保留整数
-- avg() 和cast() 的使用
select
Dept_Id,
cast(avg(Salary) as int) as Avg_Salary
from
(
select
Employee_Id,
Dept_Id,
Salary
from
(
select
Employee_Id,
Dept_Id,
Salary,
rank() over (partition by Dept_Id order by Salary asc) as Asc_Rank,
rank() over (partition by Dept_Id order by Salary desc) as Desc_Rank
from SALARY_TABLE
)t1
where Asc_Rank > 1 and Desc_Rank > 1
)t2
group by Dept_Id
;

参考:
https://www.cnblogs.com/hzjl/p/10518558.html
