




前言
现FlinkSQL支持的连接如下
| Name | Version | Source | Sink |
|---|---|---|---|
| Filesystem | Bounded and Unbounded Scan, Lookup | Streaming Sink, Batch Sink | |
| Elasticsearch | 6.x & 7.x | Not supported | Streaming Sink, Batch Sink |
| Apache Kafka | 0.10+ | Unbounded Scan | Streaming Sink, Batch Sink |
| Amazon Kinesis Data Streams | Unbounded Scan | Streaming Sink | |
| JDBC | Bounded Scan, Lookup | Streaming Sink, Batch Sink | |
| Apache HBase | 1.4.x & 2.2.x | Bounded Scan, Lookup | Streaming Sink, Batch Sink |
| Apache Hive | Supported Versions | Unbounded Scan, Bounded Scan, Lookup | Streaming Sink, Batch Sink |
然而在实际开发过程中,应对不同的场景和不同公司的开发需求,这需要你自己定义数据源或者数据落脚点
Kudu sink(别的sink以此为例)
1.继承一个RichSinkFunction
package com.wang.kudu;
import com.wang.util.ConfigOptions;
import com.wang.util.KUDUUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.table.connector.sink.DynamicTableSink.DataStructureConverter;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.Row;
import org.apache.kudu.client.KuduClient;
import java.util.*;
/**
* @Desc 具体实现类
* @Author wang bo
* @Date 2021/5/24 15:49
*/
public class KuduSinkFunction extends RichSinkFunction<RowData> {
private final DataStructureConverter converter;
private final ReadableConfig options;
private final DataType type;
private KuduClient connection;
public KuduSinkFunction(
DataStructureConverter converter, ReadableConfig options, DataType type) {
this.converter = converter;
this.options = options;
this.type = type;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = KUDUUtil.getConnection();
}
@Override
public void invoke(RowData rowData, Context context) throws Exception {
// RowKind rowKind = rowData.getRowKind();
// if (rowKind.equals(RowKind.UPDATE_AFTER) || rowKind.equals(RowKind.INSERT))
Row data = (Row) converter.toExternal(rowData);
Set<String> fieldNames = data.getFieldNames(true);
Map<String, Object> value =new HashMap<>();
String dataBase = options.get(ConfigOptions.DATA_BASE);
String tableName = options.get(ConfigOptions.TABLE_NAME);
for (String fieldName : fieldNames) {
Object fieldValue = data.getField(fieldName);
value.put(fieldName,fieldValue);
}
if(!value.isEmpty()){
KUDUUtil.operateRows("upsert",connection,"impala::"+dataBase+"."+tableName, Arrays.asList(value));
}
}
@Override
public void close() throws Exception {
super.close();
}
}
2.实现一个DynamicTableSink
package com.wang.kudu;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.sink.SinkFunctionProvider;
import org.apache.flink.table.types.DataType;
/**
* @Desc
* @Author wang bo
* @Date 2021/5/24 15:39
*/
public class KuduSink implements DynamicTableSink {
private final DataType type;
private final ReadableConfig options;
public KuduSink(DataType type, ReadableConfig options){
this.type=type;
this.options=options;
}
@Override
public ChangelogMode getChangelogMode(ChangelogMode changelogMode) {
return changelogMode;
}
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
DataStructureConverter converter = context.createDataStructureConverter(type);
return SinkFunctionProvider.of(new KuduSinkFunction(converter,options,type));
}
@Override
public DynamicTableSink copy() {
return null;
}
@Override
public String asSummaryString() {
return null;
}
}
3.配置信息
package com.wang.util;
import org.apache.flink.configuration.ConfigOption;
import static org.apache.flink.configuration.ConfigOptions.key;
/**
* @Desc
* @Author wang bo
* @Date 2021/5/24 17:37
*/
public class ConfigOptions {
public static final ConfigOption<String> HOST_PORT = key("hostPort")
.stringType()
.noDefaultValue()
.withDescription("kudu host and port,");
public static final ConfigOption<String> TABLE_NAME = key("tableName")
.stringType()
.noDefaultValue()
.withDescription("table,");
public static final ConfigOption<String> DATA_BASE = key("dataBase")
.stringType()
.noDefaultValue()
.withDescription("database,");
}
4.实现一个DynamicTableSinkFactory
package com.wang.kudu;
import com.wang.util.ConfigOptions;
import org.apache.flink.annotation.Internal;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.factories.DynamicTableSinkFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import java.util.HashSet;
import java.util.Set;
/**
* @Desc
* @Author wang bo
* @Date 2021/5/24 15:35
*/
@Internal
public class KuduFactory implements DynamicTableSinkFactory {
public static final String IDENTIFIER = "kudu";
public KuduFactory(){}
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
return new KuduSink(
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType(),
options
);
}
@Override
public String factoryIdentifier() {
return IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
return new HashSet<>();
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> options = new HashSet<>();
options.add(ConfigOptions.HOST_PORT);
options.add(ConfigOptions.DATA_BASE);
options.add(ConfigOptions.TABLE_NAME);
return options;
}
}
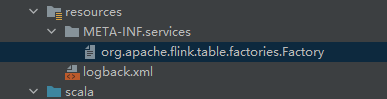
6.添加resources
需要在resources新建META-INF.services/org.apache.flink.table.factories.Factory文件 不然会报错 内容:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
com.wang.kudu.KuduFactory
7.测试
def fromCSVToKUDU(): Unit = {
val sql_csv =
"""
|CREATE TABLE test_something (
| id BIGINT,
| order_number STRING,
| app_code STRING
|) WITH (
| 'connector' = 'filesystem',
| 'path' = 'D:\idea_project\study\input\something.csv',
| 'format' = 'csv'
|)
|""".stripMargin
tableBatchEnv.executeSql(sql_csv)
val sql_kudu =
"""
|CREATE TABLE test_flink (
| id BIGINT,
| order_number STRING,
| app_code STRING
|) WITH (
| 'connector' = 'kudu',
| 'hostPort' = 'xxxx:7051,xxxx:7051,xxxx:7051',
| 'dataBase' = 'default',
| 'tableName' = 'test_flink'
|)
|""".stripMargin
tableBatchEnv.executeSql(sql_kudu)
tableBatchEnv.executeSql("insert into test_flink select * from test_something")
}
至此,去kudu表查询一些,数据已经进入kudu表
总结
小试牛刀,继续学习。同学共进~~~
文章转载自大数据左右手,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
