




背景
大数据存储场景:一般有点实力的公司,会自有机房,将自己的内部数据存储在服务器集群当中,而一些前期没考虑机房的公司,会选择将数据存储在公有云上,国内现在比较厉害的有阿里云、华为云、亚马逊云等。
今天有个需求,客户公司,他们的数据存储在阿里云上,使用的是MaxCompute(原ODPS)来计算和分析数据。MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务。
考虑到直连客户数据库的敏感性和数据的安全性,我们选择直接将它dataworks下的几张表的数据经过处理之后给同步到我们自己的库中。
DataWorks | DataStudio控制台介绍
1、登录到产品服务中心:选择Dataworks

2、选择左侧MaxCompute

3、选择数据开发服务

4、表管理
这里可以看到,该账号下赋予权限所能操作的所有表,双击,可查看及更改结构

5、sql执行
左侧栏目第一个按钮,业务流程中,maxcompute----数据开发---右键新建odps sql,
可以写sql,并执行
在这里你可以测试数据,查看表结构、建表等操作

6、数据和表恢复
我之前不小心把人家一个表给删了,drop用时一时爽,爽完简直头皮发麻;我drop的还是人家生产环境的表,一个表数据几百万,当时心里慌死了,/(ㄒoㄒ)/~~。
但转头一想,毕竟是阿里云,肯定有恢复机制,于是乎查到了资料,附上链接:
https://help.aliyun.com/document_detail/172397.html

纵使有恢复机制,但是还是要警戒,一定要慎用delete 、drop、truncate,慎用,慎用!一定要做好备份和恢复!!!!!!!!!!
数据同步
1、源数据源建测试表person
(因为我执行了两次,所以有两条记录)

2、目标数据源建表

3、建立通道,选择数据来源和数据去向。
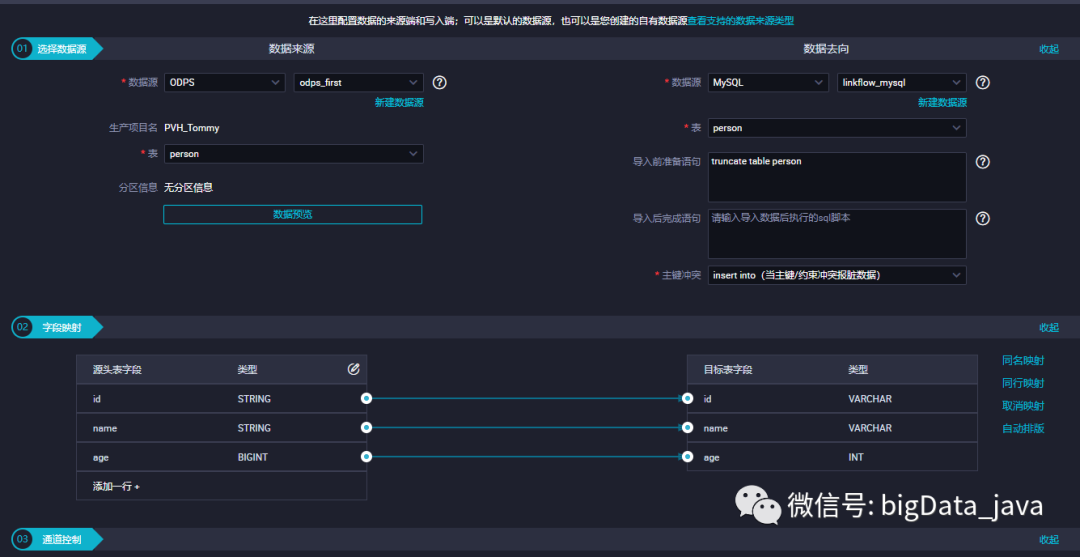
4、执行,导入。如下图:

注意点
阿里云的dataworks中的maxcompute 不能使用sql脚本处理后再导出
可以在源数据存储处建立中间表
odps中数据转换,普通转换 cast(field as type)
odps中日期格式化转换 to_date('',format) 注意,format的格式是前面日期的格式,如to_date('今天是20210429','今天是yyyyMMdd')
更多学习、面试资料尽在微信公众号:Hadoop大数据开发
大数据学习交流QQ群:139809179

你不知道的查找算法之布隆过滤器(建议收藏)
没有对象怎么办?new一个(面向对象OOP六大原则系列上,建议收藏)
