HBase概述
Hbase简述
Hbase是一个高可靠性的、可性能的(查询快,通过key取数据块,算法,索引,缓存),面向列的可伸缩性的分布式数据库系统。
HBase特点
1.可存储海量数据 -------借助HDFS
2.高扩展性-------存储能力、运算能力 使用廉价机器的横向扩展
3.分布式 数据库系统 解决高并发访问的问题
4.列式存储数据: 在物理存储上,hbase的数据是按照列族分开存储的K V对的字节数组,在对应的hdfs中,一张表对应一个文件夹,在对应的hdfs中,一张表对应一个文件夹,
下面有表的列族的子文件夹
/hbase/data/default(namespace)/table_name/region/cf/hfile
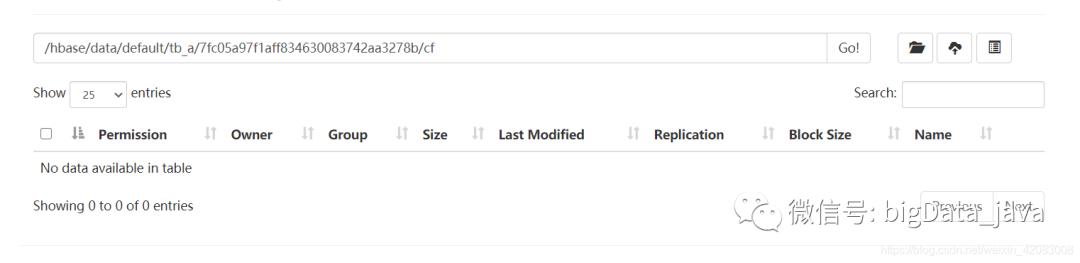
hbase 中的namespace名称空间 相当于 mysql中的数据库名
5.稀疏性(半结构化的数据,每行的属性可能不一样),在列数据为null的情况下是不会占用空间的
6.可存储 结构化、半结构化、非结构化数据 包括视频、音乐等,但最终存储的都是字节
关键词解释
行键 rowkey
行键:rowkey 唯一的确定的一行数据,行的标识,索引,全局排序。基于rowkey存储的数据
rowkey 行的唯一标识 1)排序 2)索引 3)事务 4)查询算法
列族 cf
列的属性相近的一组,方便管理属性
列族可以看做是数据表 中 列的切割 纵向切割,称之为一个column family
定义时建议列族不要定义的太多,列族尽可能少,列名尽可能短 (每一个KeyValue所携带的自我描述信息,会带来显著的数据膨胀【大量的冗余 ,所以在设计rowkey , 列族名 ,属性名的时候尽量简短】)
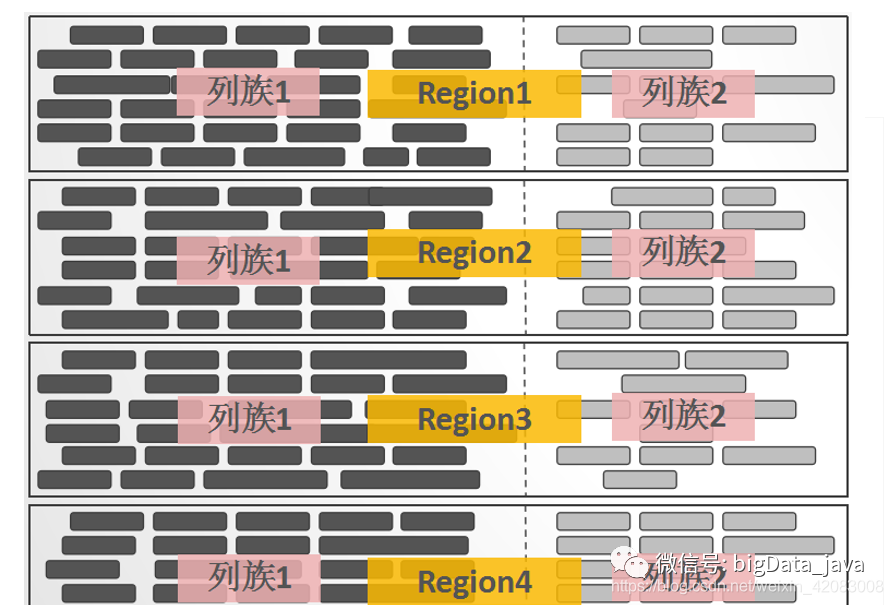
列名
列名 具体到真正的属性 行的列只有插入数据的时候才确定
region
行范围的数据抽象 是hbase中负载均衡的基本单元,当一个region增长到一定大小之后,会自动分裂成两个
region可以看做是数据表 中 行的切割 横向切割

key table_name:rowkey:cf:属性 value 值
hbase中的数据没有类型约束(所谓没有约束,其实就是byte())
在物理上,hbase的数据key-value 是按照完整的key的字段顺序有序存储
Shell端 命令
hbase shell 连入到hbase的客户端
常规普通
processlist, 进程列表 (region的拆分 , region的合并...)
status, 集群状态 ****
1 active master, 0 backup masters, 3 servers, 0 dead, 1.3333 average load
table_help, 表的帮助(X)
version, hbase的版本 ****
hbase(main):004:0> version
2.2.5, rf76a601273e834267b55c0cda12474590283fd4c,
whoami 当前用户 ****
hbase(main):003:0> whoami
root (auth:SIMPLE)
groups: root
DDL
DDL 表的定义语言,与表的结构有关的操作
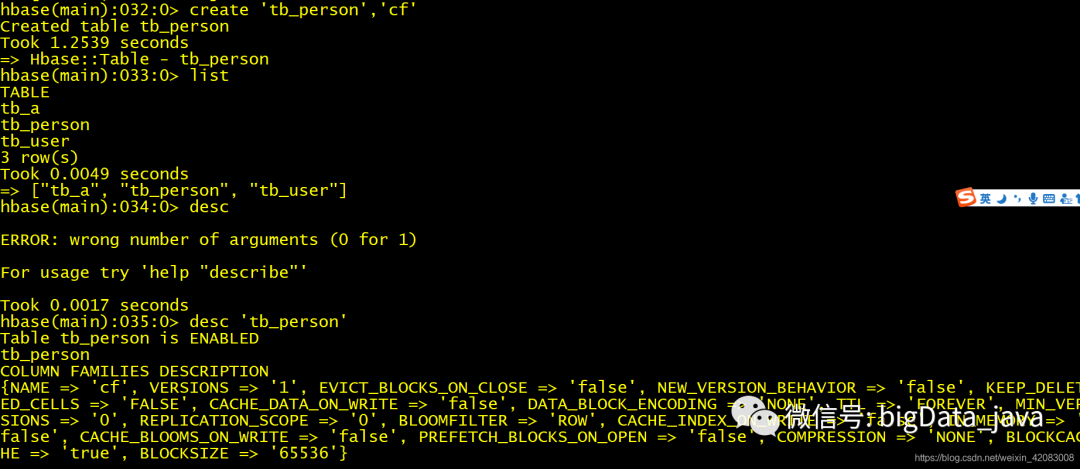
create 建表 creat ‘表名’ ,‘列族名’ 至少需要两个参数 表名和列族名
create 创建带有属性的表 create 'tab_name'
create 'table_name',{NAME=>'cf1',VERSION=>'5',TTL=30000} TTL数据有效时间,生命周期
list 查询所有的表
disable 'table_name' 禁用
enable 'table_name' 启用
disable_all disable_all 'tb.*'
enable_all 启用多张表
drop 'table_name' 删除表之前需要先禁用表
drop_all 删除多张表 drop_all 'tb.*'
exists 表是否存在
is_disabled 是否被禁用
is_enabled 是否被启用
desc 查看表的结构 desc 'tb_person'
创建预分区的表
create 'table_name','cf_name',SPLITS=>['10','30','50'] 创建一个预分区为4个region的表 region1 :_-----10 region2 : 10------30 region3:30------50 region4:50-------_
每个节点在下个分区内 比如10切割点 在第二个分区内
创建预分区的目的:
由于我们创建表,默认是一个region,添加数据时,也是往这一个region内添加数据,会产生并发插入问题,所以在创建表的时候就进行预分区,避免并发热点问题。

alter 修改表结构 (列族,列族属性)
修改列族属性
alter 'table_name',{NAME=>'cf1',VERSIONS=>'3',TTL=>10000} 将cf1列族 的VERSIONS修改为3 TTL修改为10000s
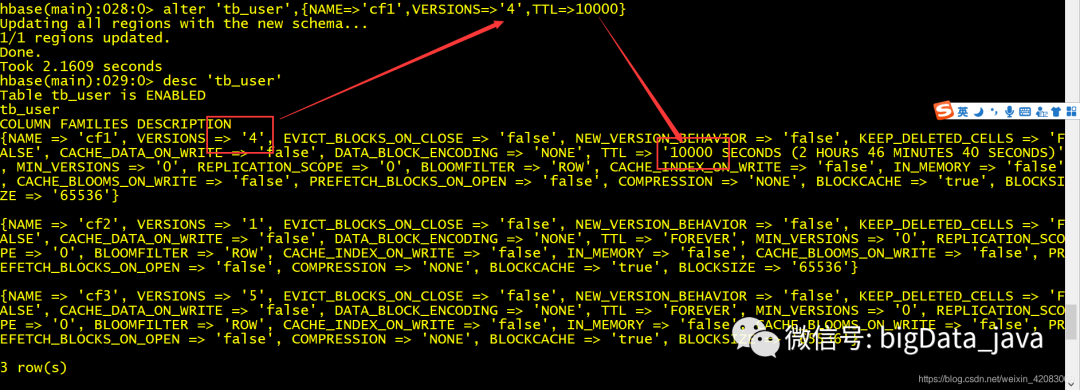
添加列族属性
alter 'table_name',{NAME=>'a',VERSIONS=>'10',TTL=>'FOREVER'} 如果列族 名不存在,则直接创建一个新的列族
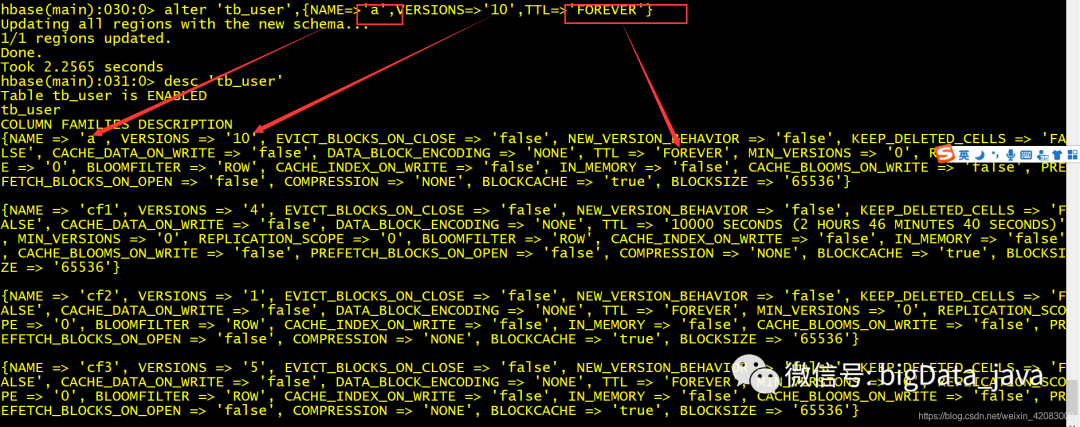
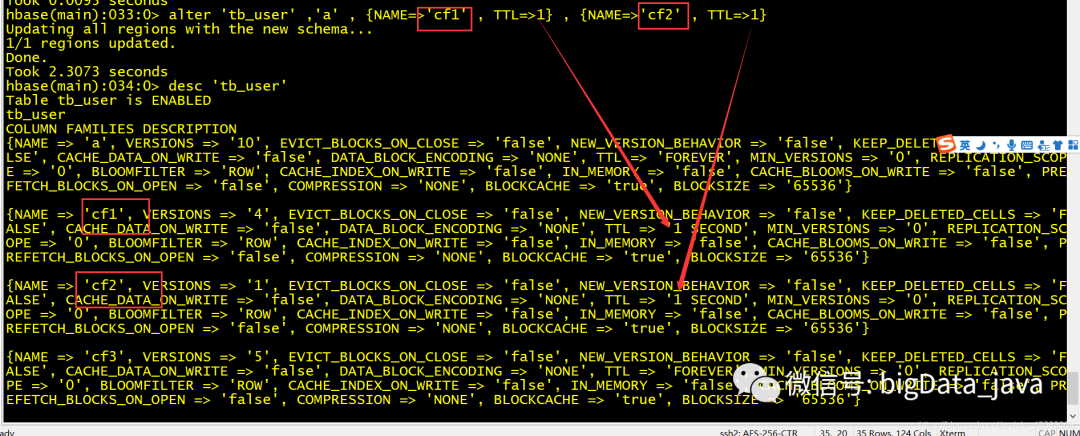
修改多个列族的属性
alter 'table_name' ,'a' , {NAME=>'cf1' , TTL=>1} , {NAME=>'cf2' , TTL=>1}
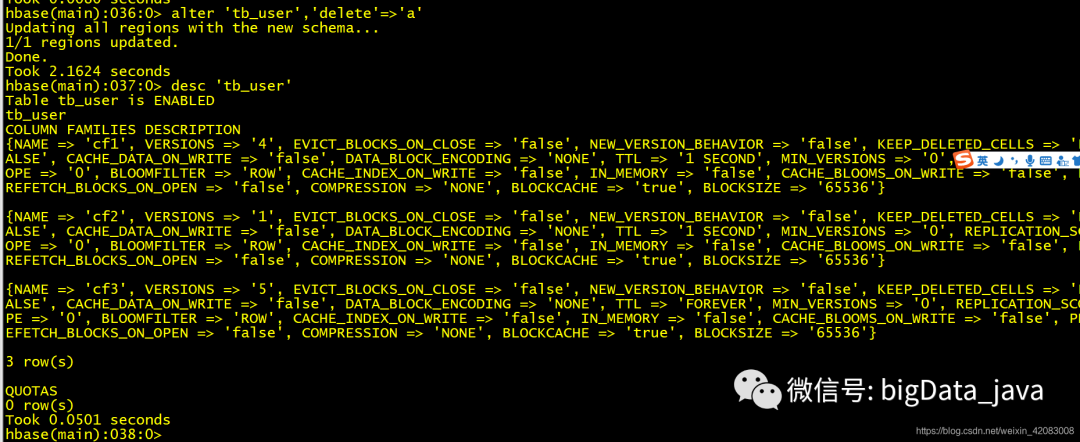
删除列族
alter 'table_name','delete'=>'a'
alter_namespace 修改属性 添加 修改额外的补充属性
create_namespace
drop_namespace 必须是空名称空间
list_regions 'table_name' 列出指定表的所有region
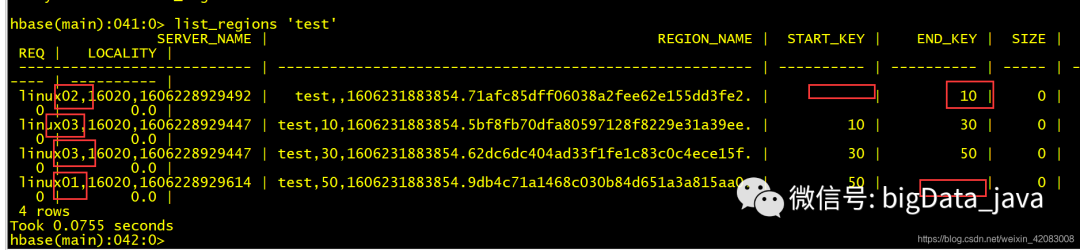
locate_region 某行在哪个region上
DML
DML 数据操作语言 与数据库的数据操作有关
put 插入数据 put 'table_name','rowkey','cf_name:属性名','value'
get 获取数据 属性值 get 'table_name','rowkey','cf_name:属性'
行数据 get 'table_name','rowkey'
列族数据 get 'table_name','rowkey','cf_name'
scan 'table_name' 全盘扫描表数据
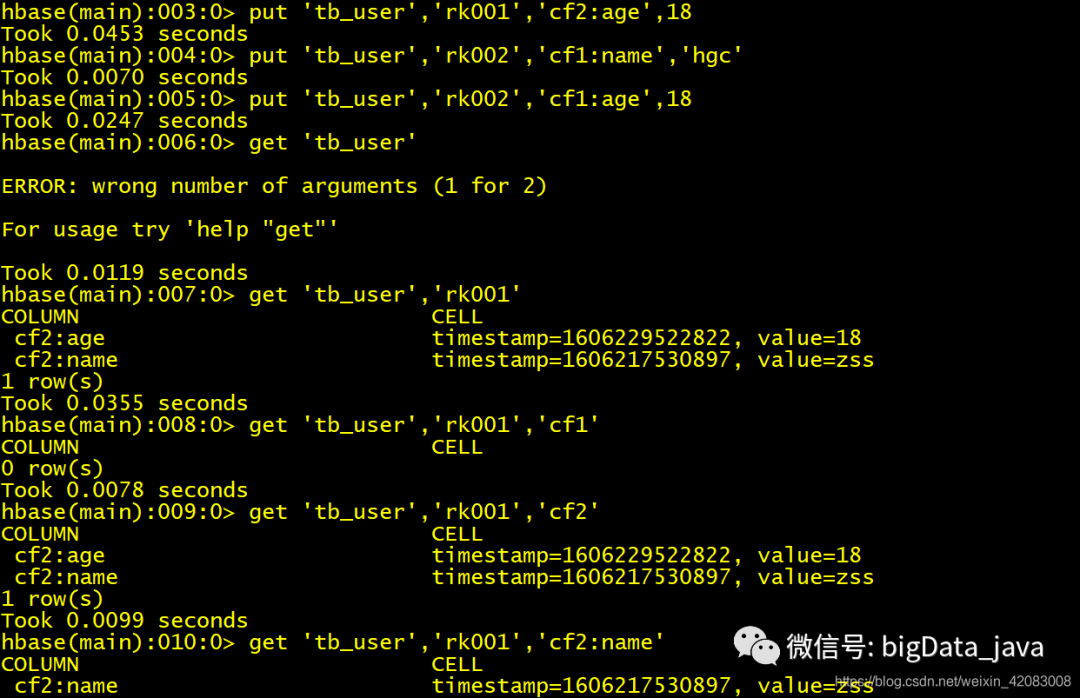

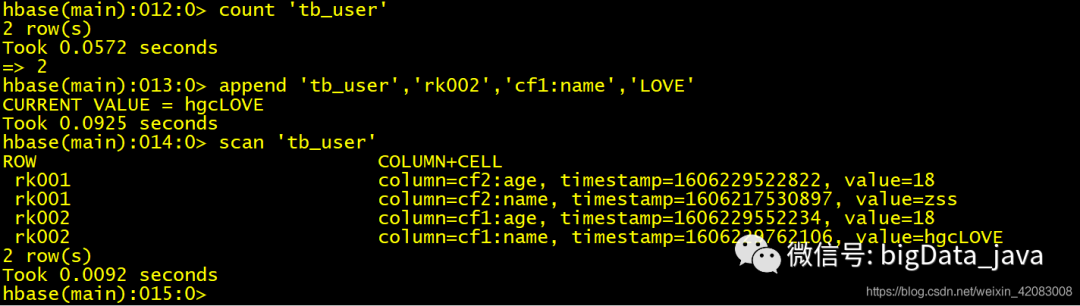
count 统计行数
append 追加内容 只能向已存在的属性 的值 的后面追加内容
JAVA API连接客户端
java 端核心对象
配置对象
Configuration conf = HBaseConfiguration.create();
连接对象
onnection conn = ConnectionFactory.createConnection(conf);
//获取表对象
TableName tableName = TableName.valueOf("tb_user");
Table table = conn.getTable(tableName);
Admin对象
Admin admin = conn.getAdmin();
代码如下:
Demo01
package cn._doit19.hbase.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
/**
* @author:tom
* @Date:Created in 15:23 2020/11/24
*/
public class Demo01 {
public static void main(String[] args) throws Exception {
//使用java客户端 连接 操作hbase
//创建连接对象
//直接连接zookeeper
//获取配置对象
Configuration conf = HBaseConfiguration.create();
//设置参数,设置zk的位置
conf.set("hbase.zookeeper.quorum", "linux01:2181,linux02:2181,linux03:2181");
//创建连接对象 Zookeeper
Connection conn = ConnectionFactory.createConnection(conf);
//获取表对象
TableName tableName = TableName.valueOf("tb_user");
Table table = conn.getTable(tableName);
Delete del = new Delete("rk001".getBytes());
table.delete(del);
table.close();
conn.close();
}
}
Demo02:
package cn._doit19.hbase.day01;
import cn._doit19.hbase.utils.HbaseUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author:tom
* @Date:Created in 17:29 2020/11/24
*/
public class Demo02 {
public static void main(String[] args) throws Exception {
Connection conn = HbaseUtil.getConn();
// TableName tableName=TableName.valueOf("")
// Table table=;
// table = conn.get
//admin 操作的是DDL 和tools
Admin admin = conn.getAdmin();
TableName[] tableNames = admin.listTableNames();
for (TableName tableName : tableNames) {
String name = Bytes.toString(tableName.getName());
String namespace = Bytes.toString(tableName.getNamespace());
String qualifier = Bytes.toString(tableName.getQualifier());
System.out.println(name);
System.out.println(namespace);
System.out.println(qualifier);
System.out.println("============");
}
admin.close();
conn.close();
}
}
更多学习、面试资料尽在微信公众号:Hadoop大数据开发





