




目录
namespace
network namespace
Linux虚拟网络设备
tap/tun
bridge
macvlan
macvtap
veth-pair
namespace
namespace本质上是对系统资源的隔离。
Linux内核提供了namespace的6种系统调用。
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
通过不同的API来进行不同资源的隔离。
network namespace
network namespace主要提供了关于网络资源的隔离,包括网络设备、IPV4和IPV6协议栈、IP路由表、防火墙、/proc/net 目录、/sys/class/net 目录、套接字(socket)等。一个物理的网络设备最多存在于一个network namespace中,我们可以借助创建虚拟bridge(网桥or交换机)、veth-pair(虚拟网络设备对,类似管道)在不同的network namespace间创建通道,以此达到网络通信的目的。
一般情况下物理网络设备都分配在最初的root namespace(系统默认的)中,但如果有多块物理网卡,也可以把其中的一块或多块分配给新建的network namespace。要注意的是,当新创建的network namespace被释放时(所有内部的进程都终止并且namespace文件没有被挂载或打开),在这个namespace中的物理网卡回返回到root namespace,而非创建该进程的父进程的network namespace
在之前的文章Docker干货中稍微提到了几种Docker容器网络驱动的方式,
host驱动可以让容器与宿主机共用一个网络栈,用起来很方便,但实际上并未使用network namespace进行网络隔离,缺乏安全性,生产环境基本不可能使用(个人还是可以用用的,毕竟简单方便哈哈哈) 使用Docker默认的bridge驱动,容器木有对外IP,只能通过NAT来实现对外通信,这种方式是单机使用最多的,但是并不能解决跨主机容器间直接通信的问题,复杂一点的场景就gg 使用overlay驱动,可以支持跨主机的网络通信,配套Swarm使用 使用null驱动,不进行任何网络的设置
可以发现,为了实现大量容器间的跨主机以及更灵活的网络通信,需要使用到SDN(Software defined networking)技术,这篇文章将从实践的角度进行演示。
Linux虚拟网络设备
tap/tun
tap/tun 提供了一台主机内用户空间的数据传输机制。它虚拟了一套网络接口,这套接口和物理的接口无任何区别,可以配置 IP,可以路由流量,不同的是,它的流量只在主机内流通。我们先来看看物理设备是如何工作的:
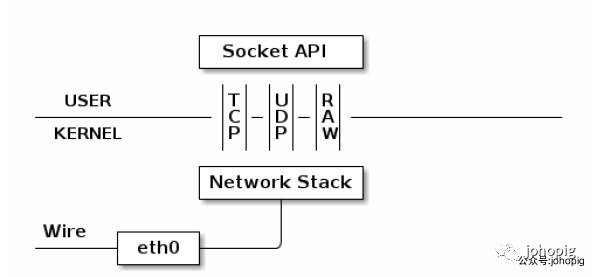
上图中的 eth0 表示我们主机已有的真实的网卡接口 (interface)。
网卡接口 eth0所代表的真实网卡通过网线(wire)和外部网络相连,该物理网卡收到的数据包会经由接口 eth0 传递给内核的网络协议栈(Network Stack)。然后协议栈对这些数据包进行进一步的处理(如丢弃/转发/通知)。
所有物理网卡收到的包会交给内核的 Network Stack 处理,然后通过 Socket API 通知给用户程序。下面看看 TUN 的工作方式:
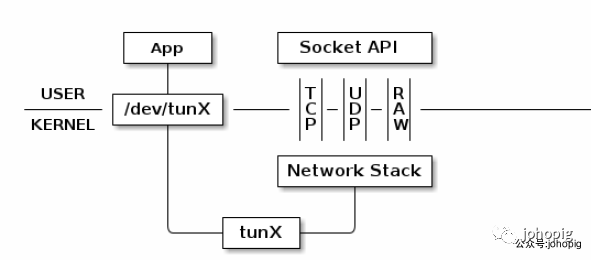
普通的网卡通过网线收发数据包,但是 TUN 设备通过一个文件收发数据包。所有对这个文件的写操作会通过 TUN 设备转换成一个数据包送给内核;当内核发送一个包给 TUN 设备时,通过读这个文件可以拿到包的内容。
tap和tun 有些许的不同:
TUN 设备是一个三层设备,它只模拟到了 IP 层,即网络层 我们可以通过 /dev/tunX 文件收发 IP 层数据包,它无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。可以使用 ifconfig
之类的命令给该设备设定 IP 地址。TAP 设备是一个二层设备,它比 TUN 更加深入,通过 /dev/tapX 文件可以收发 MAC 层数据包,即数据链路层,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。同样的,我们也可以通过 ifconfig
之类的命令给该设备设定 IP 地址,你如果愿意,我们可以给它设定 MAC 地址。
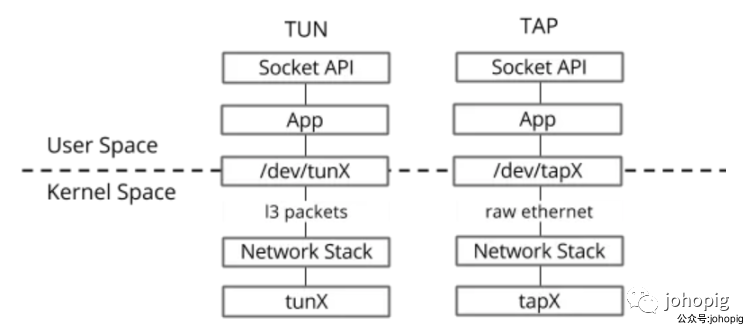
tap/tun 最常见的应用就是用于隧道通信,比如 VPN,包括 tunnel 和应用层的 IPsec 等。
bridge
bridge工作在数据链路层
Linux bridge也是一种虚拟网络设备,所以具备了虚拟网络设备的所有特性,如可以配置IP、MAC等,除此之外它还是一台交换机,可以根据MAC地址与端口的映射关系进行转发。docker默认使用的网络模式就是bridge。但bridge有个缺点就是当桥接的设备太多,需要广播的量就比较大,引发广播风暴,所以一般会用在小规模网络这种简单的形式。
macvlan
macvlan工作在数据链路层
有时我们可能需要一块物理网卡绑定多个 IP 以及多个 MAC 地址,虽然绑定多个 IP 很容易,但是这些 IP 会共享物理网卡的 MAC 地址,可能无法满足我们的设计需求,所以有了 MACVLAN 设备,其工作方式如下:
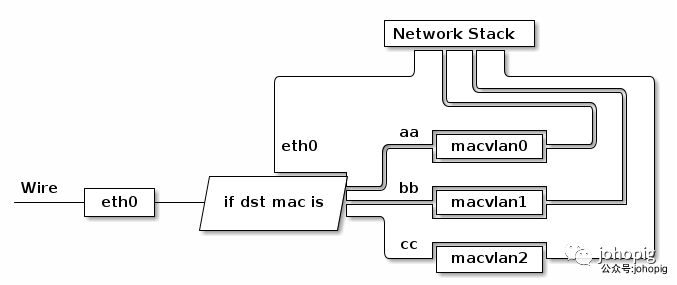
MACVLAN设备是从网卡上虚拟出来的一块新网卡,它和主网卡分别有不同的MAC地址,可以配置独立的IP地址。MACVLAN 会根据收到包的目的 MAC 地址判断这个包需要交给哪个虚拟网卡。单独使用 MACVLAN 好像毫无意义,但是配合之前介绍的 network namespace 使用,我们可以构建这样的网络:
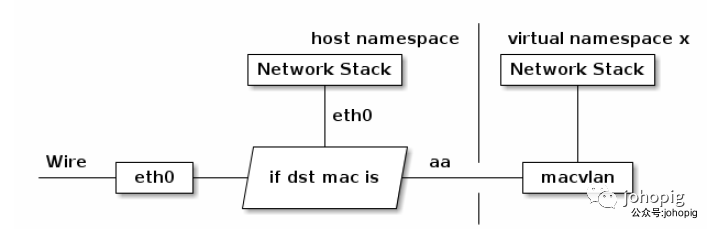
由于 MACVLAN 与 eth0 处于不同的 namespace,拥有不同的 network stack,这样使用可以不需要建立 bridge以及veth-pair设备 在 virtual namespace 里面使用网络。
macvtap
macvtap同样工作在数据链路层
MACVTAP 是对 MACVLAN的改进,把 MACVLAN 与 TAP 设备的特点综合一下,使用 MACVLAN 的方式收发数据包,但是收到的包不交给 network stack 处理,而是生成一个 dev/tapX 文件,交给这个文件:
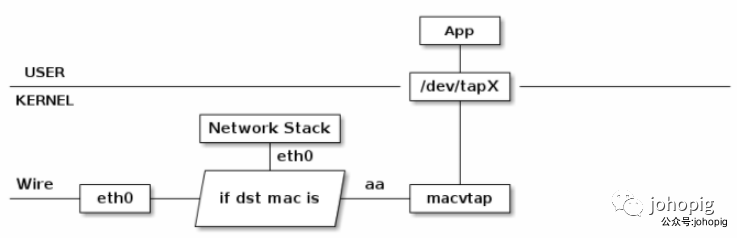
veth-pair
veth-pair 是成对出现的一种虚拟网络设备,一端连接着协议栈,一端连接着彼此,数据从一端出,从另一端进。
它的这个特性常常用来连接不同的虚拟网络组件,构建大规模的虚拟网络拓扑,比如连接 Linux Bridge、OVS、LXC 容器等。
来看看一次ping的通信过程:(若第一次ping不同可能和内核中一些ARP相关的默认配置限制导致,需要修改配置)
tcpdump -nnt -i veth0
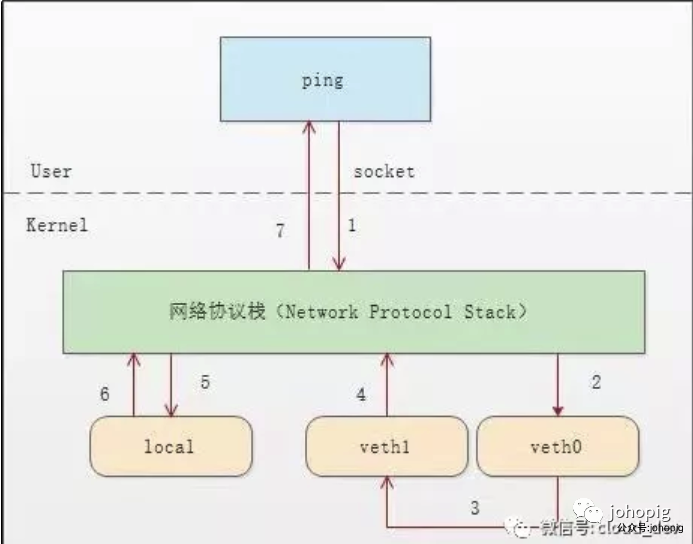
首先 ping 程序构造 ICMP echo request
,通过 socket 发给协议栈。由于 ping 指定了走 veth0 口,如果是第一次,则需要发 ARP 请求,否则协议栈直接将数据包交给 veth0。 由于 veth0 连着 veth1,所以 ICMP request 直接发给 veth1。 veth1 收到请求后,交给另一端的协议栈。 协议栈看本地有 10.1.1.3 这个 IP,于是构造 ICMP reply 包,查看路由表,发现回给 10.1.1.0 网段的数据包应该走 localback 口,于是将 reply 包交给 lo 口(会优先查看路由表的 0 号表, ip route show table 0
查看)。lo 收到协议栈的 reply 包后,啥都没干,转手又回给协议栈。 协议栈收到 reply 包之后,发现有 socket 在等待包,于是将包给 socket。 等待在用户态的 ping 程序发现 socket 返回,于是就收到 ICMP 的 reply 包。
如下图所示:
network namespace之间的连通性
直接相连
直连是最简单的方式,放一张图就能够很好的理解了。
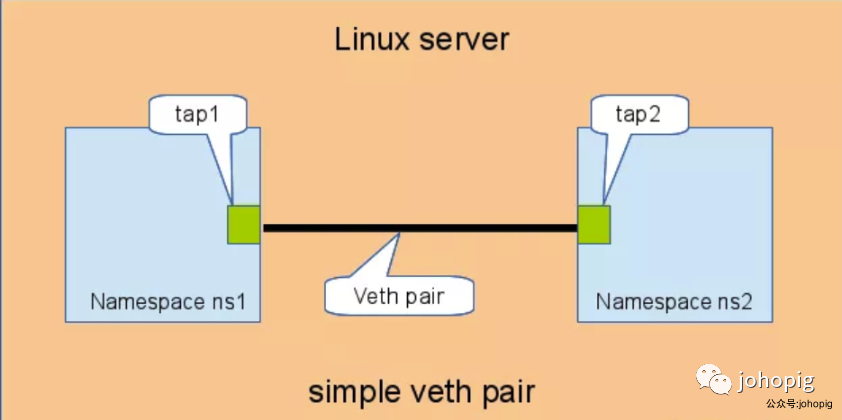
具体步骤如下:
# 创建network namespace
sudo ip netns add ns1
sudo ip netns add ns2
# 显示ns1 namespace中的网卡信息(默认创建一个回环设备)
sudo ip netns exec ns1 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 创建veth-pair设备
sudo ip link add veth-a type veth peer name veth-b
# 将网卡分别加入两个ns
sudo ip link set veth-a netns ns1
sudo ip link set veth-b netns ns2
# 给两个网卡分配IP并启动
sudo ip netns exec ns1 ip addr add 10.1.1.2/24 dev veth-a
sudo ip netns exec ns2 ip addr add 10.1.1.3/24 dev veth-b
sudo ip netns exec ns1 ip line set 10.1.1.2/24 dev veth-a up
sudo ip netns exec ns2 ip line set 10.1.1.3/24 dev veth-b up
# ping测试即可
使用 ip netns add
命令创建一个新的network namespace后,这样就拥有了一个独立的网络空间,可以根据需求来配置该网络空间,这就叫做SDN,如添加网卡、配置IP、设置路由规则,同时会默认创建一个回环设备(loopback interface:lo)。
当需要有更多的network namespace需要连接时,就需要引入虚拟网桥bridge了。
通过bridge相连
在使用Docker的过程中,默认的网络模式 (bridge驱动) 在启动一个容器时,肯定会在主机上创建一个network namespace。不过,这个新建的namespace并不能通过 ip netns list
查看到,这是因为该命令是去/var/run/netns
目录下查找,而docker容器进程的network namespace可以通过获取容器进程PID,再将/proc/$PID/ns/net
软连接到/var/run/netns/$PID
中
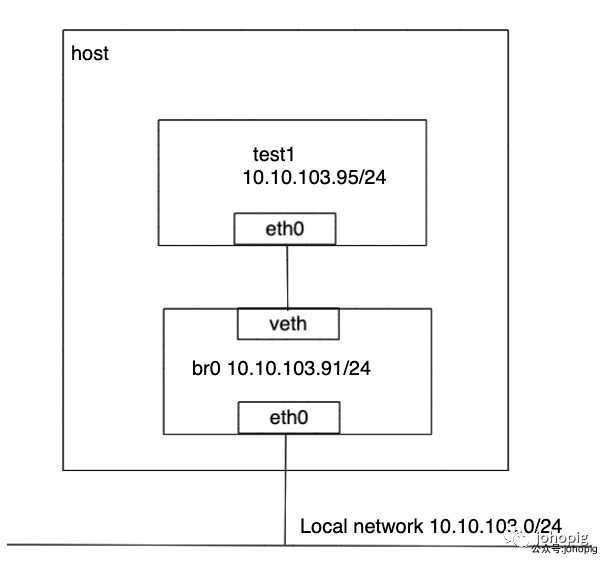
下面,我们采用--net=none的驱动方式来手动进行容器的网络通信配置。首先启动一个名为test1的Docker容器:
sudo docker run -itd --name test1 --net=none ubuntu /bin/bash
启动后,可以看到通过ip netns list
没有看到新建的network namespace。接下来,我们继续操作
# 创建一个供容器连接的网桥并启动它
sudo brctl addbr br0
sudo ip link set br0 up
# 将eth0的IP配置在br0上,并将主机eth0桥接到br0上以及配置默认路由。(远程操作会断开连接,所以需要一次性操作完)
sudo ip addr add 10.10.103.91/24 dev br0; \
sudo ip addr del 10.10.103.91/24 dev eth0; \
sudo brctl addif br0 eth0; \
sudo ip route add default via 10.10.103.254 dev br0
# 找到test1的PID,保存起来
$pid=$(sudo docker inspect --format '{{ .State.Pid }}' test1)
# 将容器的network ns添加到/var/run/netns目录下
sudo mkdir -p /var/run/netns
sudo ln -s /proc/$pid/ns/net /var/run/netns/$pid
# 创建用于连接网桥和Docker容器的网卡设备对
sudo ip link add veth-a type veth peer name veth-b
# 将veth-a连接到网桥中
sudo brctl addif br0 veth-a
sudo ip link set veth-a up
# 将veth-b放到test1的network namespace中,并重命名为eth0,并为其配置IP和默认路由
sudo ip link set veth-b netns $pid
sudo ip netns exec $pid ip link set dev veth-b name eth0
sudo ip netns exec $pid ip link set eth0 up
sudo ip netns exec $pid ip addr add 10.10.103.95/24 dev eth0
sudo ip netns exec $pid ip route add default via 10.10.103.254
配置完的Docker容器和主机连接的网络拓扑如下:
Refer
https://www.cnblogs.com/bakari/p/10450711.html https://blog.kghost.info/2013/03/27/linux-network-tun
