




Orchestrator功能强大,能适应多种恢复场景,通过调用WEB接口和命令orchestrator-client能完成非常多的功能。
本文介绍了Orchestrator的几种应用场景,以及云和恩墨自主研发的MySQL整体解决方案MyData是如何基于Orchestrator进行优化,实现数据库高可用的。
Orchestrator简介
Orchestrator是近年出现的基于GO语言编写的MySQL HA开源管理工具,相较与传统的HA(MHA、MMM等)管理工具,Orchestrator提供了展示MySQL复制拓扑关系及状态的Web界面,支持在Web界面管理/变更数据库复制管理,同时Orchestrator提供了丰富的命令行指令和WEB接口,并支持多节点集群方式部署。
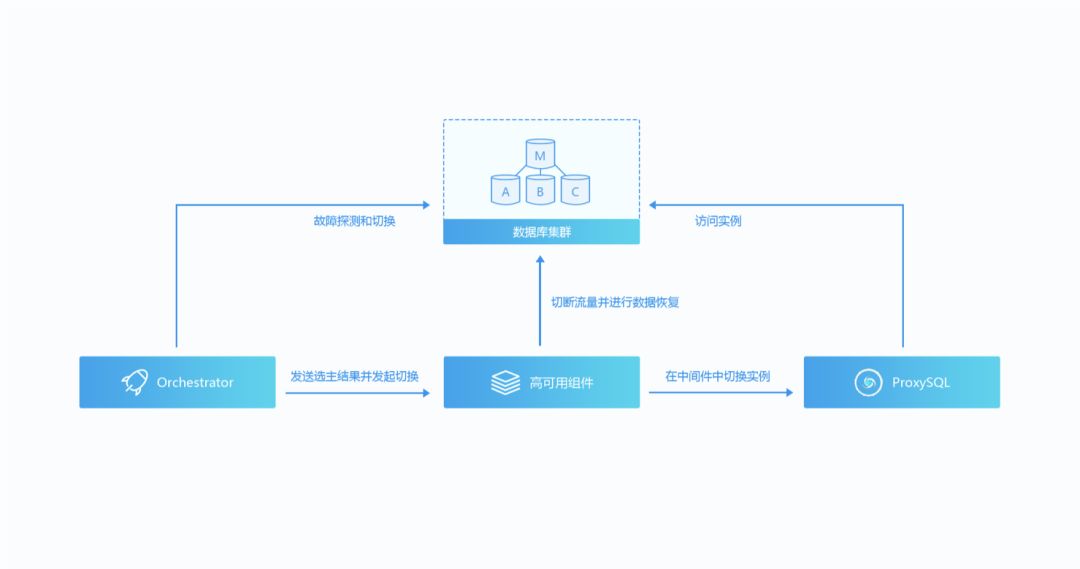
MyData使用Orchestrator实现数据库高可用
Orchestrator的特点
支持自动发现MySQL的复制拓扑图
支持通过图形界面操作或调用接口变更复制关系
支持自动检测主库异常:主库故障检测,Orchestrator会同时连接主库和从库,当管理节点检测到主库异常时,会通过从库再次确认主库是否异常,这样规避了一些对主库故障错误判断的场景
支持多种类型恢复:自动恢复、优雅的恢复、手动恢复、手动强制恢复
支持中继主库(DeadIntermediateMaster)和主库恢复
提供多个Hooks接口优化恢复流程
本身支持多节点,通过raft协议保证集群高可用
Orchestrator的安装配置
1. 配置yum源
curl -s https://packagecloud.io/install/repositories/github/orchestrator/script.rpm.sh|bashyum install -y epel-release
2. 安装orchestrator(3.0.14)
yum install -y orchestrator
3. 环境配置
MySQL(版本5.7.24),共三个节点主节点,192.168.11.175:22222从节点,192.168.11.176:22222从节点,192.168.11.177:22222orchestrator管理节点:192.168.11.179:3000
4. 安装配置orchestrator 使用的MySQL数据库
CREATE DATABASE IF NOT EXISTS orchestrator;CREATE USER 'orchestrator'@'%' IDENTIFIED BY 'orch_backend_password';GRANT ALL PRIVILEGES ON 'orchestrator'.* TO 'orchestrator'@'%';
5. 被管理数据库配置要求(MySQL5.7+)
gtid-mode = ONenforce_gtid_consistency = 1binlog_format = ROWlog-bin =/data/mysql/data/mysql-binslave_preserve_commit_order=1report_host = 192.168.11.175master-info-repository = TABLElog_slave_updates = 1
6. MyDATA优化
对于数据库集群需要一些特定的配置,否则orchestrator不能发现集群或者对管理的集群不能正常完成故障切换(例如未配置log_slave_updates = 1或者多线程未配置slave_preserve_commit_order=1等),MyData在这里做了一些优化,根据orchestrator的配置检查数据库集群的配置,对于预期不能正常切换的数据库集群打印出告警信息,用户可以根据告警信息修改数据库集群配置;
7. 配置orchestrator监控和切换用户:
CREATE USER 'orchestrator'@'%' IDENTIFIED BY 'orch_topology_password';GRANT SUPER, PROCESS, REPLICATION SLAVE, RELOAD ON *.* TO 'orchestrator'@'%';GRANT SELECT ON mysql.slave_master_info TO 'orchestrator'@'%';GRANT SELECT ON mysql.mydata_cluster TO 'orchestrator'@'%';
8. 配置集群别名
use mysql;CREATE TABLE `mydata_cluster` (`anchor` tinyint(4) NOT NULL,`cluster_name` varchar(128) NOT NULL DEFAULT '',`cluster_domain` varchar(128) NOT NULL DEFAULT '',PRIMARY KEY (`anchor`));replace into mydata_cluster values (1,'cluster01','test');
9. 修改orchestrator配置(/usr/local/orchestrator/orchestrator.conf.json)
{"Debug": true,"EnableSyslog": false,"ListenAddress": ":3000","MySQLTopologyUser": "orchestrator","MySQLTopologyPassword": "orch_topology_password","MySQLTopologyCredentialsConfigFile": "","MySQLTopologySSLPrivateKeyFile": "","MySQLTopologySSLCertFile": "","MySQLTopologySSLCAFile": "","MySQLTopologySSLSkipVerify": true,"MySQLTopologyUseMutualTLS": false,"MySQLOrchestratorHost": "192.168.11.179","MySQLOrchestratorPort": 3306,"MySQLOrchestratorDatabase": "orchestrator","MySQLOrchestratorUser": "orchestrator","MySQLOrchestratorPassword": "orch_backend_password","MySQLConnectionLifetimeSeconds": 10,"MySQLOrchestratorCredentialsConfigFile": "","MySQLOrchestratorSSLPrivateKeyFile": "","MySQLOrchestratorSSLCertFile": "","MySQLOrchestratorSSLCAFile": "","MySQLOrchestratorSSLSkipVerify": true,"MySQLOrchestratorUseMutualTLS": false,"MySQLConnectTimeoutSeconds": 1,"DefaultInstancePort": 3306,"DiscoverByShowSlaveHosts": true,"InstancePollSeconds": 5,"UnseenInstanceForgetHours": 240,"SnapshotTopologiesIntervalHours": 0,"InstanceBulkOperationsWaitTimeoutSeconds": 10,"HostnameResolveMethod": "default","MySQLHostnameResolveMethod": "@@report_host","SkipBinlogServerUnresolveCheck": true,"ExpiryHostnameResolvesMinutes": 60,"RejectHostnameResolvePattern": "","ReasonableReplicationLagSeconds": 10,"ProblemIgnoreHostnameFilters": [],"VerifyReplicationFilters": false,"ReasonableMaintenanceReplicationLagSeconds": 20,"CandidateInstanceExpireMinutes": 60,"AuditLogFile": "","AuditToSyslog": false,"RemoveTextFromHostnameDisplay": ".mydomain.com:3306","ReadOnly": false,"AuthenticationMethod": "","HTTPAuthUser": "","HTTPAuthPassword": "","AuthUserHeader": "","UseSuperReadOnly": true,"FailMasterPromotionIfSQLThreadNotUpToDate": false,"PowerAuthUsers": ["*"],"ClusterNameToAlias": {"192.168.11.179": "test suite"},"SlaveLagQuery": "","DetectClusterAliasQuery": "select ifnull(max(cluster_name),concat(ifnull(@@report_host,@@hostname),':',@@report_port)) from mysql.mydata_cluster where anchor=1","DetectClusterDomainQuery": "","DetectInstanceAliasQuery": "","DetectPromotionRuleQuery": "","DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com","PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com","PromotionIgnoreHostnameFilters": [],"DetectSemiSyncEnforcedQuery": "","ServeAgentsHttp": false,"AgentsServerPort": ":3001","AgentsUseSSL": false,"AgentsUseMutualTLS": false,"AgentSSLSkipVerify": false,"AgentSSLPrivateKeyFile": "","AgentSSLCertFile": "","AgentSSLCAFile": "","AgentSSLValidOUs": [],"UseSSL": false,"UseMutualTLS": false,"SSLSkipVerify": false,"SSLPrivateKeyFile": "","SSLCertFile": "","SSLCAFile": "","SSLValidOUs": [],"URLPrefix": "","StatusEndpoint": "/api/status","StatusSimpleHealth": true,"StatusOUVerify": false,"AgentPollMinutes": 60,"UnseenAgentForgetHours": 6,"StaleSeedFailMinutes": 60,"SeedAcceptableBytesDiff": 8192,"PseudoGTIDPattern": "","PseudoGTIDPatternIsFixedSubstring": false,"PseudoGTIDMonotonicHint": "asc:","DetectPseudoGTIDQuery": "","BinlogEventsChunkSize": 10000,"SkipBinlogEventsContaining": [],"ReduceReplicationAnalysisCount": true,"FailureDetectionPeriodBlockMinutes": 60,"RecoveryPeriodBlockSeconds": 3600,"RecoveryIgnoreHostnameFilters": [],"RecoverMasterClusterFilters": ["*"],"RecoverIntermediateMasterClusterFilters": ["*"],"OnFailureDetectionProcesses": ["echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> tmp/recovery.log"],"PreGracefulTakeoverProcesses": ["echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> tmp/recovery.log"],"PreFailoverProcesses": ["echo 'PreFailoverProcesses' >> tmp/recovery.log"],"PostFailoverProcesses": [],"PostUnsuccessfulFailoverProcesses": [],"PostMasterFailoverProcesses": ["echo 'PostMasterFailoverProcesses' >> tmp/recovery.log"],"PostIntermediateMasterFailoverProcesses": ["echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> tmp/recovery.log"],"PostGracefulTakeoverProcesses": ["echo 'Planned takeover complete' >> tmp/recovery.log"],"CoMasterRecoveryMustPromoteOtherCoMaster": true,"DetachLostSlavesAfterMasterFailover": true,"ApplyMySQLPromotionAfterMasterFailover": true,"MasterFailoverDetachSlaveMasterHost": false,"MasterFailoverLostInstancesDowntimeMinutes": 0,"PostponeSlaveRecoveryOnLagMinutes": 0,"OSCIgnoreHostnameFilters": [],"GraphiteAddr": "","GraphitePath": "","GraphiteConvertHostnameDotsToUnderscores": true,"ConsulAddress": "","ConsulAclToken": ""}
10. 配置完成
启动orchestrator:/etc/init.d/orchestrator start
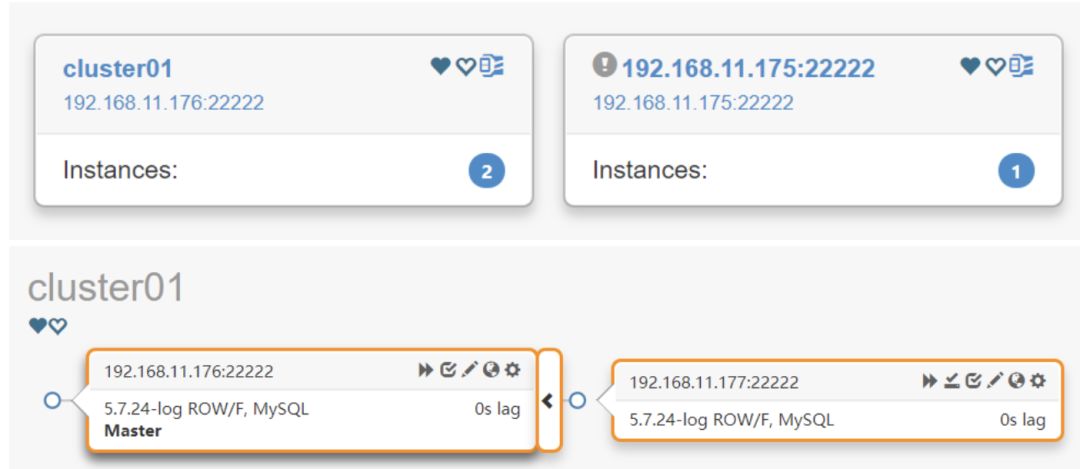
访问页面,发现新实例:http://192.168.11.179:3000
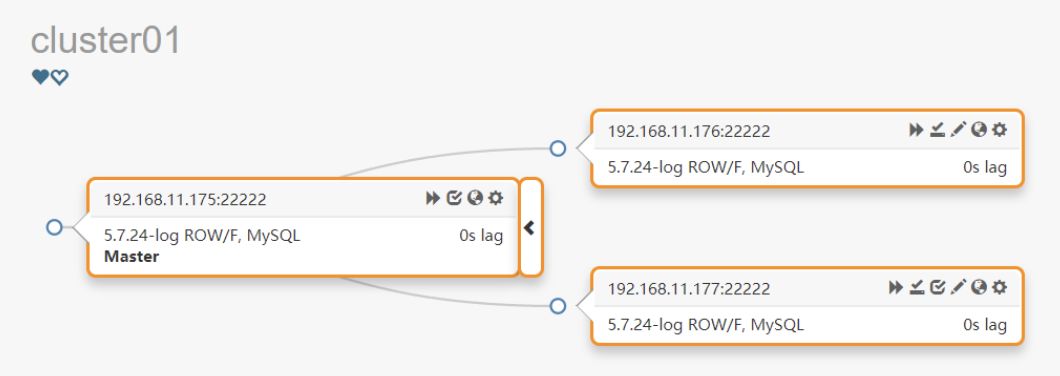
实例拓扑图:
Orchestrator自动恢复
故障检测
Orchestrator在集群的主库和所有从库各启动三个线程,每隔InstancePollSeconds重建连接,监控主库和所有从库复制是否正常;
当检测到主库故障时,会通过从库的连接查询复制关系是否正常,如果主库故障且所有从库复制关系异常(不能连接到从库或IO Thread异常),判定主库故障(二次确认)
调用OnFailureDetectionProcesses钩子函数
配置的MySQLConnectionLifetimeSeconds不小于InstancePollSeconds,避免间隔时间内数据库没有线程监控;
故障自动恢复
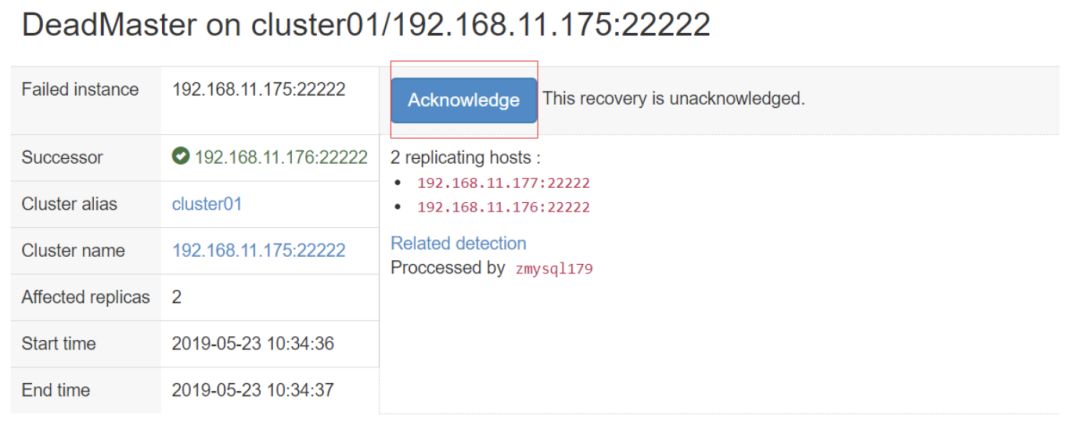
当检测到主库故障(DeadMaster)后,根据RecoveryPeriodBlockSeconds设置集群故障ack时间间隔,调用PreFailoverProcesses函数,如果调用成功(exit status 0),继续执行否则退出故障切换;
注意:当集群再次发生故障后,会检查上次故障和当前故障的时间间隔,如果小于设置RecoveryPeriodBlockSeconds值,需要确认上次故障切换,否则会阻塞当前的故障切换;orchestrator-client -c ack-cluster-recoveries -a cluster01 -r 'ack cluster01'或者通过WEB界面确认恢复:
检查可连接从库的优先级(prefer、neutral、prefer_not、must_not)、downtime状态、比较执行到的relay log位置,选举新主
重新配置复制关系,其他从库执行ChangeMasterTo命令到新主
提升新主
原主begin-downtime(MasterFailoverLostInstancesDowntimeMinutes),检查是否设置FailMasterPromotionIfSQLThreadNotUpToDate:
如果设置为0则立即执行故障切换,不需要检查新主是否应用完成relay log,在选举的新主执行stop slave,RESET SLAVE ALL,read-only=0;这种场景下,可能则会造成数据丢失;
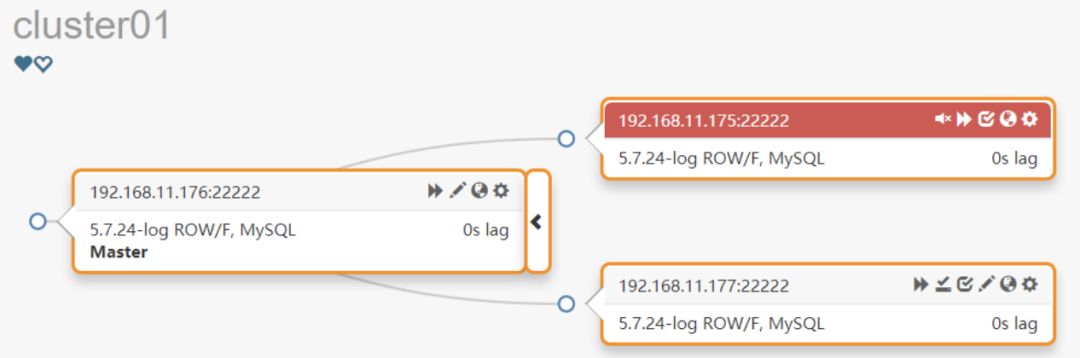
如果设置为1则检查选举的新主是否应用完成relay log,如果未应用完成则故障切换失败退出(如果DelayMasterPromotionIfSQLThreadNotUpToDate设置为true,会等待提升的新主应用完成relay log),这种场景下不会有数据丢失但是切换流程进行到一半退出,拓扑图如下:

尝试故障主库的维护(RecoverDeadMaster),read-only=1
调用PostMasterFailoverProcesses钩子函数
更新集群别名等操作
切换成功后实例拓扑图
MyData优化
由于原生Orchestrator在故障切换时存在的缺陷,MyData在这里做了优化,使其支持了对于其管理的不同集群实例支持不同的切换方式,并新增参数丰富切换流程
failoverSlaveLagThreshold:主库故障后首先检查所有从库的延迟,如果延迟均大于配置值,则不会切换
failoverWaitSlaveApplyTimeout:配置时间内,循环检测从库relay log应用是否完成,如果relay log应用完成,则立即切换,否则等待超时后再立即执行切换
slaveApplyOptimize:配置为true,循环检测从库relay log应用是否完成时,会检查并修改所有从库的配置参数(sync_binlog = 0、innodb_flush_log_at_trx_commit = 0、slave_parallel_workers = 16、long_query_time=100等),当应用relay log完成后再还原参数配置
Orchestrator优雅恢复
通过执行命令或调用接口对MySQL数据库复制关系调整
curl -s http://192.168.11.179:3000/api/graceful-master-takeover/cluster01/192.168.11.176/22222或到管理节点192.168.11.179执行:
orchestrator-client -c graceful-master-takeover -alias cluster01 -s 192.168.11.176: 22222切换流程:
首先将其他从库切换到指定主库,Stopped replication,ChangeMasterTo,Started replication
调用钩子函数PreGracefulTakeoverProcesses,设置原主read_only停止写入,同样只有返回0才能正常切换
循环获取集群实例信息,主要目的是检查新主是否应用完成relay log
调用钩子函数OnFailureDetectionProcesses
调用钩子函数PreFailoverProcesses,同样返回非0退出切换
在指定的新主执行STOP SLAVE, RESET SLAVE ALL, read-only=0
调用PostMasterFailoverProcesses
更新集群别名,在原主执行read-only=1
原主执行ChangeMasterTo,将原主库做为新主从库,注意这里没有start slave
调用钩子函数PostGracefulTakeoverProcesses
总结
Orchestrator功能强大,能适应多种恢复场景,通过调用WEB接口和命令orchestrator-client能完成非常多的功能,这里仅简单介绍了常用的两种场景;同时也可以看到其中部分功能需要修改完善,大家在使用过程中多关注其在Github上的更新。
云和恩墨MySQL整体解决方案MyData基于Orchestrator进行了优化,保障了数据库高可用的实现。
关于MyData
MyData是云和恩墨自主研发的,针对MySQL数据库提供高可用、高可靠、高安全性和易于使用的整体解决方案。MyData融合了云和恩墨资深数据库工程师的经验和最佳实践,来帮助客户快速构建高可用的数据库集群环境,保证了MySQL数据库运行环境符合企业级数据库的要求,帮助客户提高快速交付的能力。
云和恩墨对MyData提供专业、灵动的端到端服务,涵盖规划设计、建设实施、运营管理和优化提升四个阶段,为客户构建安全、连续、高效和稳定的数据环境。
MyData目前已经在政府和金融行业拥有多个最佳实践的案例,致力于为企业提供开展开源数据库一体化的解决方案。




