排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
3
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
聊聊lLSM-TREE存储引擎
聊聊lLSM-TREE存储引擎
白鳝的洞穴
2021-07-06
1738
前阵子有个网友在公众号留言,想让老白聊聊L
SM-TREE
存储引擎。实际上前段时间老白写过一个关于L
SM-TREE
存储引擎的H
TAP
数据库的系列,不过那篇文章更主要是分析了近些年较为流行的几个H
TAP
分布式数据库的底层技术的优缺点,虽然对L
SM-TREE
做了一些描写,但是并不深入。今天我在此系列第一篇的基础上,对L
SM-TREE
存储引擎做一些更详细的分析。
近些年来L
SM-TREE
存储引擎十分热门,很多数据库都采用了L
SM-TREE
存储引擎,可能大多数搞数据库的都听说过,不过可能不一定会去认真深究L
SM-TREE
是怎么回事。实际上L
SM-TREE
是影响我们这个世界的谷歌三大论文中的BigTable中提出的,L
SM-TREE
是
Log Structured Merge Tree
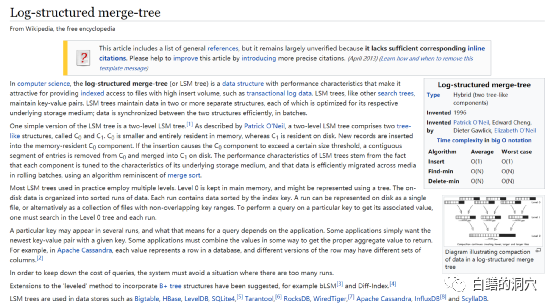
的简称,维基百科的描述如下图。
维基百科对L
SM-TREE
的定义中提出,L
SM-TREE
是一种对于高性能写入十分有效的数据结构。在L
SM-TREE
的设计思路中,L
SM-TREE
基于谷歌的著名的五分钟理论,也就是说如果某个数据每5分钟至少被访问一次,那么这个数据最好存放在内存里。L
SM-TREE
存储引擎也是计算机系统近些年快速发展,C
PU
、内存的价格大幅度下降的结果。因为实现L
SM-TREE
存储引擎的关键是大内存和强大的C
PU
处理能力。
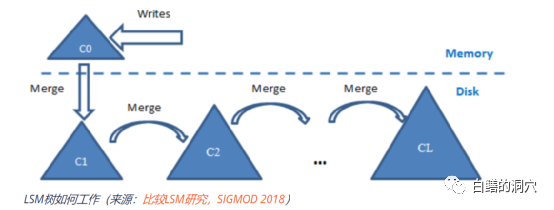
L
SM-TREE
的数据在C
0
阶段是存储在内存中的S
STABLE
中的,这些S
STABLE
按照一定大小的S
EGMENT
存储在内存中,当一个S
EGMENTS
写满后进入锁定状态,新数据将被写在新的S
EMGENTS
中,而锁定状态的S
EGMENT
经过M
ERGE
后会被写入磁盘进行持久化。
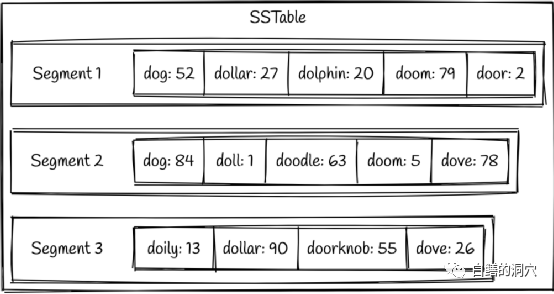
大家可能也看出来了,这种S
STABLE
写入的时候,如果是U
PDATE
操作,是不管某条数据是否存在的,只管把最新的数据写入S
STABLE
,然后当一个S
EGMENT
写满后整体刷盘,这样的架构对于大并发的数据写入操作/
UPDATE
操作比传统的以H
EAP/BTREE
的模式要快得多。
L
SM-TREE
和数据库又是什么关系呢?我们借用互联网上的一张图来解释一下。
数据库一般包括sql引擎和存储引擎两部分。存储引擎可能把数据存放在持久化存储设备(比如硬盘)上,或者易失性的内存里(比如内存数据库)。在数据库发展的这些年里,存储引擎一直是B
+TREE
结构占主导地位。随着这些年分布式数据库的发展,谷歌论文BigTable中的L
SM-TREE
成为一种存储引擎的新宠。下面的图同样来自于互联网,列出了两大阵营中的主要数据库产品。传统的内存数据库实际上在存储结构上也采用了堆结构。内存数据库与普通的磁盘数据库之间的差异也是很大的,绝对不是把磁盘文件全部放入内存而已。因为内存数据库的数据访问基本上是基于
memcpy
的,而传统的磁盘库要使用d
isk/file io
接口去访问数据文件。这里我们不重点讨论内存数据库引擎,普通的内存数据库引擎大部分是H
EAP
存储结构的特殊的存储引擎,而一些新的内存数据库也开始使用L
SM-TREE
存储结构了。
我们可以看到,大多数的传统数据库或者非分布式数据库都采用了
B-TREE
结构的存储,表的数据存储在堆结构的数据块中,索引使用B
-TREE
结构。而一些新型的分布式数据库都采用L
SM TREE
存储结构。
基于B
-TREE
结构的存储引擎具有较好的事务处理能力,但是对于大规模的数据写入性能与L
SM-TREE
相比有巨大的差距。因为L
SM-TREE
采用内存缓冲+大批量顺序写入的方式,对于高写入的场景具有极高的性能。特别是在更适合顺序访问的
SSD
盘
。
L
SM-TREE还
很
适合于分层存储,其中可以利用具有不同性能/成本特性的不同类型的存储,例如RAM,SSD,HDD和远程文件存储(例如AWS S3)。
不过L
SM TREE
也存在自身的不足,在大吞吐量读的场景下,L
SM-TREE
需要消耗更多的I
O
,另外为了保证L
SM-TREE
的性能,需要进行比较和合并操作,这个操作相当消耗C
PU
和I
O
资源。
基于上述的原理,L
SM-TREE
是一种十分适合于大型写入场景的存储引擎,不过由于S
STABLE
的M
ERGE
的需要,会更加消耗C
PU
和I
O
资源。不过随着写在计算于I
O
能力的极大提升,这种存储引擎对于现代的计算机系统来说,算是十分适合的。
这种存储引擎中,如果仅仅是一些不做U
PDATE
的时序数据或者指标数据,那么其写入是十分高效的,如果数据存在大量的U
PDATE
操作,那么一条记录在数据库中可能存在多个副本。基于L
SM-TREE
存储引擎的数据库的M
VCC
也是基于这总多副本机制来实现的。因此,在做
COMPARE AND MERGE
的时候,不仅仅要考虑如何高效的进行合并,还要考虑M
VCC
多版本的有效性控制,因为数据库操作的U
NDO
和一致性读都是要依靠这个多副本机制来实现的。因此L
SM-TREE
要用于关系型数据库,需要有更为强大的多副本控制能力。
还有一点要注意的是,C
OMPARE AND MERGE
操作是在后台进行的,数据库要实现既能够高效的合并,又不会影响应用访问相关数据,对算法有较高的要求。如果某个热数据并发访问十分频繁,此时正好在做M
ERGE
处理,那么此时数据库的热块冲突会被极大的放大,严重时会对数据库应用的性能造成巨大的影响。而如果M
ERGE
操作延后太多,又会导致U
PDATE
十分频繁的表的容量出现暴涨,从而影响全表扫描的性能。
基于存储引擎方面存在的一些缺点,基于L
SM-TREE
存储引擎的数据库,对于U
PDATE
十分频繁,同时访问热度又较高的情况,如何保障性能是一个难点。因此如果我们在测试一个基于l
sm-tree
存储引擎的数据库的时候,不要光是测试并发写入的性,这是所有L
SM-TREE
存储引擎的数据库都很强的地方。而是要多测试一些U
PDATE
十分频繁的表上面的一些复杂查询S
QL
的性能,特别是全表扫描等操作的性能。当然如果你的应用中不存在这样的场景,那么你就可以比较放心的使用基于L
SM-TREE
存储引擎的数据库了。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨