




kafka是一种高吞吐量(几万、几十上百万)的分布式基于发布/订阅的消息队列。相比较其他消息中间件(RocketMQ)的特点是吞吐量大,可以忍受少量消息丢失,所以在大数据实时处理领域得到广泛使用。
kafka架构
主要由Broker、Producer、Consumer、Consumer Group、Topic、Partition构成。
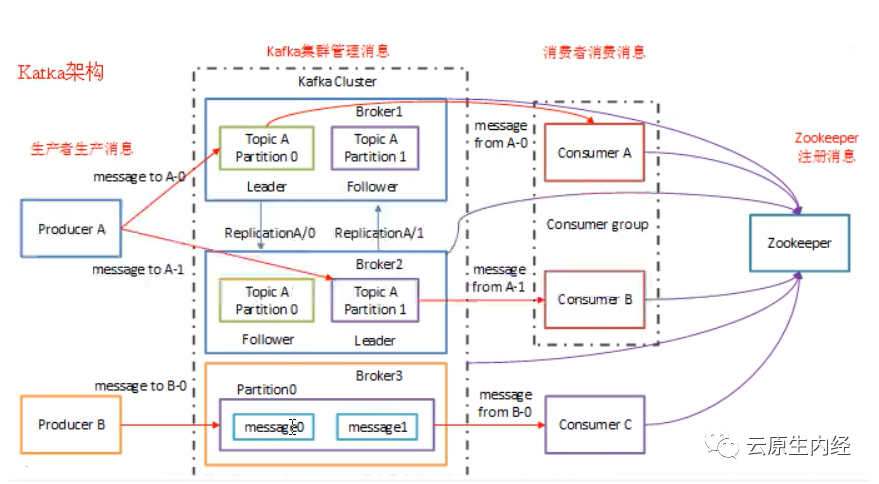
kafka核心概念
Broker:是kafka的服务节点,即kafka的服务器。 Topic: kafka中的消息以Topic为单位进行划分,生产者将消息发送到特定的Topic,而消费者负责订阅Topic的消息并进行消费。 Partition:Topic物理上分组,它可以分为多个分区,每个分区只属于单个主题。同一个主题下不同分区包含的消息是不同的,分区在存储层面可以看作一个追加的日志文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量。 Segment:partition物理上由多个segment组成,每个segment存着message信息。 Offset:offset是消息在分区中的唯一标识,kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,kafka保证的是分区有序性而不是主题有序性。 Replica:保证数据高可用的方式,kafka同一partition的数据可以在多Broker存在多个副本,通常只有主副本对外提供读写服务,当主副本所在broker宕机,kafka会在controller的管理下重新选择新的Leader副本对外提供读写服务。 Producer:生产者,也就是发送消息的一方。生产者负责创建消息,然后将其发送到kafka。 Consumer:消费者,也就是接受消息的一方。消费者连接到kafka上并接收消息,进而进行相应的业务逻辑处理。 Consumer Group:一个消费者组可以包含一个或多个消费者。使用多分区+多消费者方式可以极大提高数据下游的处理速度,同一个消费组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消费消息时互不影响。kafka是通过消费组的方式来实现消息P2P模式和广播模式。 zookeeper:负责维护和协调broker。当kafka系统中新增了broker或者某个broker发生宕机,由zk通知生产者和消费者。生产者和消费者依据zk的broker状态信息与broker协调数据的发布和订阅任务。最新版本kafka已不需要zk。 Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。 Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与leader保持数据同步。如果leader失效,则从follower中选举出一个新的leader。当follower与leader同步太慢,leader会把这个从ISR删除,重新建一个Follower。
kafka安装模式
helm chart安装,分amd/arm镜像,推荐使用3 broker方式。 添加kafka源:helm repo add bitnami https://charts.bitnami.com/bitnami 更新kafka源:helm repo update 下载kafka helm包:helm pull bitnami/kafka; 解压kafka-12.20.0.tgz文件,tar zxvf kafka-12.20.0.tgz 修改values.yaml中副本为3, helm install kafka-test ./kafka 由于arm镜像官方没有推出,需要自己手动构建,可参考:https://github.com/bitnami/bitnami-docker-kafka
kafka后台操作基本指令
本文指令使用broker连接信息,不采用zk。进入/opt/bitnami/kafka/bin目录下有对应指令 创建主题:./kafka-topics.sh --create --bootstrap-server ip1:9092,ip2:9092,ip3:9092 --replication-factor 2 --partitions 3 --topic test 查看主题:./kafka-topics.sh --list --bootstrap-server ip1:9092,ip2:9092,ip3:9092 主题详情:./kafka-topics.sh --describe --bootstrap-server ip1:9092,ip2:9092,ip3:9092 --topic test 增加topic分区数:./kafka-topics.sh --bootstrap-server ip1:9092,ip2:9092,ip3:9092 --alter --topic topicName --partitions 8 删除topic,需要在server.properties中配置delete.topic.enable=true;./kafka-topics.sh --bootstrap-server ip1:9092,ip2:9092,ip3:9092 --delete --topic test 查看topic某分区偏移量:./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list ip1:9092,ip2:9092,ip3:9092 --topic test 生产者生产数据:./kafka-console-producer.sh --broker-list ip1:9092,ip2:9092,ip3:9092 --topic test 消费者消费数据:./kafka-console-consumer.sh --from-beginning --topic test --bootstrap-server ip1:9092,ip2:9092,ip3:9092
Go对应的kafka api接口
由于kafka官方没有支持go client,本文主要使用sarama包下的go client。
操作kafka对应的client:client, err := sarama.NewClient(brokerList, config)
brokerList为kafka中broker地址,用逗号隔开;config为对应的配置文件,sarama.NewConfig()设置。 管理员client:clusterAdmin, err := sarama.NewClusterAdminFromClient(client)
消费者client: consumerClient, err := sarama.NewConsumerFromClient(clinet)
消费组client:consumerGroupClient, err := sarama.NewConsumerGroupFromClient(groupID,clinet)
生产者client:producerClient, err := sarama.NewSyncProducerFromClient(client)
偏移量管理client:offsetClient, err := sarama.NewOffsetManagerFromClient(group,client)
创建topic:clusterAdmin.CreateTopic(topicName, topicDetail, false)
topic详情:sarama.TopicMetadata, err := clusterAdmin.DescribeTopics([]string)
列出topic:topicDetails, err := clusterAdmin.ListTopics()
删除topic:clusterAdmin.DeleteTopic(topicName)
列出某Topic对应的消费组
找到消费组:groupMap, err := clusterAdmin.ListConsumerGroup() 消费组详情:descriptions, err := clusterAdmin.DescribeConsumerGroups(groups) 根据topic过滤过去GroupID 根据topicName列出partition:
获取partions的:ids, err := client.Partions(topicName) 获取某topic某partition下的偏移量offSet,此处为下一个偏移量的值:maxOffset, err := client.GetOffset(topicName,partitionID,sarama.OffsetNewest) 某topic、某partion下,发送消息:pid, offSet, err := producerClient.SendMessage(msg *ProducerMessage)
按offset查询消息:saramaMessages, err := consumerClient.ConsumePartition(topic, partition, offset)
按时间查询消息,先通过时间获取对应的offSet:startOffset, err := client.GetOffset(topic,partition,startTime)
获取消息:messages, err := consumerClient.ConsumePartition(topic,partition,startOffset) 创建消费组查询消息:saramaMsgs, err := consumerGroupClient.Consume(ctx,topics,&consumer)
获取某topic某partition某offset的消费消息;当消息已消费,此处报错。
messages, err := sarama.Consumer.ConsumePartition(topic, partition, offset) 更加topicName和PartitionID获取偏移量:nextOffset, _, err := offsetClient.GetPartionOffset(topicName,PartitionID)
重置offset:partitionManager, err := offsetClient.ManagePartition(topic,partition); partitionManage.ResetOffset(offset,metadata)
kafka数据索引机制
topic在物理层面以partition为分组,一个topic可以分成若干个partition。partition可以细分为segment,一个partiton物理上由多个segment组成。 Logsegment文件由“.index”文件和“.log”组成,分别为索引文件和数据文件。 partition全局的第一个segment从0开始,后续每个segment文件名最后一条消息的offset值。 数值大小为64位,20位数字字符长度,没有数字用0填充。 第一个segment:00000000000000000000.index和00000000000000000000.log 第二个segment,为最后一条offset组成:00000000000000170410.index。 索引文件以稀疏索引的方式构造消息的索引。 偏移量索引和时间戳索引根据二分查找法来定位。 检索查询只是Kafka的一个辅助功能,不需要为了这个功能而去花费特别太的代价去维护一个高level的索引。
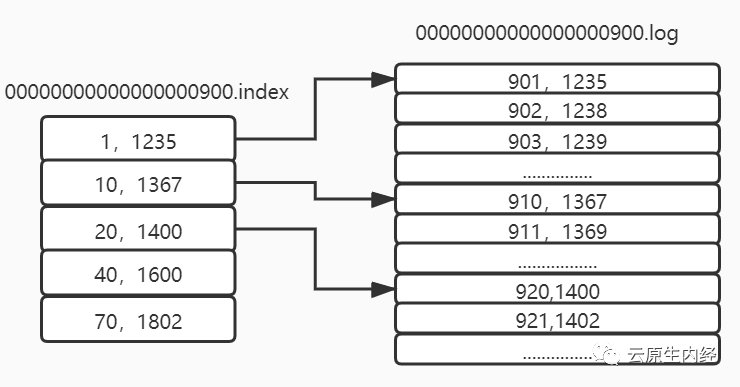
如何通过 offset 找到 某一条消息呢?
首先会根据 offset 值去查找 Segment 中的 index 文件,因为 index 文件是以上个文件的最大 offset 偏移命名的所以可以通过二分法快速定位到索引文件。 找到索引文件后,索引文件中保存的是 offset 和对应的消息行在 log 日志中的存储行号,因为 Kafka 采用稀疏矩阵的方式来存储索引信息,并不是每一条索引都存储,所以这里只是查到文件中符合当前 offset 范围的索引。 拿到 当前查到的范围索引对应的行号之后再去对应的 log 文件中从 当前 Position 位置开始查找 offset 对应的消息,直到找到该 offset 为止。
参考
https://kafka.apachecn.org/documentation.html
