




本文主要介绍阿里云数据库团队在今年sigmod上发表的两篇论文。
LogStore: A Cloud-Native and Multi-Tenant Log Database
目前,越来越多的企业在云上部署应用。为保证应用能够安全、高效、稳定的运行,对客户来说,log的获取至关重要,一方面,客户可以根据log进行性能诊断等,另一方面,客户能够分析log信息执行商业决策。因而,对云厂商来说,构建一个cost-effective的日志存储和分析系统,为用户提供高效的的log服务是一项非常重要的工作。
挑战
· 极高的写吞吐率以及存储容量
· 多租户访问以及高度倾斜的负载
· 海量数据的快速检索需求
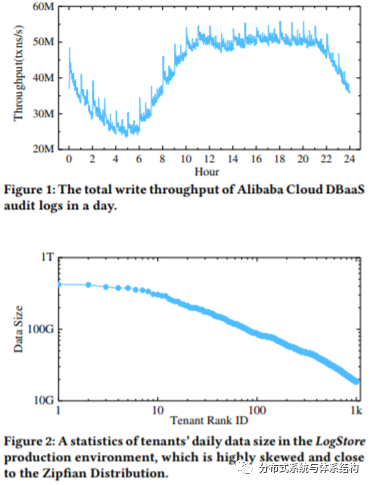
因此,针对上述问题,本文提出了一种云原生、多租户log数据库LogStore。LogStore采用了shared-nothing和shared-data的混合架构,目的在于利用两者的优势,满足对低响应延迟以及高吞吐率的需求,主要设计如下:
· 存储与计算分离架构;
· 可扩展的读与写:可以根据租户需求,将log数据partition到不同的计算节点;
· 实时和低延迟写:将数据持久化到本地 disk,并在local节点上维护三副本,利用raft协议保证高可用,这里采取的是share-nothing的架构。在LogStore中采用了面向写优化的row-oriented 存储格式;
· 低开销和读优化存储:考虑到在本地disk上的高存储成本,LogStore采用了share-data的架构,即将数据放在对象存储OSS上,并采用了面向读优化的column-oriented存储格式;
· 动态调度资源:由于租户对资源的需求不一致,因此动态的资源调度策略能够最大化资源利用率。另外由于存在节点是异构的,因而动态的负载均衡策略同样重要。
下面的内容将会对以上内容展开具体的介绍。
LogStore架构
LogStore主要包括以下关键组件:Controller、Query Layer、Execution Layer。
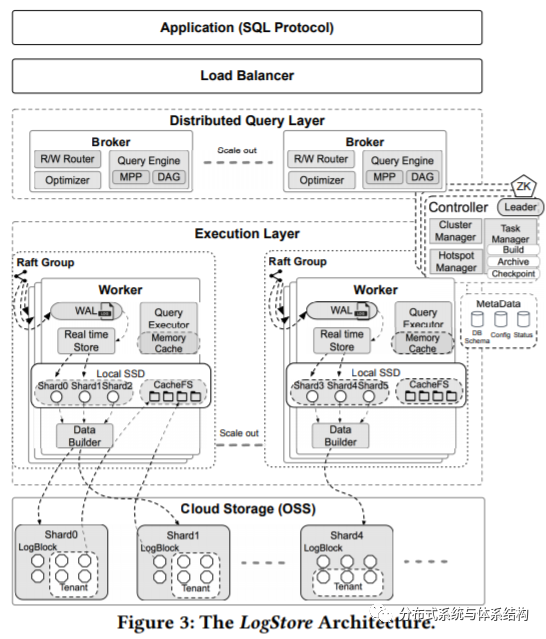
Controller
controller负责管理整个系统,提供集群监控、元数据管理、任务调度等功能。为保证高可用,部署了包含三个节点的zookeeper集群,但一个时刻只有一个节点提供服务。controller中维护的有router table,用来制定路由规则。
· 监控组件,收集它们运行时的状态;
· 当检测到异常节点时,controller从router table中移除该节点,并在后续执行节点recovery操作;
· controller管理数据库的schema,保证其一致性;
· 当执行DDL操作时,controller更新catalog并将其同步更新到每个broker;
· controller周期的执行后台操作,比如checkpoint和GC。
Query Layer
在QueryLayer中存在多个broker,负责处理SQL请求,Load Balancer将请求分配到相应的broker,broker对SQL进行解析和优化,最后生成相应的查询计划(DAG)。根据cotroller提供的routertable的规则,broker将子请求分配到相应的shard,之后将每个shard中的结果进行merge,并将最终的结果返回给客户端。
注:routertable中的规则是controller根据全局流量控制算法进行设计的,因而可以降低倾斜负载以及热点问题带来的影响,后面将会介绍。
Execution Layer
在该层中,包含一系列的worker,controller将不同的shard分配到worker上,每个worker的负责相应shard的读写请求。该层维护了一个row-column混合的数据格式(本地磁盘上维护了行存,对象存储上维护了列存),并采用了两阶段的写操作:1.执行本地写2.将本地磁盘上的行存转换成列存结构LogBlocks,并上传到对象存储上。为了降低读延迟,每个worker上使用了多层缓存结构。
Multi-Tenant Storage
目前多租户的数据管理方式主要有两种:
1. 为每个租户建立专用的存储集群->良好的隔离性,但是成本较高;
2. 所有租户的数据共享存储,为它们建立一个大表->成本较低,但由于隔离性较差,但由于不同租户的数据混合在一起,访问数据时也会加载到其他租户的数据,导致高的访问延迟。
在LogStore中,兼顾成本与隔离性,采用了混合的方式:
· 在行存架构,即在本地磁盘中,将日志数据存储在一个单独的大表中,并以时间戳管理,目的在于提高空间利用率以及减少随机IO。
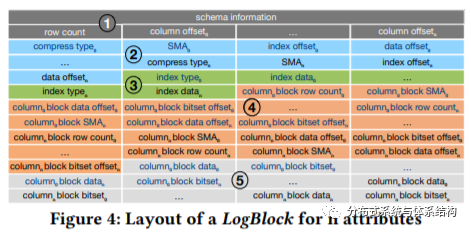
· 之后,data builder将行存转换成列存LogBlock,LogBlock类似于Lucene,为所有的列创建反向索引,LogBlock的结构如下图所示。该在此过程中,根据租户将行存表划分给不同的租户,controller会更新租户的相关元数据信息。
Load Balancing
如上述提到的,由于负载倾斜性以及ECS节点的异构性(性能不一致)等,会导致租户之间的负载不均衡,因而如何实现动态的负载均衡对提升系统的性能以及资源的利用率十分关键。为解决上述问题,LogStore提出了全局流量控制算法在router table中指定相应的规则,以解决负载均衡问题。Server Load Balancer将租户的请求分配给broker,controller将router table push到broker上,broker根据路由规则将请求分配到相应的shard,规则的格式如下所示:

路由表规则由controller的hotspot scheduler负责管理,并对其实时的更新。从下图可以看出,hotspot scheduler由Monitor、Balancer和Router组成:
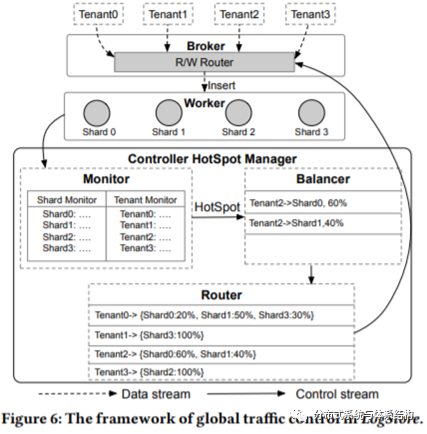
· Monitor:负责识别热点,比如根据CPU的使用率;
· Balancer:当热点被识别后,Balancer用于生成新的调度计划以实现负载均衡,并将路由表的更新发送给ExecutionLayer的worker。本文实现了两种调度算法:GreedyAlgorithm和Max Flow Algorithm, 具体的实现算法伪码可以看文章,写的比较清晰;
· Router:更新路由表,并更新每个broker上的路由表。
Backpressure flow control
尽管本文提出了负载均衡等机制,由于会出现内存瞬间吃满或者CPU使用率瞬间拉满的情况,会直接导致系统crash。
为解决以上问题,本文提出了backpressure flow control(BFC)机制。在LogStore中,存在多个buffer queue来保证组件间可以异步的交互。基于此,本文提出的BFC通过监控buffer queue的状态来解决上述问题。具体步骤如下:
· 监控每个queue中挂起请求的数目和请求的size;
· 当超过 queue的限制时,触发BFC机制;
· 根据BFC机制,拒绝接受该请求。
Query Optimazation
由于日志主要存储在OSS中,会引起较大的查询延迟。为解决以上问题,本文主要采用了data skipping和multi-level data cache 策略。
· Data Skipping:根据LogBlock的small materialized aggregates(SMA),即该物化结构里面的最大最小值,过滤掉不相关的内容。
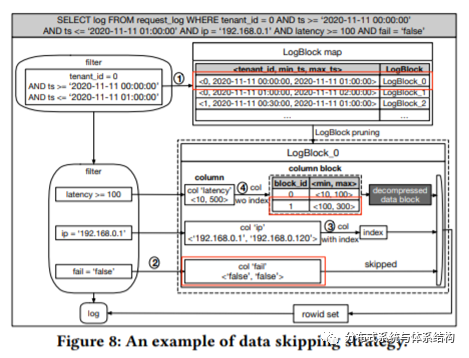
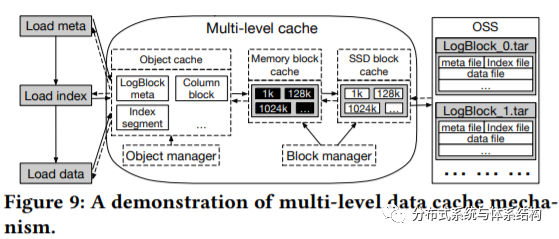
· multi-level data cache :通过缓存与预测策略,降低访问延迟,具体设计如下图所示。为了小文件管理引起的复杂度,LogStore将小文件打包成tar文件。同时为避免读取到不相关的数据,Logstore允许对其中的每个小文件进行单独的访问。从下图可以看出,LogStore中使用了多级缓存,当从OSS中读取数据时,首先会将数据存储到Memory block cache,当Memory block cache满时,将其替换到SSD block cace中,block manager负责管理两者之间的交互。另外,LogStore中也维护了object memory cache,主要目的在于减少频繁的对象分配。为提高查找性能,本文也设计了并行预取策略。
总结
本文介绍了阿里云的云原生日志数据库LogStore,为解决写倾斜以及流量震荡问题,提出了全局流程控制算法;同时提出了列存LogBlock结构,并通过data skip 和parallel prefetch策略降低访问延迟。
PolarDB Serverless: A Cloud Native Database forDisaggregated Data Centers
PolarDB的是阿里云推出的云原生分布式数据库,采用了存储与计算分离的架构,但是和其他的存算分离架构一样,cpu和内存仍然是紧耦合的,导致资源扩展上仍然受到限制。
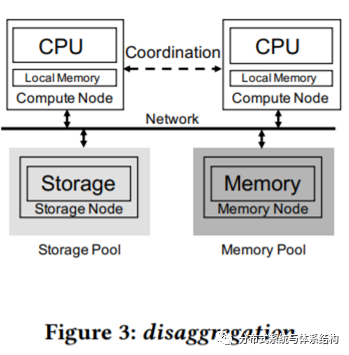
为了解决上述问题,本文提出了新一代的云原生数据库PolarDB Serverless,将计算、内存、存储分别进行池化,实现了cpu与内存的解耦。
PolarDB Serverless架构
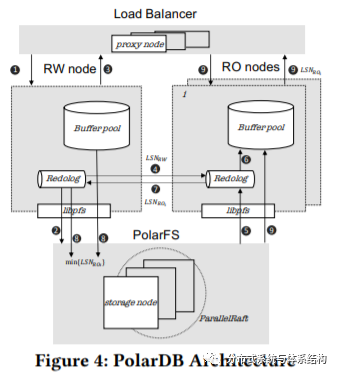
如图3所示,PolarDB Serverless维护了一个远程内存池,并通过RDMA进行访问。和PolarDB一样(图4),在PolarDBServerless中,仍然只有一个RW节点以及多个RO节点,并通过PolarFS访问存储池。
PolarDB Serverless优点:
· 内存可以共享,因而可以提升内存利用率;
· 内存支持水平扩展。
缺点:
· 相比本地内存,读延迟较大->采用缓存以及预测策略
· 由于内存是共享的,多节点访问会引起数据一致性问题,然而维护一致性的锁机制会导致性能下降->使用 one-sided RDMA CAS和乐观锁避免全局加锁
· 页面传输会引起较大的延迟->只写redo log,并异步的进行物化操作
Disaggregated Memory
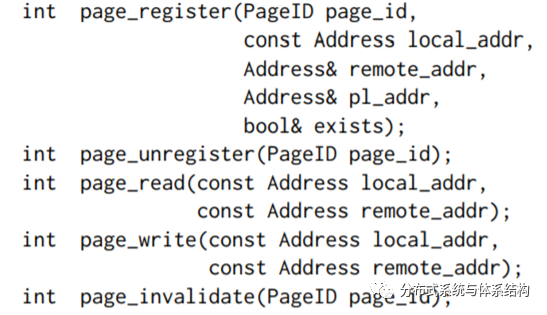
Poalrdb通过librmem访问内存池,librmem有五个重要的接口,如下图所示。
Page根据page_id进行识别,并通过page_register 和page_unregister管理page。page_register表示申请该page,引用加1,page_unregister表示释放,引用减1,当count为0时,表示该page被删除;page_read将page从内存池中读到本地内存中;page_write将page从本地内存中写到内存池中,以上过程都是通过one-sided RDMA 执行。.page_invalidate将所有RO节点中的本地内存的该page置为无效。
在本文中,内存分配的单元是slab,其大小为1GB。slab的基本结构是Page Array (PA),每个PA是16KB的连续内存块。slab所在的内存节点成为slab node,slab node保存了多个slab。在本文中,第一个slab所在的slabnode称为home node,home node用来确定一个page是否在PAT中。
· Page Address Table (PAT) 是一个hashtable,记录slab node id和对应的物理内存地址。通过查找PAT,可以确定是否page在该PAT中。
· Page Invalidation Bitmap(PIB)是一个bitmap,0表示该page是最新的版本,1表示RWnode还没有将脏数据写回。在每个RO node上,也有PIB,用来指示在本地cache中的page是否过期;
· Page Reference Directory (PRD):PRD是一个映射表,里面保存的是PAT中每个entry(page)的引用数;
· Page Latch Table (PLT):PLT为每个PAT中的entry提供PL,PL是个全局锁,用来保证数据一致性。
page分配的具体流程:
1. 调用page_register接口,根据home node,查找page是否在PAT中,如果没有,home node则对所有的slab进行扫描,则根据贪心算法选择slab中空闲空间最大的page,如果所有的slab都没有空闲空间,则根据LRU算法执行替换策略;
2. home node更新PAT,并返回page的地址以及相应的PL给调用者;
在上述过程中,为防止进程被阻塞,后台线程周期性的执行替换策略保证slab node有空闲的page可供使用。
Cache Coherency
由于昂贵的网络开销,PolarDB Serverless不会直接访问访问远程内存或者执行in-place更新。PolarDB Serverless将远程内存池中的数据首先读取到本地cache中,之后在本地cache中对page进行管理。如果访问的page不在remote memory中时,PolarDB Serverless通过libpfs接口从PolarFS将相应的数据读取到本地cache中,之后将page写到remote memory中(注:但不是每种情况都需要写到remote memory,一些之后不会使用的数据不需要执行该操作,比如全表扫描)。当本地cache满时,根据LRU执行执行缓存替换操作,并将替换出的内容写回到remote memory中。
由于在本地cache中的脏数据可能还未写回到remote memory中,并且由于remote memory是共享的,因而当RO节点访问时,会引起数据不一致问题。为解决这个问题,本文提出了cache invalidation策略,即当RW node的节点执行更新操作时,所有其他RO node的本地cache都被置为无效。如图6所示,当RW node在本地cache中更新某个page时,cache invalidation的具体流程如下:
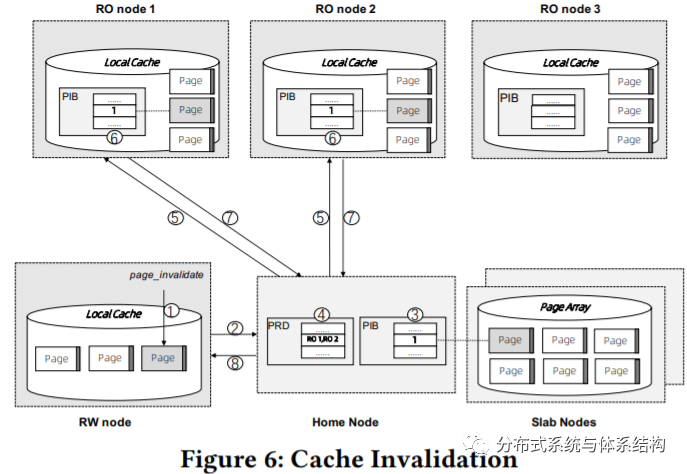
1. 设置RW node上的PIB;
2. 调用page_invalidate;
3. 设置Home node上的PIB;
4. 查找PRD,获取保存该副本的RO node;
56.设置RO node的PIB;
78. 当所有的node都设置成功之后,返回;
可以看出,page_invalidate是同步操作,在此过程中,如果超时之后,RO node仍然没有响应,则将其从集群中移除。
B+Tree’s Structural Consistency
在PolarDBServerless中,由于只有RW node能写入数据,因而没有写冲突的问题。但是在调整多个page时,RO node可能会访问到不一致的数据,以分裂操作为例:
B+ Tree的叶节点A分裂成A1和A2,A1是原节点,A2是新节点,之后将相关的index信息传递到父节点B,节点B
被更新为B1。
当RO node访问时,有可能节点A的分裂信息没有传递到父节点上,因而RO node会读到原节点B
的信息,但是它会读到分裂之后的A1。由于A2的信息没有被访问到,因此读到了不一致的数据。
为解决上述问题,本文使用了PL机制,它是一个全局latch,有S和X两种模式,即共享与互斥。
在进行读操作时,首先在父节点B上加上S锁,之后在节点A上加S锁,最后把节点B的latch释放掉。
在进行插入或则删除操作时,首先执行遍历查找相应的key,如果没有Structure Modification Operation(SMO)操作,可以直接在叶子节点上执行相应的插入或者删除操作;否则重新执行该操作,RWnode在父节点B上加X锁,之后在节点A上加X锁,当分裂操作完成只有,latch才能释放。
为了降低加锁带来的开销,PL并不会立刻释放锁,也就是本文提出的stickness策略。目的在于由于持有锁,RO node不需要再次向PLT请求锁,可以减少锁管理带来的开销。在本文中,通过RDMA CAS加速锁申请。
Snapshot Isolation
在RWnode中维护了一个CTS(中心时间戳,单调递增的),负责为事务分配时间戳,包括cts_read和cts_commit,PolarDBServerless通过MVCC提供SI。
在PolarDBServerless中,为减少随机写,cts_commit并不是立即更新,而是在后台异步的更新。然而,以上情况导致读取到过期的数据。为解决以上问题,本文维护了CTS Log结构,它是一个环形数组,记录了最新事务的cts_commit。如果事务没有提交,对应的值为null。当RO node读取数据时,如果该事务对应的cts_commit是miss的,则从CTSLog进行查找,从而确定其是否已经提交。
为降低以上操作带来的开销,本文使用了one-sided RDMA的语义对以上操作进行优化。比如CTS的时间戳计数器使用RDMA CAS进行更新等。
Page Materialization Offloading
区别于PolarDB ,在PolarDB Serverless中,将log和page分开存储在两种不同类型的chunk中,即log chunk和page chunk。Redo log首先被持久化到log chunk中,并异步的发送到page chunk。为了能够减少对PolarFS的修改,PolarDB Serverless仅将log发送给page chunk中的leader node,leader node根据ParallelRaft将更新发送给其他副本node。
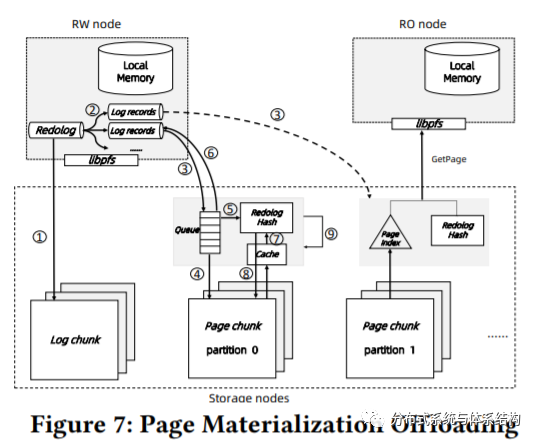
RW node将redo log刷到log chunk,当写三副本成功之后,事务可以被commit。
1. 将redo log写入到log chunk
2. log chunk中的log发送到pagechunk
3. RW节点将log发送给page chunk的leader
4. 将收到的log持久化到page chunk中
5. 更新hashtable,将page id作为key插入到该表中
6. 当完成后,响应给RW节点
7. 从cache或者磁盘磁盘中读取该page的老版本,并与hashtable中的log执行merge操作
8. 将merge之后的数据写入到其他副本
9. 在后台执行GC操作,回收老版本
Auto-Scaling
为保证在scale时服务不被中断,维护了一个proxy node , proxy node是无状态的,proxy node 用户保证客户端连接正常。在执行在线升级等操作时,proxy node会暂停正在活动的事务,并将后续操作转发给old RW节点,当old RW节点完成后续的操作时,将所有的脏页刷到共享内存中并关闭。这时,新的RW节点连接到共享内存,并初始化其本地memory的状态;最后proxy node连接到新的RW节点,恢复会话状态,最后转发挂起的语句到该节点上并执行。
Reliability and Failure Recovery
在PolarDBServerless中,由于采用了分离的架构,因此不同类型的节点可以独立实现容错。PolarDBServerles为每个storage节点维护多个副本,副本之间通过Parallel Raft保障一致性。当Memory节点发生故障时,可以从storage节点恢复。为保证Database节点故障一致性恢复,使用了ARIES机制。
总结
本文提出了基于分布式内存的云原生数据库系统PolarDB Serverless,PolarDB Serverless将计算与内存资源解耦,极大的提升了PolarDB的扩展能力。
