




作者:刘伟,云和恩墨软件开发部研究院研究员;前微博DBA,主要研究方向为开源数据库,分布式数据库,擅长自动化运维以及数据库内核研究。
前言
即便是从数据库特性,SQL功能性等方面,PostgreSQL都是一个更接近Oracle,在这方面远胜于MySQL的数据库,但是这个来源是学校的教学数据库的开源数据库,在很多地方,设计实现上的考虑,从我目前来看,是不完备的,其中的典型代表,就是vacuum机制.
如果是一直搞别的数据库的人,无论是MySQL还是Oracle的DBA,看PostgreSQL总感觉会有个很显眼的数据库概念不见了–UNDO表空间.而用来解决UNDO表空间这个设计需要解决的问题的,在PG中对应的概念总称,就是vacuum这个词了.
正好最近看到pg的新版本特性讨论中,提到在pg新版本中要引入undo这个概念,于是就有了对这一系列概念进行整理的想法.
MVCC
首先说一下,在最原始的数据库理论中,是没有MVCC这个概念的.如果现在的DBA学习数据库理论,用一些比较老的教材,会发现,课本上理论的实现,与实际上操作的数据库之间,是有很大差别的.
简单描述来说(这里就不展开ACID以及隔离级别的拓展讨论了),在最早的数据库理论里,行上的锁有两种,读锁与写锁,当要访问一行数据的时候,如果是select,会获取读锁,读锁会阻塞写锁,但不会阻塞写锁,当有update或者delete发生的时候,如果已经有select,那么修改行为会等到前面的select执行完之后才执行,而反过来,如果有一行正在被update,那么对这一行所有的select就都会被阻塞,直到这个修改完成提交.
这样一来,很明显有一个问题,就是读会阻塞写,写也会阻塞读,而且单行来看代价小,但如果视线扩展到整个数据库,假设是一个比较繁忙的数据库,这种对某一行的锁,就会带来很糟糕的问题了.
实际上这个的现实世界的实现,就是IBM DB2,以数据库理论来说,DB2实现得更加理论化,但如果有用过DB2的DBA,应该对这个数据库与主流数据库(Oracle,MySQL)的实现不一致深为头疼,而实际上,更头疼的,是IBM DB2的销售人员.
众所周知,Oracle非常早就使用UNDO实现了MVCC,而MVCC最大的的特点,就是读写不再相互阻塞,读不会阻塞写,写也不会阻塞读,Oracle的销售,可以拿着这个特性对DB2有技术上的优势,在很多性能测试中,有好的表现,虽然DB2的失败(无论从任何意义上来说,目前DB2的状态都不能算作成功吧?)有很多原因,市场,社区等等都是因素,但其在技术上的确没有很大的亮点功能,我认为也是占据了很大因素的.
另外说个题外话,undo的主要作用,是当事务回滚的时候,可以直接取到修改前的数据块,这是一个随机读的过程,但DB2的undo日志记录在redo里,事务回滚需要读redo,这个以及db2的锁机制(所有行锁都是内存的数据结构,行锁数量过多的话会升级为表锁),是我早些年对DB2最大的槽点(如果抛开那个巨丑巨丑的数据库图形工具的话).
而PG在面对MySQL的领域,拿着vacuum来面对MySQL的undo实现的话,也难免在这方面有太多被动.
MySQL中的MVCC
mvcc,Multiversion Concurrency Control,多版本并发控制机制,本身上是一个指导性的概念,本身的指导思想是这样的:与其锁定数据行,不如让写入去写这一行新的版本,而需要读的时候,在新行提交之前(假设隔离级别是Read Commited),直接去读老的行数据,既保证隔离性,也让读写可以不要相互锁定.
当然,对同一行的写,永远是排他性的,写必然会阻塞写.
mvcc的代表性实现,就是Oracle的undo机制,以及模仿其实现的MySQL InnoDB Undo,这俩的实现基本上类似(但Oracle是堆表(实际上也有索引组织表,但使用不多),InnoDB是索引组织表,细节上的实现还是有很多区别的),我对MySQL比较熟,就以此来简单介绍下InnoDB UNDO的实现.
MySQL中,每个事务都会被分配到一个事务id,这个事务id是全局自增的数字,保证新事务的id必然大于老事务,然后这个id也会作为一个读视图id去用来读取数据(如果是可重复读的隔离级别的话,对于读已提交隔离级别来说,类似的比喻来说,是最新提交的事务id作为读视图的).
每当发生数据写入(delete或者update),InnoDB会做一个操作,就是把老的行做一个删除标记,然后带着当前的事务id插入新行(由于是索引组织表,保证必须在同一个数据块中),这个操作本身,一是会把修改本身写入redo,二是会让这个数据块被记录到undo,而undo表空间的写入,也会生成一个对应的redo,写入到redo,也就是说,每次数据修改,会产生两个redo记录(对于insert来说,由于数据前镜像是空,所以并没有第二个undo对应的redo生成,也就是只产生一个redo记录,需要注意),详细说明可以参考 http://hedengcheng.com/?p=489
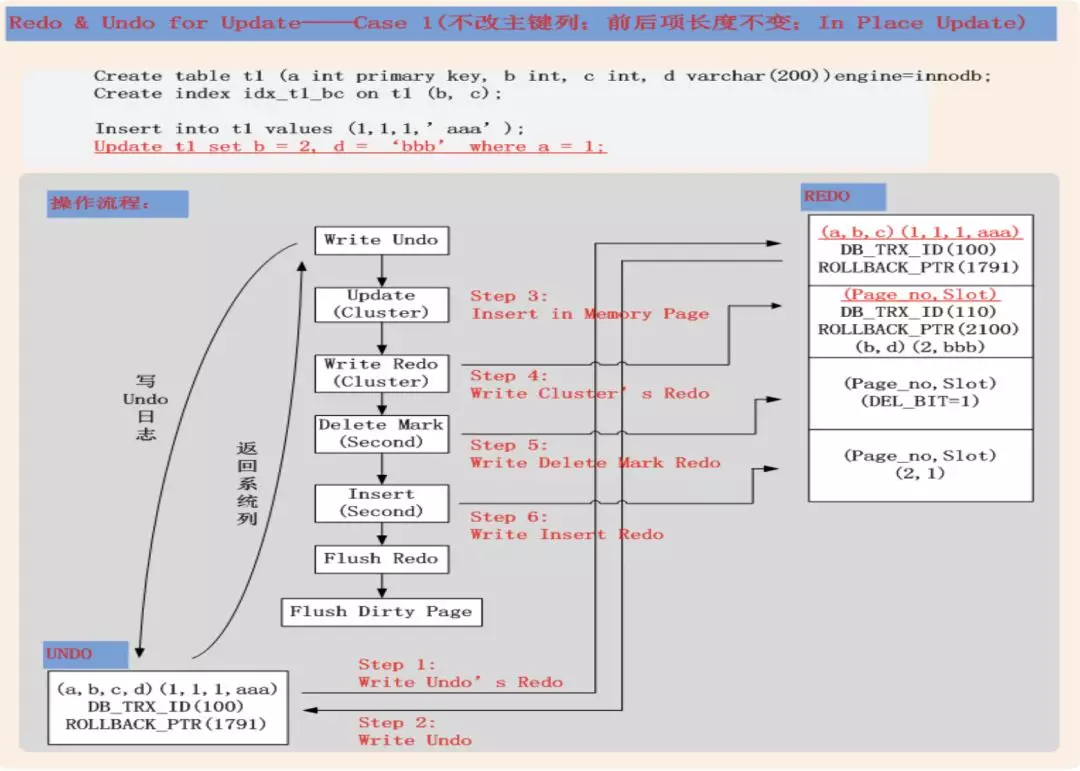
图片来自http://hedengcheng.com
当修改期间,有读行为过来的时候,读的游标,就会直接去读undo中的老数据,而不会去求正在被修改的数据的锁.
而为了实现隔离级别(可重复读级别),事务id的作用在于,如果一个数据块在事务开始后,才被修改并提交了,当游标读取到这里,会扫到当前数据块里面,所有在这期间被修改并提交的行,读取到对应行id小于事务id的数据.
打个比方,一个事务开始之后,sleep了10秒,期间别的三个事务修改并提交了同一行记录,当这个事务在之后读取的时候,会沿着undo一路读取到10秒前的记录.
那老的数据会在什么时候被彻底删除呢?
MySQL中有个purge机制,这个(些)线程的工作就是,对于数据对应的事务id已经比当前数据库最老的事务还小,并且被标记为删除的数据,进行清理.在MySQL高版本(5.6及以上)中,这个工作是多线程并行执行的.
很明显的问题是,就是undo表空间,曾经MySQL的undo表空间是和系统表空间在一起的,如果事务变更密度过大,并且有大事务之类的,会让系统表空间放大非常多,解决办法最直接的,就是搞个从库,把数据全部导出,然后导入到新建的数据库实例,以前坐我旁边的哥们经常干这个事情,是一件漫长而枯燥的事情,所幸,这个问题在MySQL 5.6开始,通过undo表空间独立解决了.
基本上来说,MySQL 5.6以上的版本来说,MySQL DBA不需要在mvcc这个机制上,花费太多精力去管理.
下面,来看看我们的主题,PG中,通过vacuum机制实现的MVCC.
pg中的vacuum
第一个需要说明的是,PG中,是没有UNDO的.
基本实现上,和MySQL是一致的,也是每个update和delete,都会对老行搞一个删除标记,作为"死亡"记录,然后带着当前的事务id写入对应的行,这个过程中,对数据块的修改会记录为redo.
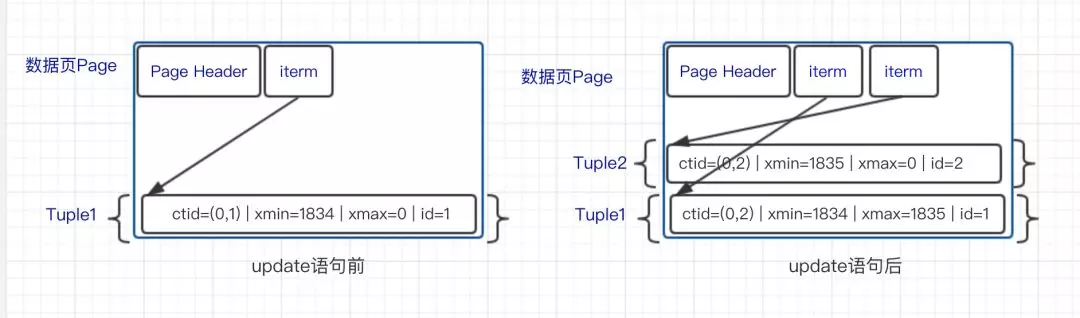
图片来着阿里内核月报
是不是看着很清爽?
曾经我也认为的确很清爽,透露着学院派的威严,until THE TIME COME.
在MySQL中,曾经提到过MySQL为了清理旧数据,引入了purge这个东西,而在PG中,对应的就是vacuum,主要作用是,回收已经不需要的记录占据的空间.这点上来说,并没有什么问题.
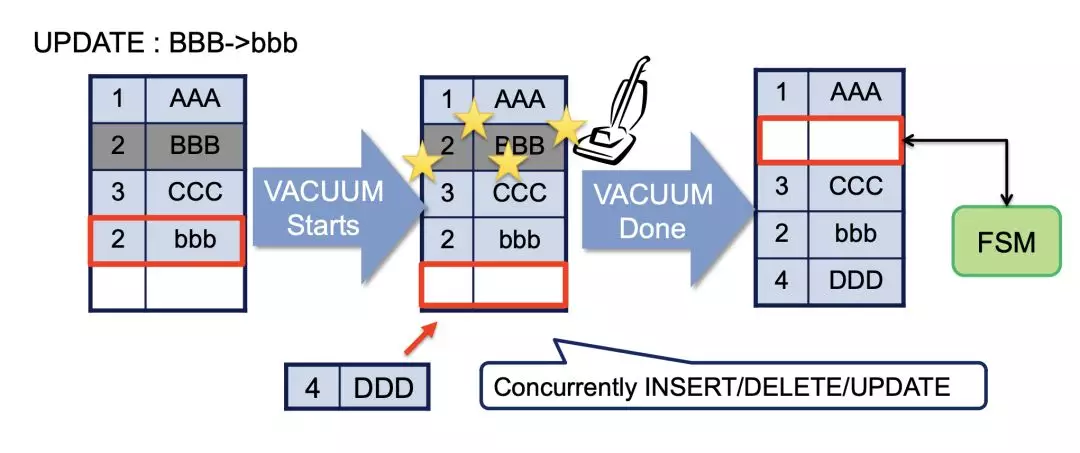
图片来自 Masahiko Sawada of NTT
但是这个实现本身,远远比MySQL来得"痛".
目前的问题
其根本原因,在于事务id的实现.在2018年底,除了很老的windows xp机器之外,我们应该都很少听说哪里还在用32位的操作系统了,但在PG中,由于种种历史原因,其事务id,是32位的数字,而作为对比,MySQL是64位的数字.
让我们做一个简单的算术:
2**32/24/3600/1000=49
简单概括下,如果是一个每秒钟一千个事务的数据库,不到50天就可以耗光事务id,对于比较繁忙的库,比如平均每秒钟1w事务来说,4天就可以耗光.事实上,PG的最新事务和最老事务的差不能超过2**31也就是20亿,这个时间范围还需要减半.
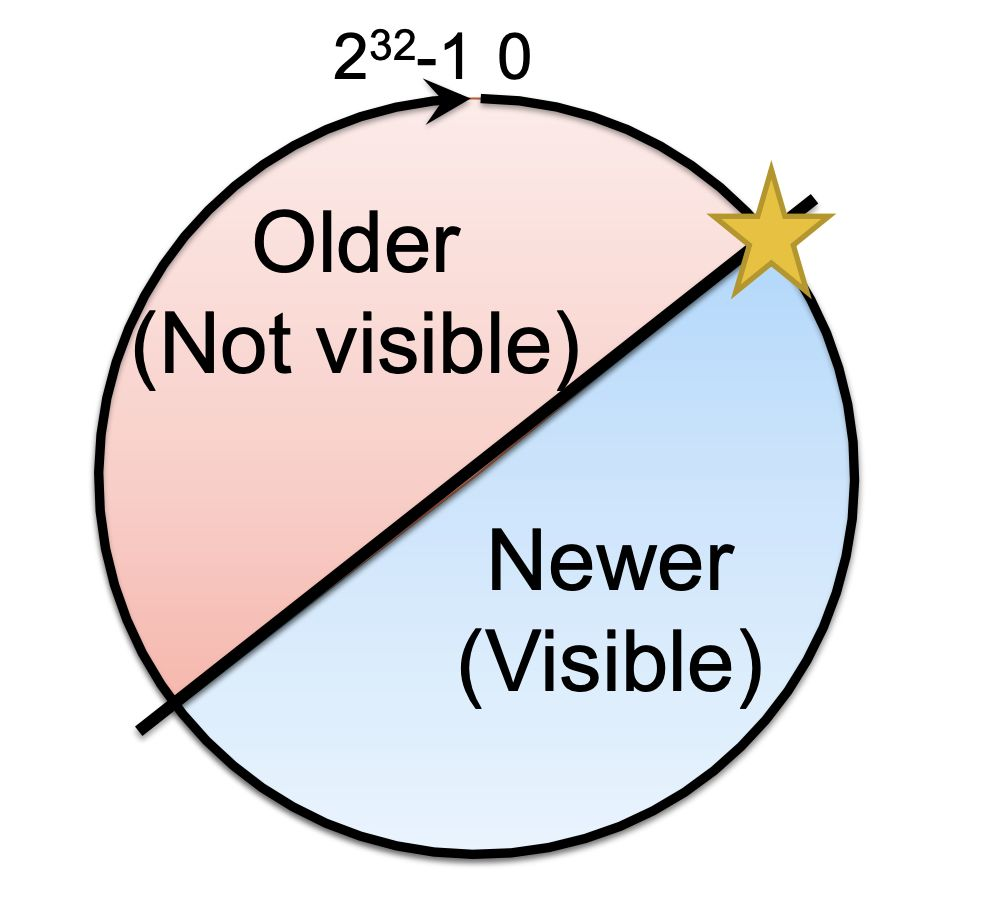
图片来自 Masahiko Sawada of NTT
这种情况下,PG是怎么解决这个问题的么?
首先,事务id得能续上,pg采用的方式是,如果到达限制,则从头开始继续算数字,参数autovacuum_freeze_max_age的默认值是200,000,000(2亿),按照1wqps计算,十几个小时就会耗光,当到达这个限制之后,事务id就会从3开始重新计数(9.4之前,现在已经变成比特位标记了).
这么处理之后,就不能单纯通过比较数据的事务id大小区分可见性了(重置id之后的事务id必然小于重置前),PG在这里,引入了名为"冻结"的概念:当重置的时候,会对当前所有数据表的行进行一遍冻结标,设置其为可以对任意事务可见.这样,重置事务id之后,如果新的事务访问到这个表,就直接可以访问到所有需要的数据了.
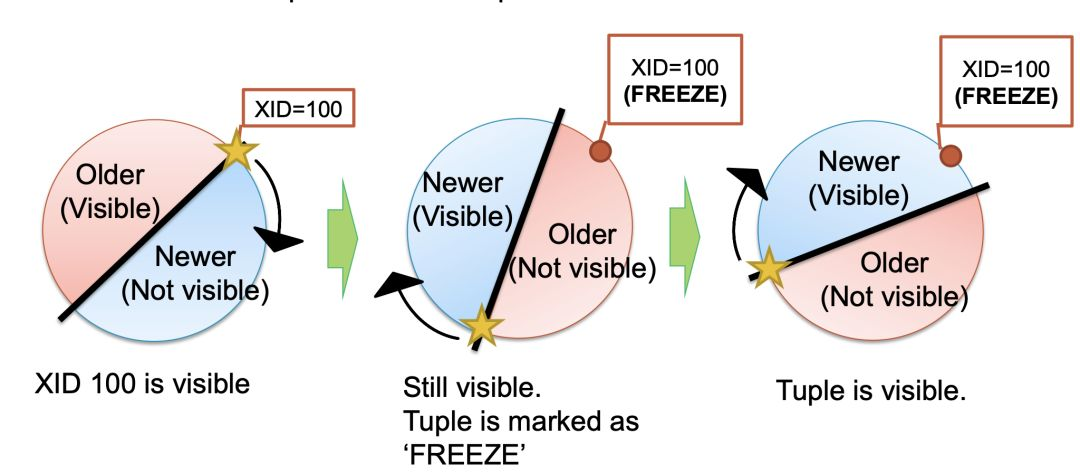
图片来自 Masahiko Sawada of NTT
但是,这么做,很明显会有的问题是,冻结这个操作,必然会有非常大的IO消耗以及cpu消耗(所有表的所有行读一遍,重置标记)无从避免.
实际上,这里隐藏的一个很大的pg危机是,如果冻结操作很慢(比如系统资源不足),导致事务id耗净,最终的结果就是,数据库拒绝所有事务的执行,直到冻结操作结束.
我喜欢称这个机制为"冻结炸弹",业务约繁忙的库,越容易触发----如果缺乏dba管理的话.这一点上的优化,到PG 9.6才终于走出第一步,就是对已经全部是"冻结"的行的数据块,不再进行冻结处理.
而PG另外一个问题,就是垃圾回收这个本职了.到目前为止,pg官方版本在单表上只能串行地vacuum,对超大的单表处理时候,会有非常漫长的处理时间.并且,期间的IO消耗以及cpu消耗,会极大地影响到所在的服务器的性能.
相对来说,由于有超长时间事务,导致的表空间膨胀的问题,就没有那么致命了.pg官方也好,社区也好,都有通过触发器或者redo日志进行在线表重做的工具,很大程度上可以处理偶发大事务导致的单表过大问题.
除此之外,出于能者多劳的考虑,并且"反正都需要扫描一遍表",包括表的统计数据分析,也由vacuum进程代劳了,这点看着很是别扭.
目前的解决方案
在PG的各种技术讨论中,vacuum永远是主要话题之一,围绕如何对数据库,表进行合适的vacuum策略,有非常多的讨论与想法,我就已知的方法进行了总结,其中vacuum本身与vacuum冻结分开讨论的.
vacuum自动策略
PG自身,对vacuum有一套默认的调度策略,主要参数表达如下:
autovacuum=on 默认打开自动垃圾回收
log_autovacuum_min_duration 默认-1,设置为0会记录所有vacuum行为,大于0的话,记录运行超过这个时间的vacuum,单位毫秒
autovacuum_max_workers vacuum同时运行的进程数量默认3
autovacuum_naptime vacuum每次运行的时间间隔,默认为1分钟
autovacuum_vacuum_threshold autovacuum_vacuum_scale_factor 默认50,0.2,只有表内行数据update/delete超过autovacuum_vacuum_threshold autovacuum_vacuum_scale_factor*table row num之后,才会触发vacuum
autovacuum_analyze_threshold autovacuum_analyze_scale_factor 默认50,0.1,数据修改量超过 autovacuum_analyze_threshold+autovacuum_analyze_scale_factor*table row num 默之后,才会触发vacuum的表分析
autovacuum_freeze_max_age autovacuum_multixact_freeze_max_age触发强制freeze的事务时间点 默认2亿与4亿 题外说一下,对于数据库里面的表,不会等到到达这个限制之后才去freeze,默认情况下,在autovacuum_freeze_max_age*0.95的事务数量时候,就会开始冻结操作,也可以通过vacuum_freeze_table_age(表级别粒度)参数控制
vacuum_freeze_min_age参数,如果表的这个参数设置了,每次vacuum时候,行事务id大于这个数字的时候,都会被设置freeze
autovacuum_vacuum_cost_limit 与autovacuum_vacuum_cost_delay 当vacuum操作的cost超过limit,则把vacuum延后指定的时间.cost来源是vacuum_cost_limit参数默认200,
人工策略
来自@德哥博客的建议,主要有三个:
1 是对表进行分区,每个表不大于32GB,降低freeze的时间以及IO代价
2 是对不同的表,设置不同的freeze时间,alter table t set (autovacuum_freeze_max_age=xxxx),比如autovacuum_freeze_max_age为5亿,表1设置为2.1亿,表2设置为2.2亿,以此类推.
3 人工在业务低峰调度.最直觉的办法,就是在业务低峰搞vacuum.结合vacuum_freeze_min_age参数,让表freeze更加灵活.
以下的人工策略讨论,就是以人工调度为基础,讨论vacuum的监控以及治理方式,主要参考平安的PG治理策略,详细情况请参考原始ppt.
1 监控长事务 pg_stat_activity 表的xact_start列就是当前活动事务的开始时间,比较就可以获取到运行时间过长的事务
2 使用pg_squeeze工具执行空间回收的任务,pg_squeeze是基于pg逻辑复制实现的在线处理工具,实现原理实际上是创建新表,然后使用新表的文件替代原先表文件的方式,这种方式一来不访问原先的表,二来不需要触发器或者长时间的排他过程锁,是非常好用的工具.
在具体的流程上,平安的自动化vacuum调度流程,可以说是非常完备:
其主要分为,策略制定,并行调度,调度报表三部分.
策略上,区分发版日(应用程序变更日,由于应用程序变更可能对数据库变化比较敏感,单独处理)与日常日,周末.
首先,需要满足table age已经大于设定的min_age,并且"死亡"数据数量大于指定比例两个条件,发版日的时候,只处理尺寸小于指定大小的数据表,而在日常,则处理尺寸大于指定大小的数据表,周末的时候,则不进行单独的判断.
在调度的时候,对于连续vacuum失败进行报告.
在按照优先级,大小,最后一次vacuum排序之后,进入调度队列,调度队列中,检查cpu,内存资源是否足够(这里个人存疑的问题是,为什么不去检查IO状况),检查cgroup的资源是否充足,资源条件满足之后,才去调度vacuum,如果调度时候,发现已经超过指定的时间区间,则调度就不会继续进行,而是退出过程了.
这一套策略,在保障数据库运行稳定,数据库变更对业务影响的前提下,做到了很好的平衡.
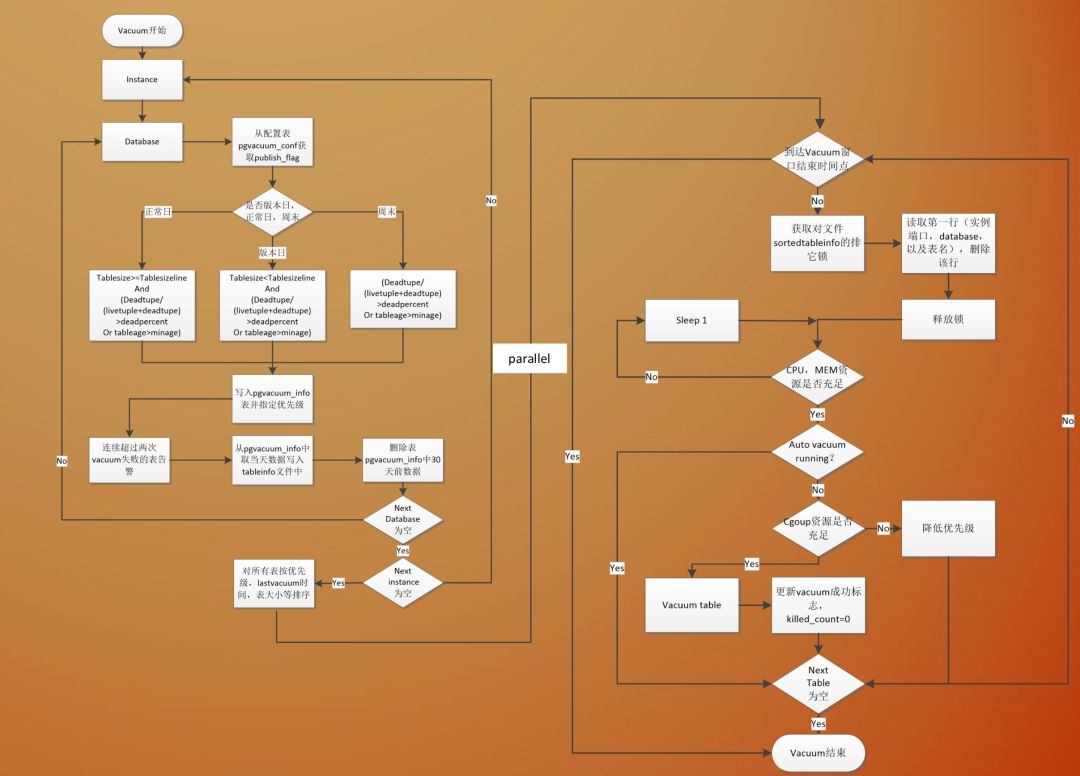
配图来着平安pg使用的ppt
未来的解决方案
人工策略终究是人工策略,无论如何,对于DBA能力没有那么强,自动化能力不足的团队,在使用PG的时候,vacuum造成的困扰必然是个少不了的问题,而要从本质上解决这个问题,是需要官方来进行发行版的版本增强,而非依赖外部工具修修补补.
以下三个,是从pg官方的讨论中,我认为会对这一系列问题有所优化,或者从根本上解决问题的方式,但就目前来看,还仅仅只是展望,离实际能用上,还是有较长的时间的,这个时候,就应该是PG的定制化发威的时候了,国内对PG的定制化,总是免不了纠结于Oracle兼容,以有穷应无穷,而对PG本质性的问题解决上,说实话,并没有看到多少努力,期望以后在这些事情上,可以见到国内的力量.
undo by enterprisedb
enterprisedb是目前PG服务公司里面,名头最大的,也是国内普遍使用的postgresql商业版的edb提供者,今年开始推进其存储格式zheap加入到postgresql社区版本,其带来的特性之一,就是对undo表空间的支持.
而其最正当的理由,就是:一个已经足够大的表,如果其实际大小是"本来应该的大小"的两倍,那vacuum的代价也是两倍了.
我简述一下其实现模式(实际上zheap是一整套存储引擎,我这里仅提取出来undo与vacuum相关的内容):
-
预分配一组独立的顺序数字编号文件(每个1MB)作为undo文件,并且是从buffer pool过来的随机访问,使用上作为表空间访问,而非独立的缓冲区,其变更记录也一样会写入redo.
-
undo记录逐条记录到undo中,当一个undo上最大的事务id已经小于当前数据库最小事务id了,这个文件就可以被回收掉
-
undo记录逐条记录到undo中,当一个undo上最大的事务id已经小于当前数据库最小事务id了,这个文件就可以被回收掉
-
undo的处理本身,由单独的undo进程操作,其包括undo文件清理,以及事务的回滚处理.
-
数据的修改为原地修改,老数据写入undo,读取的时候,沿着修改指针去读,不需要重置事务id(vacuum冻结)
-
老数据清理已经被undo处理了,因此vacuum整个机制就可以去掉了.
-
包括临时表,无日志表在内都会支持.
但zheap重新组织了数据块结构,这样的话,必然会是一个全部替换升级的大方案,代码合并也好,替换也罢,都不是短时间可以解决的事情,但目前这个事情上,看着还是有非常多人感兴趣并且在讨论的.
64bit tx id by postgrespro
https://www.postgresql.org/message-id/flat/DA1E65A4-7C5A-461D-B211-2AD5F9A6F2FD%40gmail.com
这个最早来源,是一个社区的讨论邮件,而在pg的第三方发行版postgrespro中,这个功能早已实现,其作者就此从发行版中,提取出来整个补丁.
实际上如果不考虑vacuum冻结本身,vacuum本身,最多也就造成数据文件膨胀,而不会"在某个时间点数据库不可访问",这个补丁就是基于这种考虑处理的,但事务id在数据库中用处何其多,因此代码补丁是个相当庞大的玩意,主要是修改事务相关的内存结构,数据块的读写部分等一堆地方.
虽然最直接的想法,是把目前数据块行格式中的xid直接从32位数字转为64位数字,postgrespro就是这么干的,甚至给出了一个数据块转化的工具.邮件列表的讨论中,也有提到采用一些变种,比如偏移量等,避免整个数据块的重构,或者干脆就是从32位取偏移量.
但这个补丁的最终的结果是,2017-06-05 被提出来,2017-06-22给出第一个补丁, 2018-03-01 经历过最后的讨论之后,就此搁置.
并行块级别vacuum
https://commitfest.postgresql.org/13/954/
这个补丁比较简单,概括来说,就是vacuum目前只能在单表上串行执行,但实际上vacuum的机制本身,并不是非得在单表上执行,无论是扫描表,还是对某个块内"死"行的清理,都是可以并行化执行的.
作者最初的想法,是从B树出发,分区并行扫描,后来在讨论中,变成从表上的多个索引出发并行,单个索引上还是单进程(如果表上只有一个索引,那还是单进程vacuum)
最终的实现是:
首先并行扫描一遍表,取出来需要处理的行号,然后按照物理顺序排序,多个进程在这个排好序的列表上在块级别并行扫描,而对于索引,则是每个索引单独一个进程处理其的vacuum.
性能等多方面都达到了预期,但是,最终由于测试不足,遇到了问题,最终还是没有合并入官方分支.
总结
以上,就是我对pg的vacuum的目前状况以及相关资料材料的整理,希望对有志于此的人有所帮助.
